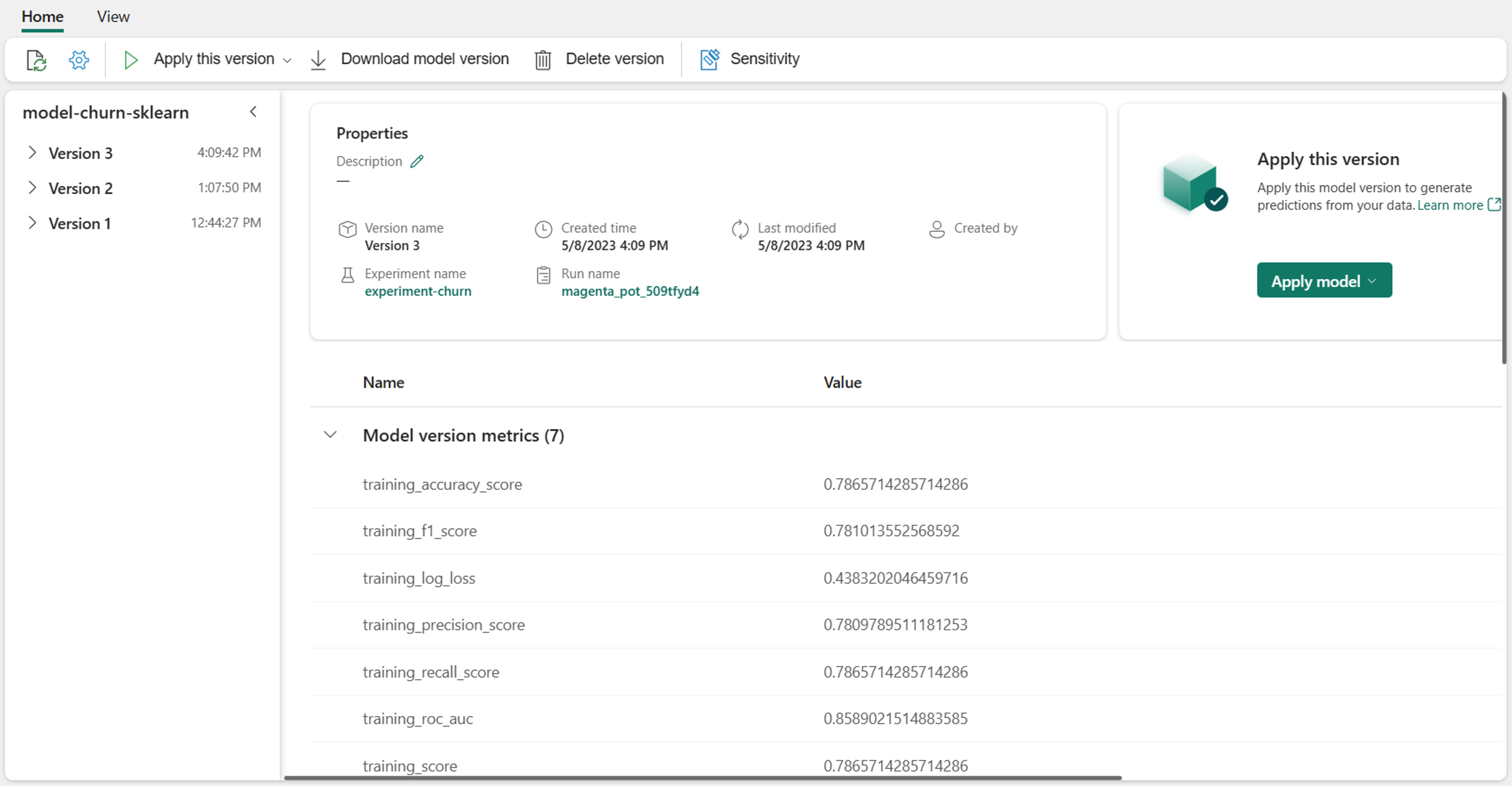
Správa modelů v Microsoft Fabric
Integrace MLflow v Microsoft Fabric usnadňuje sledování a správu modelů strojového učení.
Sledování artefaktů modelu pomocí MLflow
Po vytrénování modelu chcete model použít k bodování a generování nových předpovědí. Pokud chcete model snadno integrovat, musíte model uložit, abyste ho mohli načíst do jiného prostředí. Běžným přístupem je uložení modelu jako souboru pickle, serializovaného objektu.
Poznámka:
Formát uloženého modelu závisí na rozhraní strojového učení, které používáte. Například při trénování modelu hlubokého učení se můžete rozhodnout model uložit pomocí formátu Open Neural Network Exchange (ONNX).
MLflow přidá do výstupu modelu další vrstvu přidáním souboru MLmodel . Soubor MLmodel určuje metadata modelu, například jak a kdy byl model natrénován, a také očekávaný vstup a výstup modelu.
Vysvětlení souboru MLmodel
Při protokolování modelu pomocí MLflow se všechny relevantní prostředky modelu ukládají do model složky se spuštěním experimentu.
Složka model obsahuje soubor MLmodel, jediný zdroj pravdy o tom, jak se má model načíst a využívat.
Soubor MLmodel může zahrnovat:
artifact_path: Během trénování se model do této cesty zaprotokoluje.flavor: Knihovna strojového učení, pomocí které byl model vytvořen.model_uuid: Jedinečný identifikátor registrovaného modelu.run_id: Jedinečný identifikátor spuštění úlohy, během kterého byl model vytvořen.signature: Určuje schéma vstupů a výstupů modelu:inputs: Platný vstup do modelu. Například podmnožina trénovací datové sady.outputs: Platný výstup modelu. Například předpovědi modelu pro vstupní datovou sadu.
Představte si, že jste vytrénovali regresní model pro predikci cukrovky u pacientů, protokolovaný soubor MLmodel může vypadat takto:
artifact_path: model
flavors:
python_function:
env:
conda: conda.yaml
virtualenv: python_env.yaml
loader_module: mlflow.sklearn
model_path: model.pkl
predict_fn: predict
python_version: 3.10.10
sklearn:
code: null
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 1.2.0
mlflow_version: 2.1.1
model_uuid: 8370150f4e07495794c3b80bcaf07e52
run_id: 14cdf02f-119b-4b8d-90f3-044987c29bce
signature:
inputs: '[{"type": "tensor", "tensor-spec": {"dtype": "float64", "shape": [-1, 10]}}]'
outputs: '[{"type": "tensor", "tensor-spec": {"dtype": "float64", "shape": [-1]}}]'
Když se rozhodnete použít funkci automatickéhologování MLflow v Microsoft Fabric, soubor MLmodel se automaticky vytvoří za vás. Pokud chcete změnit soubor a změnit chování modelu během bodování, můžete změnit způsob protokolování souboru MLmodel.
Tip
Přečtěte si další informace o souborech modelů MLflow a o tom, jak přizpůsobit pole.
Správa modelů v Microsoft Fabric
Když během trénování v Microsoft Fabric sledujete model s MLflow, všechny artefakty modelu se uloží do model složky. Složku můžete najít model ve spuštění experimentu:
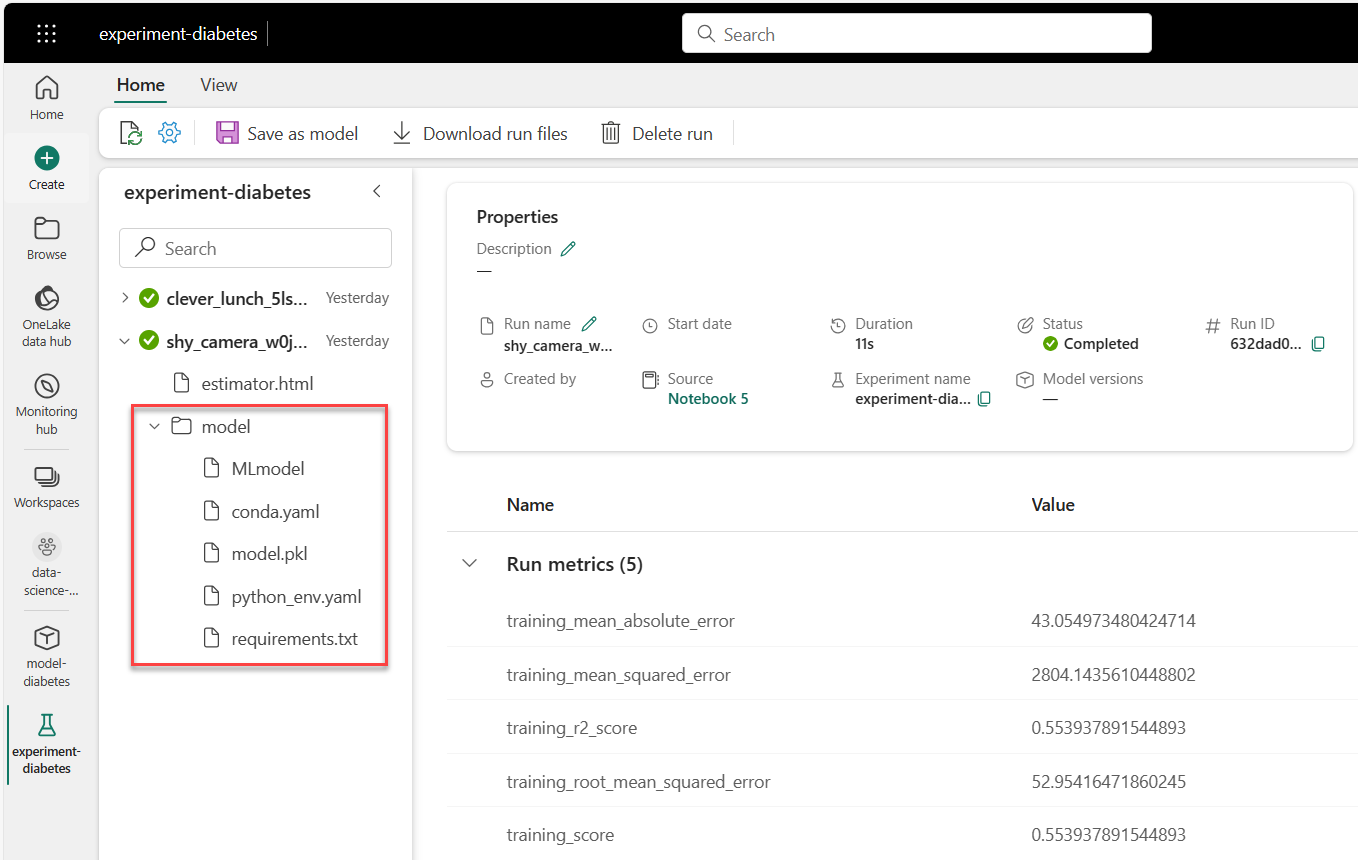
Složka modelu obsahuje:
MLmodel: Obsahuje metadata modelu.conda.yaml: Obsahuje prostředí Anaconda potřebné ke spuštění modelu.model.pkl: Obsahuje natrénovaný model.python_env.yaml: Popisuje prostředí Pythonu potřebné ke spuštění modelu. Odkazuje narequirements.txtsoubor.requirements.txt: Vypíše balíčky Pythonu potřebné ke spuštění modelu.
Všechny tyto artefakty modelu jsou nezbytné, když chcete použít model k vygenerování předpovědí na nových datech.
Uložení modelu do pracovního prostoru
Když zvolíte model, který chcete použít, můžete ho uložit do pracovního prostoru ze spuštění experimentu. Uložením modelu vytvoříte v pracovním prostoru nový model s verzí, který obsahuje všechny artefakty a metadata modelu.
Vyberte spuštění experimentu, které představuje model, který jste natrénovali, a výběrem možnosti Uložit uložte spuštění jako model.
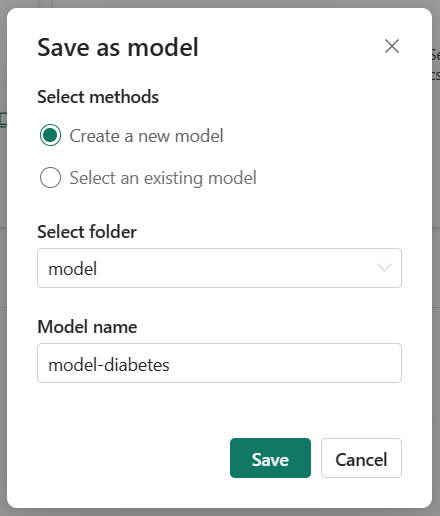
Výběrem existujícího modelu vytvoříte novou verzi modelu pod stejným názvem. Správa verzí modelu umožňuje porovnávat modely, které slouží k podobnému účelu, a potom si můžete vybrat model s nejlepším výkonem pro generování předpovědí.