Normalizace a standardizace
Škálování funkcí je technika, která mění rozsah hodnot, které funkce obsahuje. Díky tomu se modely učí rychleji a robustněji.
Normalizace versus standardizace
Normalizace znamená škálování hodnot tak, aby se všechny vešly do určitého rozsahu, obvykle 0–1. Pokud byste například měli seznam věků lidí, které byly 0, 50 a 100 let, mohli byste je normalizovat vydělením věku 100 tak, aby vaše hodnoty byly 0, 0,5 a 1.
Standardizace je podobná, ale místo toho odečteme střední hodnotu (označovanou také jako průměr) hodnot a vydělíme směrodatnou odchylkou. Pokud nejste obeznámeni se směrodatnou odchylkou, nemusíte se obávat, znamená to, že po standardizaci je naše střední hodnota nula a přibližně 95 % hodnot spadá mezi -2 a 2.
Existují i jiné způsoby, jak škálovat data, ale jejich nuance jsou nad rámec toho, co potřebujeme vědět právě teď. Pojďme se podívat, proč používáme normalizaci nebo standardizaci.
Proč musíme škálovat?
Existuje mnoho důvodů, proč před trénováním normalizovat nebo standardizovat data. Snadněji je pochopíte na příkladu. Řekněme, že chceme vytrénovat model, který bude předpovědět, jestli bude pes úspěšný v práci na sněhu. Naše data se v následujícím grafu zobrazují jako tečky a spojnice trendu, která se snažíme najít, se zobrazuje jako plná čára:
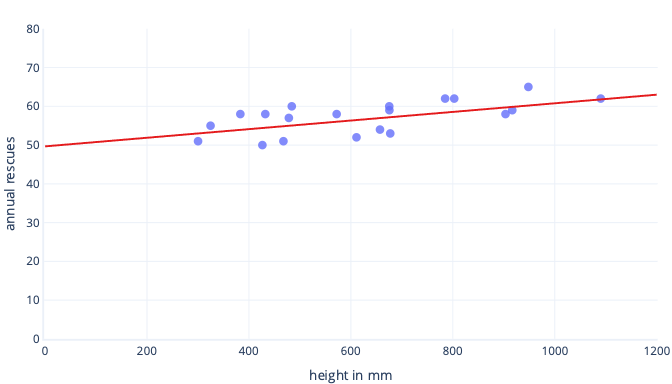
Škálování poskytuje lepší výchozí bod pro výuku.
Optimální čára v předchozím grafu má dva parametry: průsečík, který je 50, přímka v x=0 a sklon, který je 0,01; každý 1000 milimetrů zvyšuje záchranu o 10. Předpokládejme, že začneme trénovat s počátečními odhady 0 pro oba tyto parametry.
Pokud naše iterace trénování mění parametry v průměru přibližně o 0,01 na jednu iteraci, trvá před nalezením průsečíku alespoň 5000 iterací: 50 / 0,01 = 5000 iterací. Standardizace může způsobit, že se tento optimální průsečík blíží nule, což znamená, že ho můžeme najít mnohem rychleji. Pokud například odečteme střední hodnotu z našeho popisku – roční záchrany – a naši vlastnost – výšku , průsečík je -0,5, ne 50, což můžeme najít asi 100krát rychleji.
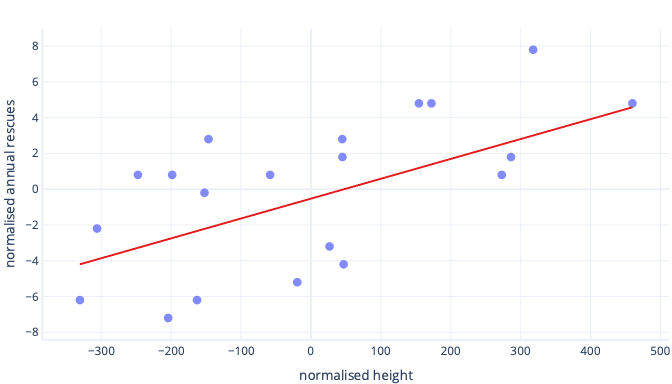
Existují i jiné důvody, proč může být trénování složitých modelů velmi pomalé, když je počáteční odhad daleko od značky, ale řešení je stále stejné: posunuje funkce na něco blíže k počátečnímu odhadu.
Standardizace umožňuje natrénovat parametry stejnou rychlostí.
V našich nově posunovaných datech máme ideální posun -0,5 a ideální sklon 0,01. I když offsetting pomáhá věci urychlit, je stále mnohem pomalejší trénovat posun než trénování sklonu. To může zpomalit věci a učinit trénování nestabilním.
Například naše počáteční odhady posunu a sklonu jsou nulové. Pokud při každé iteraci měníme naše parametry přibližně o 0,1, zjistíme posun rychle, ale bude velmi obtížné najít správný sklon, protože nárůst sklonu bude příliš velký (0 + 0,1 > 0,01) a může přestřelit ideální hodnotu. Úpravy můžeme zmenšit, ale zpomalí se tím, jak dlouho bude trvat nalezení průsečíku.
Co se stane, když škálujeme výšku?
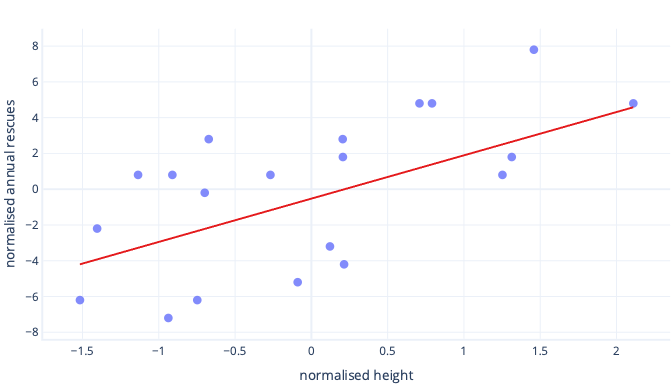
Sklon přímky je nyní 0,5. Věnujte pozornost ose x. Náš optimální průsečík -0,5 a sklon 0,5 jsou stejné měřítko! Nyní je snadné vybrat rozumnou velikost kroku, což je rychlost, jak rychle gradientní sestup aktualizuje parametry.
Škálování pomáhá s více funkcemi
Když pracujeme s více funkcemi, jejich použití v jiném měřítku může způsobit problémy při montáži, podobně jako jsme to právě viděli u příkladů průsečíku a sklonu. Pokud například trénujeme model, který přijímá výšku v mm i hmotnost v tunách metrik, mnoho typů modelů bude mít potíže ocenit důležitost funkce hmotnosti, jednoduše proto, že je vzhledem k vlastnostem výšky tak malá.
Musím vždy škálovat?
Nemusíme vždy škálovat. Některé typy modelů, včetně předchozích modelů s rovnými čarami, se dají přizpůsobit bez iterativního postupu, jako je gradientní sestup, takže jim nevadí, že vlastnosti mají nesprávnou velikost. Jiné modely potřebují škálování, aby bylo dobře natrénování, ale jejich knihovny často provádějí škálování funkcí automaticky.
Obecně řečeno, jedinou skutečnou nevýhodou normalizace nebo standardizace je to, že může ztížit interpretaci našich modelů a že musíme napsat trochu více kódu. Z tohoto důvodu je škálování funkcí standardní součástí vytváření modelů strojového učení.