Úložiště a vývoj založený na kmenech
Mnoho datových vědců preferuje práci s Pythonem nebo R k definování úloh strojového učení. K přípravě dat nebo trénování modelu můžete mít poznámkové bloky Nebo skripty Jupyter.
Práce na všech prostředcích kódu je jednodušší, když používáte správu zdrojového kódu. Správa zdrojového kódu je postup správy kódu a sledování všech změn , které váš tým v kódu provede.
Pokud pracujete s nástroji DevOps, jako je Azure DevOps nebo GitHub, kód se uloží do takzvaného úložiště nebo úložiště.
Repository
Při nastavování architektury MLOps pravděpodobně vytvoří úložiště technik strojového učení. Bez ohledu na to, jestli se rozhodnete používat Azure Repos v Azure DevOps nebo v úložištích GitHubu, obě úložiště Git používají k ukládání kódu.
Obecně existují dva způsoby určení rozsahu úložiště:
- Monorepo: Udržujte všechny úlohy strojového učení ve stejném úložišti.
- Více úložišť: Vytvořte samostatné úložiště pro každý nový projekt strojového učení.
Jaký přístup preferuje váš tým, závisí na tom, kdo by měl získat přístup k jakým prostředkům. Pokud chcete zajistit rychlý přístup ke všem prostředkům kódu, může monorepos lépe vyhovovat požadavkům vašeho týmu. Pokud chcete uživatelům udělit přístup k projektu jenom v případě, že na něm aktivně pracují, může váš tým raději pracovat s několika úložištěmi. Mějte na paměti, že správa řízení přístupu může způsobit větší režii.
Strukturování úložiště
Bez ohledu na přístup, který vezmete, je osvědčeným postupem souhlasit se standardní strukturou složek nejvyšší úrovně pro vaše projekty. Můžete mít například ve všech svých úložišťch následující složky:
.cloud: obsahuje kód specifický pro cloud, jako jsou šablony pro vytvoření pracovního prostoru Azure Machine Learning..ad/.github: Obsahuje artefakty Azure DevOps nebo GitHubu, jako jsou kanály YAML pro automatizaci pracovních postupů.src: obsahuje jakýkoli kód (skripty Pythonu nebo R) používané pro úlohy strojového učení, jako je předzpracování dat nebo trénování modelu.docs: obsahuje všechny soubory Markdownu nebo jinou dokumentaci, která slouží k popisu projektu.pipelines: obsahuje definice kanálů Azure Machine Learning.tests: obsahuje testy jednotek a integrace používané k detekci chyb a problémů v kódu.notebooks: obsahuje poznámkové bloky Jupyter, které se většinou používají k experimentování.
Poznámka:
Trénovací data by neměla být zahrnuta do vašeho úložiště. Data by měla být uložena v databázi nebo datovém jezeře. Azure Machine Learning může mít přímý přístup k databázi nebo datovému jezeře tím, že uloží informace o připojení jako úložiště dat.
Díky standardní struktuře, kterou každý projekt používá, budou datoví vědci a další spolupracovníci snadněji najít kód, na který potřebují pracovat.
Tip
Přečtěte si další osvědčené postupy pro strukturování projektů datových věd.
Pokud se chcete naučit pracovat s úložištěmi jako datový vědec, dozvíte se o vývoji založeném na kmenech.
Vývoj založený na kmenech
Většina projektů vývoje softwaru používá Git jako systém správy zdrojového kódu, který používá Azure DevOps i GitHub.
Hlavní výhodou používání Gitu je snadná spolupráce na kódu a také sledování všech provedených změn. Kromě toho můžete přidat schvalovací brány , abyste měli jistotu, že v produkčním kódu budou provedeny pouze změny, které byly zkontrolovány a přijaty.
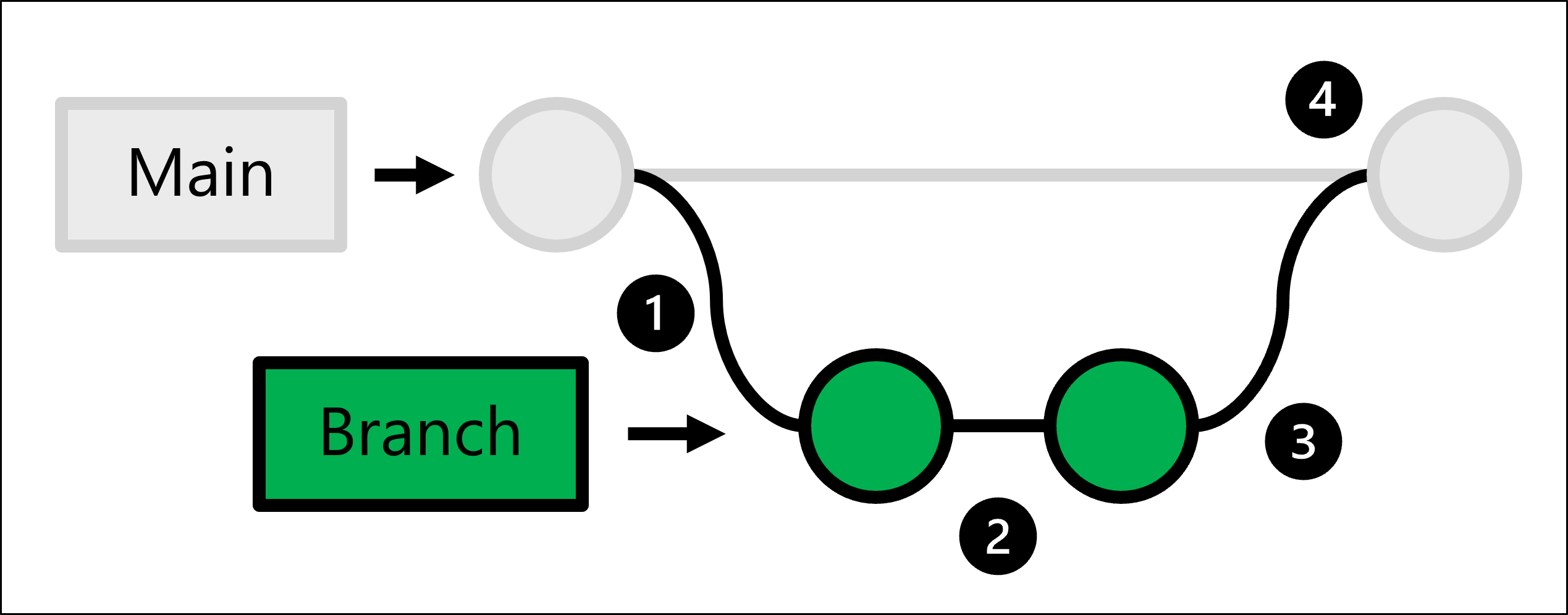
K výše uvedenému účelu Git využívá vývoj založený na kmenech, který umožňuje vytvářet větve.
Produkční kód je hostovaný v hlavní větvi. Kdykoli chce někdo udělat změnu:
- Úplnou kopii produkčního kódu vytvoříte vytvořením větve.
- Ve větvi, kterou jste vytvořili, provedete všechny změny a otestujete je.
- Jakmile jsou změny ve vaší větvi připravené, můžete požádat někoho, aby změny zkontroloval.
- Pokud jsou změny schválené, sloučíte větev, kterou jste vytvořili s hlavním úložištěm, a produkční kód se aktualizuje tak, aby odrážel vaše změny.