Vytvořit kanál
Kanál ve službě Azure Machine Learning je pracovní postup úloh strojového učení, ve kterých je každý úkol definovaný jako součást.
Komponenty se dají uspořádat postupně nebo paralelně a umožňují vytvářet sofistikovanou logiku toku pro orchestraci operací strojového učení. Každou komponentu je možné spustit na konkrétním cílovém výpočetním objektu, což umožňuje kombinovat různé typy zpracování podle potřeby, aby bylo možné dosáhnout celkového cíle.
Kanál lze spustit jako proces spuštěním kanálu jako úlohy kanálu. Každá komponenta se spouští jako podřízená úloha jako součást celkové úlohy kanálu.
Vytvoření kanálu
Kanál Služby Azure Machine Learning se definuje v souboru YAML. Soubor YAML obsahuje název úlohy kanálu, vstupy, výstupy a nastavení.
Můžete vytvořit soubor YAML nebo použít @pipeline() funkci k vytvoření souboru YAML.
Tip
Projděte si referenční dokumentaci pro @pipeline() funkci.
Pokud například chcete vytvořit kanál, který nejprve připraví data a pak model trénuje, můžete použít následující kód:
from azure.ai.ml.dsl import pipeline
@pipeline()
def pipeline_function_name(pipeline_job_input):
prep_data = loaded_component_prep(input_data=pipeline_job_input)
train_model = loaded_component_train(training_data=prep_data.outputs.output_data)
return {
"pipeline_job_transformed_data": prep_data.outputs.output_data,
"pipeline_job_trained_model": train_model.outputs.model_output,
}
Pokud chcete jako vstup úlohy kanálu předat registrovaný datový asset, můžete jako vstup volat funkci, kterou jste vytvořili s datovým assetem:
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes
pipeline_job = pipeline_function_name(
Input(type=AssetTypes.URI_FILE,
path="azureml:data:1"
))
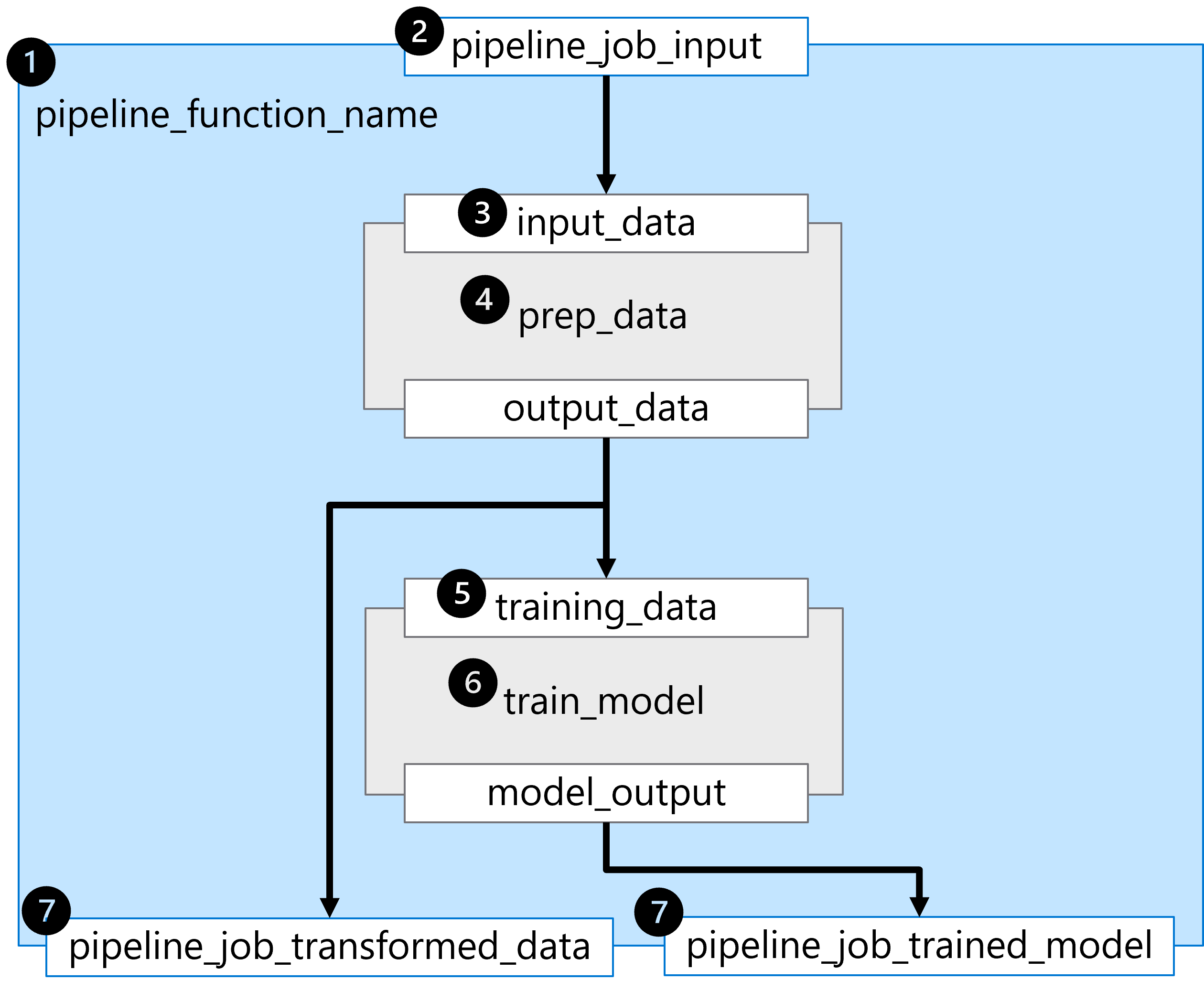
Funkce @pipeline() sestaví kanál skládající se ze dvou sekvenčních kroků reprezentovaných dvěma načtenými komponentami.
Abychom porozuměli kanálu integrovanému v příkladu, pojďme si ho projít krok za krokem:
- Kanál je vytvořen definováním funkce
pipeline_function_name. - Funkce kanálu očekává
pipeline_job_inputjako celkový vstup kanálu. - První krok kanálu vyžaduje hodnotu vstupního parametru
input_data. Hodnota pro vstup bude hodnotapipeline_job_input. - První krok kanálu je definován načtenou komponentou pro
prep_data. - Hodnota
output_dataprvního kroku kanálu se používá pro očekávaný vstuptraining_datadruhého kroku kanálu. - Druhý krok kanálu je definován načtenou komponentou pro
train_modeltrénovaný model, na kterýmodel_outputodkazuje . - Výstupy kanálu jsou definovány vrácením proměnných z funkce kanálu.
Existují dva výstupy:
pipeline_job_transformed_datas hodnotouprep_data.outputs.output_datapipeline_job_trained_models hodnotoutrain_model.outputs.model_output
Výsledkem spuštění @pipeline() funkce je soubor YAML, který můžete zkontrolovat tiskem pipeline_job objektu, který jste vytvořili při volání funkce:
print(pipeline_job)
Výstup bude formátován jako soubor YAML, který zahrnuje konfiguraci kanálu a jeho součástí. Některé parametry zahrnuté v souboru YAML jsou uvedeny v následujícím příkladu.
display_name: pipeline_function_name
type: pipeline
inputs:
pipeline_job_input:
type: uri_file
path: azureml:data:1
outputs:
pipeline_job_transformed_data: null
pipeline_job_trained_model: null
jobs:
prep_data:
type: command
inputs:
input_data:
path: ${{parent.inputs.pipeline_job_input}}
outputs:
output_data: ${{parent.outputs.pipeline_job_transformed_data}}
train_model:
type: command
inputs:
input_data:
path: ${{parent.outputs.pipeline_job_transformed_data}}
outputs:
output_model: ${{parent.outputs.pipeline_job_trained_model}}
tags: {}
properties: {}
settings: {}
Tip
Přečtěte si další informace o schématu YAML úlohy kanálu a zjistěte, které parametry jsou zahrnuty při sestavování kanálu založeného na komponentách.