Transformace dat pomocí operátorů
I když mnoho operátorů v data Wrangleru je intuitivní a snadno použitelné, jiné vyžadují hlubší pochopení, aby je mohli plně používat.
Použití operátoru kódování 1-hot
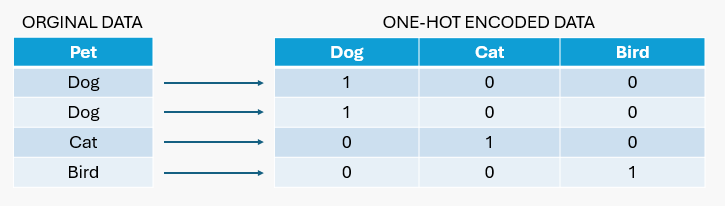
Některé modely strojového učení, jako je lineární regrese, vyžadují, aby všechny vstupní a výstupní proměnné byly číselné a nepodporují kategorické proměnné. Data kategorií odkazují na proměnné, které jsou rozdělené do více kategorií, které neobsahují číselnou hodnotu nebo pořadí.
V kódování typu 1 a 0 je každá kategorie ve funkci reprezentována binárním vektorem 1 a 0.
Pokud máte například proměnnou domácího mazlíčka s hodnotami pes, kočka a pták, vytvoří se tři nové proměnné (jedna pro každý typ domácího mazlíčka). Pro každý datový bod označí 1 pro domácí mazlíčka, který představuje, a 0 pro ostatní. Takže pokud datový bod představuje psa, je kódován jako [1, 0, 0]. Pokud je to kočka, je to [0, 1, 0], a pokud je to pták, je to [0, 0, 1].
Poznámka:
Kódování typu one-hot může vést ke zvýšení dimenzionálního rozsahu, což je v případě, že počet funkcí v datové sadě bude velmi velký. To platí zejména v případě, že kategorická proměnná má mnoho jedinečných hodnot.
Pojďme vytvořit datový rámec založený na výše uvedeném příkladu domácího mazlíčka a pomocí nástroje Data Wrangler vygenerujte kód pro kódování s jedním horkým kódem.
import pandas as pd
# Sample dataset with 50 data points, including duplicates
data = {'pet': ['dog', 'dog', 'cat', 'cat', 'bird', 'bird']*8 + ['bird', 'cat']}
df = pd.DataFrame(data)
print(df.head(10))
Následující kroky ukazují, jak pro proměnnou použít operátor pet kódování typu 1-hot.
Spusťte transformaci dat z poznámkového bloku Microsoft Fabric pro
dfdatový rámec.Vyberte proměnnou
pet.Na panelu Operations (Operace) vyberte Formulas (Vzorce) a pak one-hot encode (Kódování za provozu).
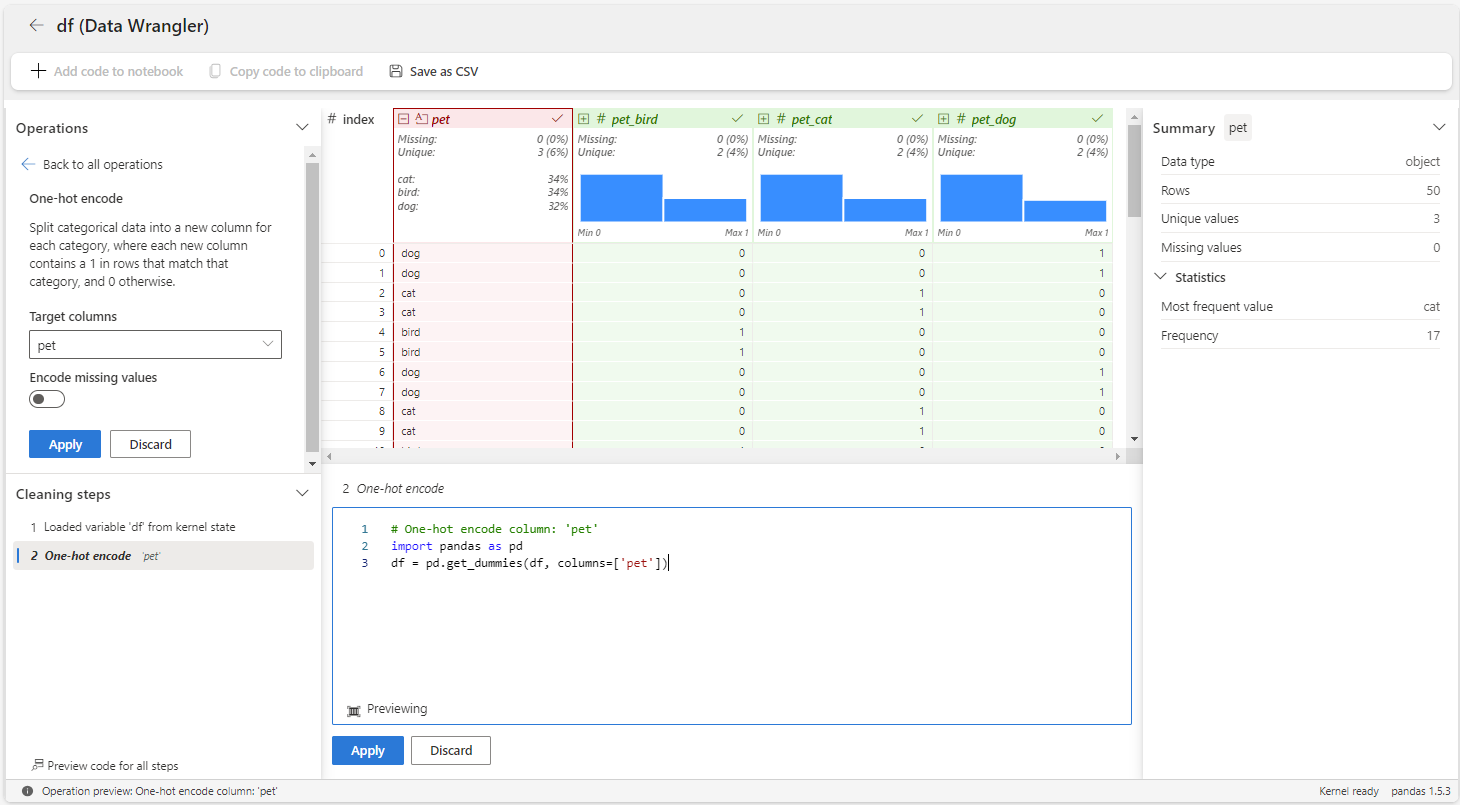
Vyberte Použít.
Na panelu nástrojů nad mřížkou Transformace dat vyberte + Přidat kód do poznámkového bloku . Tím se vygeneruje funkce, kterou pak můžete spustit v datovém kanálu.
Použití operátoru binarizeru s více popisky
Jedno-horké kódování se používá, když každý datový bod patří do přesně jedné kategorie. Na druhou stranu se operátor binarizátoru s více popisky používá, když každý datový bod může patřit do více kategorií.
Operátor binarizátoru s více popisky umožňuje rozdělit kategorická data do nového sloupce pro každou kategorii pomocí oddělovače textu, kde každý nový sloupec obsahuje jeden v řádcích, které odpovídají dané kategorii, a 0 jinak.
Pro účely trénování vytvoříme datový rámec o kategorii potravin a použijeme Data Wrangler k vygenerování kódu pro binarizátor s více popisky.
import pandas as pd
#Sample data
data = {
'food': ['Pasta', 'Burger', 'Ice Cream', 'Salad'],
'category': ['Italian|Fine dining', 'American|Fast Food', 'Dessert', 'Healthy']
}
# Create DataFrame
restaurant = pd.DataFrame(data)
Potom následující kroky ukazují, jak pro proměnnou použít operátor category binarizátoru s více popisky.
Spusťte transformaci dat z poznámkového bloku Microsoft Fabric pro
restaurantdatový rámec.Vyberte proměnnou
category.Na panelu Operations (Operace) vyberte Formulas (Vzorce) a potom Multi-label binarizer (Binarizer Multi-label).
Zadejte | jako delimetr.
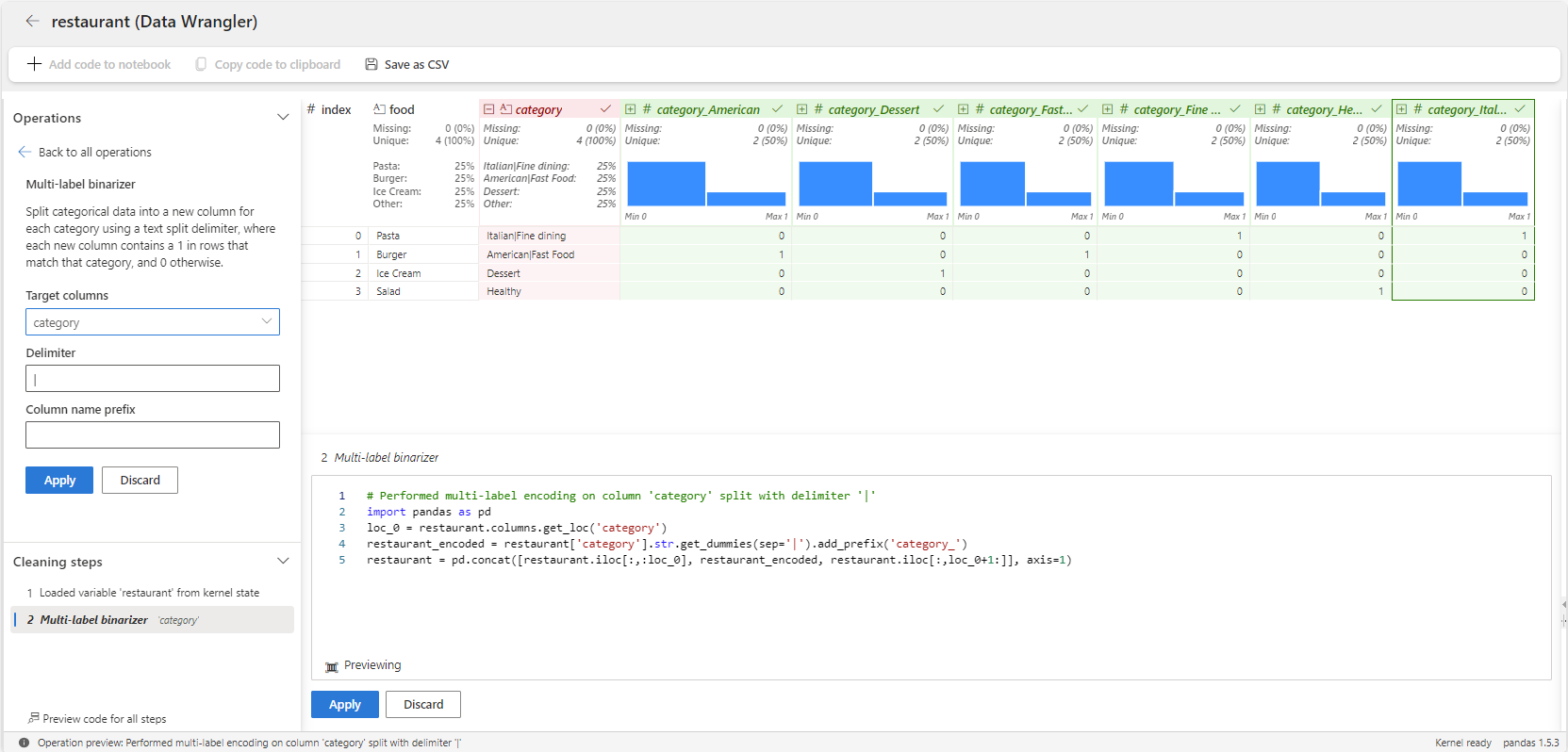
Výsledkem je datový rámec s proměnnými pro každou kategorii, jako jsou americké, dezerty, rychlé občerstvení, zdravé a italské. Každá položka jídla je v těchto sloupcích označená 1 nebo 0, aby se zobrazily kategorie, do kterých patří. Například pizza i burger spadají do více kategorií.
Vyberte Použít.
Na panelu nástrojů nad mřížkou Transformace dat vyberte + Přidat kód do poznámkového bloku . Tím se vygeneruje funkce, kterou pak můžete spustit v kanálu předběžného zpracování.
Použití operátoru škálování min-max
Minimální maximální nebo minimální normalizace je proces transformace číselné funkce. Tento proces škáluje rozsah dat při zachování tvaru původní distribuce a vztahů mezi proměnnými.
Zajišťuje, aby významnost funkce byla určena jeho relativní hodnotou, nikoli absolutní hodnotou. Jinými slovy, funkce se nepovažují za důležitější jednoduše, protože mají větší měřítka.
Vezme každou hodnotu v datech, odečte minimální hodnotu těchto dat a pak se vydělí rozsahem dat (maximální hodnota minus minimální hodnota).
Výsledkem je, že se vaše data přeškálí na rozsah 0 až 1, což může být užitečné pro určité typy algoritmů strojového učení, zejména těch, které používají míry vzdálenosti, jako jsou K-Nejbližší sousedé.
Pojďme se podívat na datový rámec, který představuje známky studentů v předmětu. Datový rámec má tři sloupce: Student, Math_Grade, English_Gradea Hours_Studied.
import pandas as pd
# Sample data
data = {
'Student': ['Bob', 'Mark', 'Anna', 'David', 'Sam'],
'Math_Grade': [85, 90, 78, 92, 88],
'English_Grade': [80, 85, 92, 88, 90],
'Hours_Studied': [250, 500, 355, 245, 199]
}
df = pd.DataFrame(data)
print(df)
Výstup je:
Student Math_Grade English_Grade Hours_Studied
0 Bob 85 80 250
1 Mark 90 85 500
2 Anna 78 92 355
3 David 92 88 245
4 Sam 88 90 199
Teď použijeme minimální maximální měřítko na Math_Gradehodnotu , English_Gradea Hours_Studied proměnné pomocí služby Data Wrangler. K tomu je potřeba použít operátor Minimální/maximální hodnoty měřítka v kategorii Numeric .
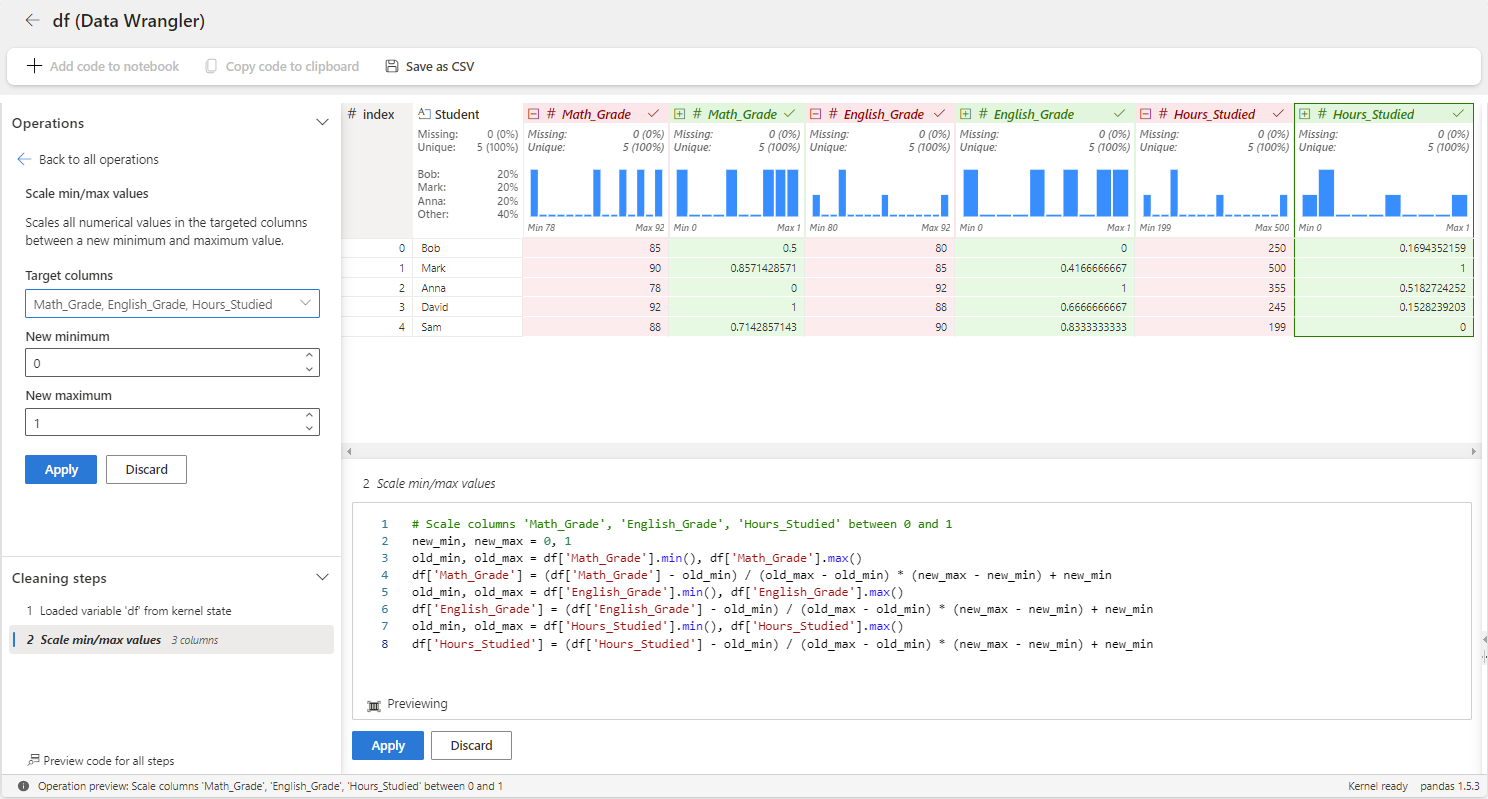
Ve výše uvedeném příkladu jsou známky škálovány tak, aby spadají do rozsahu [0, 1], s minimální známkou namapovanou na 0 a maximální známkou namapovanou na 1. Ostatní známky se v tomto rozsahu škálují úměrně. Můžete také upravit minimální a maximální rozsah.
Pokud používáte funkce, jako je Math_Grade, English_Gradea Hours_Studied v algoritmu strojového učení založeném na dálku, jako je K-Nejbližší sousedé bez jejich prvního škálování, můžete narazit na některé problémy.
Funkce Hours_Studied může potenciálně dominovat ostatním funkcím z důvodu většího rozsahu hodnot. To by mohlo vést k modelu, který silně spoléhá na Hours_Studied, a přitom ignorovat Math_Grade a English_Grade. Proto je důležité škálovat data v těchto případech, aby se zajistilo, že všechny funkce budou přidělovat stejnou důležitost.
Další informace o normalizaci dat pro modely strojového učení najdete v tématu Transformace dat.