Principy transformace dat
Data Wrangler je nástroj založený na poznámkových blocích Microsoft Fabric, který nabízí komplexní platformu pro průzkumné a předběžné zpracování úloh. Nabízí zobrazení dat, dynamickou souhrnnou statistiku, předdefinované vizualizace a knihovnu běžných operací předběžného zpracování dat.
Každá operace aktualizuje zobrazení dat v reálném čase a vygeneruje opakovaně použitelný kód, který lze uložit zpět do poznámkového bloku. Jeho uživatelsky přívětivé rozhraní je efektivním nástrojem pro datové vědce, který umožňuje zpracovávat velké objemy dat a transformovat nezpracovaná data na datovou sadu připravenou k analýze.
Data Wrangler si můžete představit jako nástroj, který generuje kód pro zkoumání a předzpracování dat.
Poznámka:
Data Wrangler aktuálně podporuje pouze datový rámec Pandas .
Práce s rozhraním Wrangler dat
Transformace dat může pomoct s fází předběžného zpracování modelu strojového učení tím, že poskytuje nástroje a funkce pro čištění dat, přípravu funkcí, zkoumání dat a zlepšení efektivity při předběžném zpracování dat.
Zkoumání dat: Zobrazení dat podobných mřížce nástroje umožňuje vizuálně zkoumat data, což může vést k přehledům o proměnných.
Čištění dat: Služba Wrangler dat poskytuje knihovnu běžných operací čištění dat, což usnadňuje zpracování chybějících hodnot, odlehlých hodnot a nesprávných datových typů.
Příprava funkcí: Díky integrovaným vizualizacm a dynamickým souhrnným statistikám vám data Wrangler pomůže pochopit distribuci dat a vytvořit nové funkce.
Data Wrangler vám může pomoct zajistit, aby vaše data byla v nejlepším možném tvaru, než se použije k trénování modelu strojového učení. To může vést k přesnějším modelům a lepším předpovědím.
Spuštění transformace dat z poznámkového bloku
Pokud chcete spustit službu Data Wrangler v Microsoft Fabric, postupujte takto.
Přepněte z Power BI na Datová Věda pomocí ikony přepínače prostředí na levé straně domovské stránky. Pak vytvořte nový poznámkový blok.
Načtěte data do datového rámce Pandas v poznámkovém bloku Microsoft Fabric.
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") Add another dataset example.Po načtení dat do datového rámce vyberte na pásu karet poznámkového bloku data .
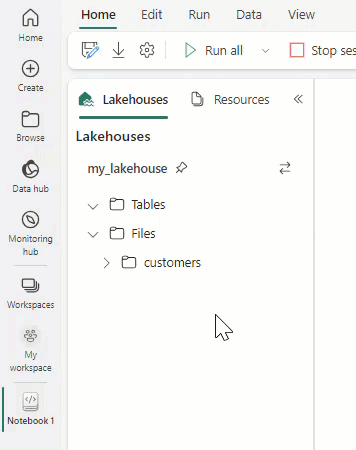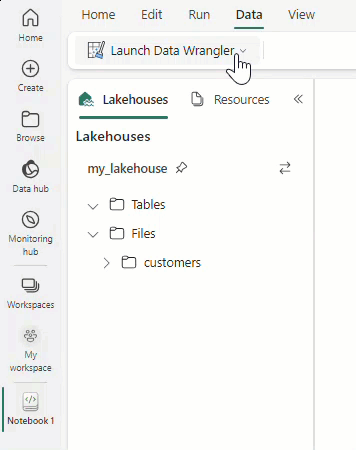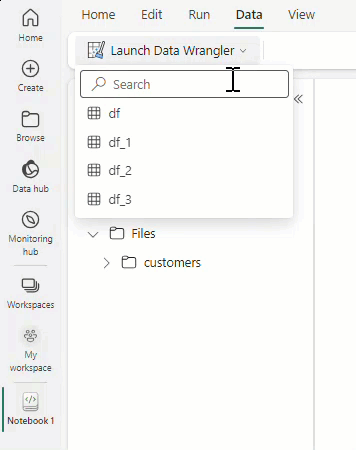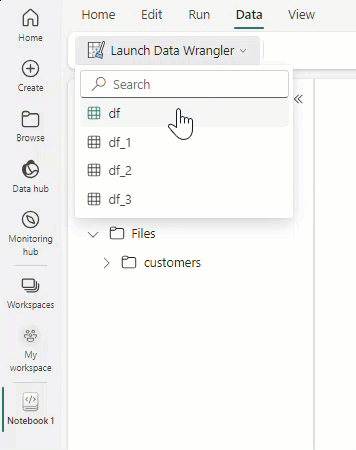
Vyberte Spustit datový Wrangler a pak vyberte datový rámec, který chcete otevřít ve službě Data Wrangler. Pokud máte více datových rámců, zobrazí se všechny.
Tip
Rozšíření Data Wrangler pro Visual Studio Code umožňuje integraci transformace dat do VS Code i do poznámkových bloků Jupyter v editoru VS Code.
Práce s operátory
Představte si, že pracujete na velké datové sadě pro kritický projekt. Data potřebují hodně práce. Chybí vám hodnoty, duplicitní řádky a sloupce, které potřebují přejmenování. Navíc je potřeba transformovat některá kategorická data do formátu, kterému model strojového učení rozumí.
Tady přichází data Wrangler. S minimálním úsilím můžete řadit a filtrovat řádky, kategorická data s jedním kódováním, měnit typy sloupců, odstraňovat nepotřebné sloupce, přejmenovávat sloupce, zpracovávat chybějící hodnoty a mnoho dalšího. Kromě toho data Wrangler usnadňuje tyto úlohy, ale také generuje opakovaně použitelný kód Pythonu pro každou operaci, který můžete uložit zpět do poznámkového bloku. To znamená, že můžete automatizovat úlohy zpracování dat pro budoucí datové sady.
Tady jsou kategorie operátorů, které jsou aktuálně k dispozici ve službě Data Wrangler.
| Kategorie | Popis |
|---|---|
| Najít a nahradit | Zahrnuje operace, jako je vyřazení duplicitních řádků, zpracování chybějících hodnot a hledání a nahrazení hodnot. |
| Formát | Zahrnuje transformace textu, jako je převod na velká a malá a velká písmena, rozdělení textu, odstranění prázdných znaků a automatické transformace využívající Microsoft Flash Fill. |
| Receptury | Umožňuje vytvářet nové sloupce pomocí vlastních vzorců Pythonu, binarizátoru s více popisky, kódování s jednou horou a výpočtu délky textu. |
| Číslo | Zahrnuje operace, jako je zaokrouhlení (nahoru, dolů nebo na nejbližší číslo) a škálování minimálních/maximálních hodnot. |
| Schéma | Umožňuje změny schématu datového rámce, jako je změna typu sloupce, klonování, přejmenovávání nebo přejmenování nebo výběr sloupců. |
| Řazení a filtrování | Zahrnuje operace pro filtrování a řazení hodnot. |
| Jiný | Zahrnuje vlastní operace pro úpravy datového rámce, seskupování a agregace a automatického vytváření sloupců využívajících Microsoft Flash Fill. |
V dalších lekcích prozkoumáme celou řadu operátorů a získáme přehled o tom, jak můžou usnadnit úlohy předběžného zpracování pro vytváření prediktivních modelů.