Cvičení: Trénování modelu strojového učení
Shromáždili jste data ze snímačů z výrobních zařízení, která jsou v pořádku, a ze zařízení, která selhala. Teď chcete použít Tvůrce modelů k trénování modelu strojového učení, který předpovídá, jestli se počítač nezdaří nebo ne. Díky strojovému učení k automatizaci monitorování těchto zařízení můžete ušetřit peníze společnosti tím, že zajistíte včasnější a spolehlivou údržbu.
Přidání nové položky modelu strojového učení (ML.NET)
Pokud chcete zahájit proces trénování, musíte do nové nebo existující aplikace .NET přidat novou položku modelu strojového učení (ML.NET ).
Vytvoření knihovny tříd jazyka C#
Vzhledem k tomu, že začínáte od začátku, vytvořte nový projekt knihovny tříd C#, do kterého přidáte model strojového učení.
Spusťte Visual Studio.
V úvodním okně vyberte Vytvořit nový projekt.
V dialogovém okně Vytvořit nový projekt zadejte na panelu hledání knihovnu tříd.
V seznamu možností vyberte knihovnu tříd. Ujistěte se, že jazyk je jazyk C# a vyberte Další.
Do textového pole Název projektu zadejte PredictiveMaintenance. U všech ostatních polí ponechte výchozí hodnoty a vyberte Další.
V rozevíracím seznamu Rozhraní vyberte .NET 6.0 (Preview) a pak vyberte Vytvořit pro generování knihovny tříd jazyka C#.

Přidání strojového učení do projektu
Po otevření projektu knihovny tříd v sadě Visual Studio je čas do něj přidat strojové učení.
V sadě Visual Studio Průzkumník řešení klikněte pravým tlačítkem na projekt.
Vyberte Přidat>model strojového učení.
V seznamu nových položek v dialogovém okně Přidat novou položku vyberte Model strojového učení (ML.NET).
V textovém poli Název použijte název PredictiveMaintenanceModel.mbconfig pro váš model a vyberte Přidat.


Po několika sekundách se do projektu přidá soubor s názvem PredictiveMaintenanceModel.mbconfig .
Volba scénáře
Při prvním přidání modelu strojového učení do projektu se otevře obrazovka Tvůrce modelů. Teď je čas vybrat váš scénář.
V případě použití se pokoušíte zjistit, jestli je počítač poškozený nebo ne. Vzhledem k tomu, že existují pouze dvě možnosti a chcete určit, ve kterém stavu je počítač, je scénář klasifikace dat nejvhodnější.
V kroku Scénář na obrazovce Tvůrce modelů vyberte scénář klasifikace dat. Jakmile tento scénář vyberete, okamžitě se do kroku Prostředí přepošli.

Volba prostředí
Pro scénáře klasifikace dat jsou podporována pouze místní prostředí, která používají váš procesor.
- V kroku Prostředí na obrazovce Tvůrce modelů je ve výchozím nastavení vybraná možnost Místní (CPU). Ponechte vybrané výchozí prostředí.
- Vyberte Další krok.

Načtení a příprava dat
Teď, když jste vybrali svůj scénář a trénovací prostředí, je čas načíst a připravit data shromážděná pomocí Tvůrce modelů.
Příprava dat
Otevřete soubor v textovém editoru podle vašeho výběru.
Původní názvy sloupců obsahují speciální závorky. Pokud chcete zabránit problémům s analýzou dat, odeberte ze názvů sloupců speciální znaky.
Původní hlavička:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNFAktualizováno záhlaví:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNFUložte soubor ai4i2020.csv se změnami.
Zvolte typ zdroje dat.
Datová sada prediktivní údržby je soubor CSV.
V kroku Data na obrazovce Tvůrce modelů vyberte soubor (csv, tsv, txt) pro typ zdroje dat.
Zadejte umístění dat.
Vyberte tlačítko Procházet a pomocí Průzkumníka souborů zadejte umístění datové sady ai4i2020.csv.
Zvolte sloupec štítků.
Pokud chcete předpovědět rozevírací seznam (Popisek), zvolte selhání počítače ze sloupce.

Volba rozšířených možností dat
Ve výchozím nastavení se všechny sloupce, které nejsou popiskem, používají jako funkce. Některé sloupce obsahují redundantní informace a jiné neinformují predikci. Pomocí rozšířených možností dat tyto sloupce ignorujte.
Vyberte Rozšířené možnosti dat.
V dialogovém okně Upřesnit možnosti dat vyberte kartu Nastavení sloupce.
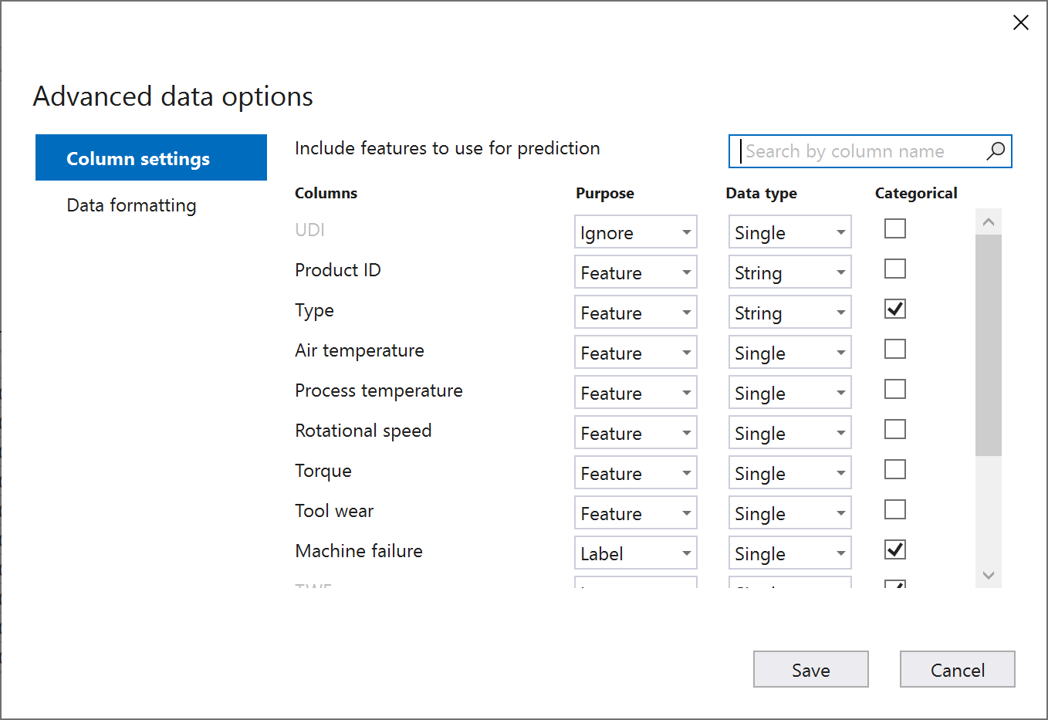
Nakonfigurujte nastavení sloupce následujícím způsobem:
Sloupce Účel Datový typ Kategorické UDI Ignorovat Jeden ID produktu Funkce String Typ Funkce String X Teplota vzduchu Funkce Jeden Teplota procesu Funkce Jeden Otáčky Funkce Jeden Točivý moment Funkce Jeden Opotřebení nástrojů Funkce Jeden Selhání počítače Popisek Jeden X TWF Ignorovat Jeden X HDF Ignorovat Jeden X PWF Ignorovat Jeden X OSF Ignorovat Jeden X RNF Ignorovat Jeden X Zvolte Uložit.
V kroku Data na obrazovce Tvůrce modelů vyberte Další krok.

Trénování vašeho modelu
K trénování modelu použijte Tvůrce modelů a AutoML.
Nastavení trénovacího času
Tvůrce modelů automaticky nastaví, jak dlouho byste měli trénovat na základě velikosti souboru. V tomto případě, pokud chcete Tvůrci modelů pomoct prozkoumat více modelů, poskytnout vyšší číslo pro trénovací dobu.
- V kroku Trénování obrazovky Tvůrce modelů nastavte čas trénování (sekund) na 30.
- Vyberte Trénink.
Sledování procesu trénování

Jakmile se proces trénování spustí, Tvůrce modelů prozkoumá různé modely. Váš proces trénování se sleduje ve výsledcích trénování a v okně výstupu sady Visual Studio. Výsledky trénování poskytují informace o nejlepším modelu, který byl nalezen v průběhu trénování. V okně výstupu najdete podrobné informace, jako je název použitého algoritmu, jak dlouho trvalo trénování, a metriky výkonu pro daný model.
Stejný název algoritmu se může zobrazit několikrát. K tomu dochází, protože kromě vyzkoušení různých algoritmů se Tvůrce modelů snaží pro tyto algoritmy použít různé konfigurace hyperparametrů.
Vyhodnocení modelu
Pomocí metrik vyhodnocení a dat otestujte, jak dobře model funguje.
Kontrola modelu
Krok Vyhodnocení na obrazovce Tvůrce modelů umožňuje zkontrolovat metriky vyhodnocení a algoritmus, které jsou vybrány pro nejlepší model. Mějte na paměti, že je v pořádku, pokud se výsledky liší od výsledků uvedených v tomto modulu, protože zvolený algoritmus a hyperparametry se můžou lišit.
Testování modelu
V části Vyzkoušet model v kroku Vyhodnocení můžete zadat nová data a vyhodnotit výsledky předpovědi.

V části Ukázková data je místo, kde zadáte vstupní data pro model k vytváření předpovědí. Každé pole odpovídá sloupcům, které se používají k trénování modelu. Jedná se o pohodlný způsob, jak ověřit, že se model chová podle očekávání. Tvůrce modelů ve výchozím nastavení předem naplní ukázková data prvním řádkem z datové sady.
Pojďme model otestovat a zjistit, jestli generuje očekávané výsledky.
V části Ukázková data zadejte následující data. Pochází z řádku v datové sadě s UID 161.
Column Hodnota ID produktu L47340 Typ L Teplota vzduchu 298.4 Teplota procesu 308.2 Otáčky 1282 Točivý moment 60.7 Opotřebení nástrojů 216 Vyberte Předpovědět.
Vyhodnocení výsledků předpovědi
V části Výsledky se zobrazí předpověď, kterou váš model provedl, a úroveň spolehlivosti této předpovědi.
Pokud se podíváte na sloupec Selhání počítače uID 161 v datové sadě, všimnete si, že hodnota je 1. Jedná se o stejnou hodnotu jako předpovězená hodnota s nejvyšší jistotou v části Výsledky .
Pokud chcete, můžete pokračovat v vyzkoušení modelu s různými vstupními hodnotami a vyhodnocením předpovědí.
Gratulujeme! Natrénovali jste model tak, aby předpověděl selhání počítačů. V další lekci se dozvíte o spotřebě modelů.