Cvičení – vizualizace výstupu modelu
V této lekci naimportujete knihovnu Matplotlib do poznámkového bloku, s nímž pracujete, a nakonfigurujete ji tak, aby podporovala vložený výstup Matplotlib.
Přejděte zpět do poznámkového bloku Azure, který jste vytvořili v předchozí části. Pokud jste poznámkový blok zavřeli, můžete se znovu přihlásit k portálu Microsoft Azure Notebooks, otevřít poznámkový blok a po otevření poznámkového bloku znovu spustit všechny buňky v poznámkovém bloku.>
V nové buňce na konci poznámkového bloku spusťte následující příkazy: Ignorujte všechna upozornění, která se zobrazí v souvislosti s ukládáním písma do mezipaměti:
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns sns.set()První příkaz je jedním z několika magických příkazů podporovaných jádrem Pythonu, které jste vybrali při vytváření poznámkového bloku. Umožňuje Jupyteru zobrazit výstup knihovny Matplotlib v poznámkovém bloku, aniž by se musela opakovaně volat metoda show. Musí být uveden před všemi odkazy na samotnou knihovnu Matplotlib. Poslední příkaz nakonfiguruje Seaborn na rozšíření výstupu z knihovny Matplotlib.
Pokud chcete vidět Matplotlib při práci, spusťte následující kód v nové buňce, který vykreslí křivku ROC pro model strojového učení vytvořený v předchozím cvičení:
from sklearn.metrics import roc_curve fpr, tpr, _ = roc_curve(test_y, probabilities[:, 1]) plt.plot(fpr, tpr) plt.plot([0, 1], [0, 1], color='grey', lw=1, linestyle='--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate')Měl by se zobrazit následující výstup:
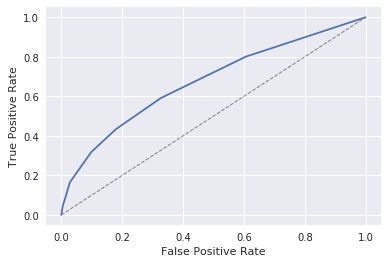
Křivka ROC vygenerovaná pomocí knihovny Matplotlib
Tečkovaná čára uprostřed grafu představuje šanci 50 ku 50, že získáte správnou odpověď. Modrá křivka představuje přesnost modelu. Ale co je důležitější – fakt, že se tento graf vůbec zobrazí, ukazuje, že je možné knihovnu Matplotlib použít v poznámkovém bloku Jupyter.
Důvodem vytvoření modelu strojového učení je předpověď, zda let přistane na čas nebo zda bude opožděn. V tomto cvičení napíšete funkci Pythonu, která zavolá model strojového učení vytvořený v předchozím cvičení a vypočítá pravděpodobnost, že let přistane na čas. Potom tuto funkci použijete k analýze několika letů.
Do nové buňky zadejte následující definici funkce a buňku spusťte.
def predict_delay(departure_date_time, origin, destination): from datetime import datetime try: departure_date_time_parsed = datetime.strptime(departure_date_time, '%d/%m/%Y %H:%M:%S') except ValueError as e: return 'Error parsing date/time - {}'.format(e) month = departure_date_time_parsed.month day = departure_date_time_parsed.day day_of_week = departure_date_time_parsed.isoweekday() hour = departure_date_time_parsed.hour origin = origin.upper() destination = destination.upper() input = [{'MONTH': month, 'DAY': day, 'DAY_OF_WEEK': day_of_week, 'CRS_DEP_TIME': hour, 'ORIGIN_ATL': 1 if origin == 'ATL' else 0, 'ORIGIN_DTW': 1 if origin == 'DTW' else 0, 'ORIGIN_JFK': 1 if origin == 'JFK' else 0, 'ORIGIN_MSP': 1 if origin == 'MSP' else 0, 'ORIGIN_SEA': 1 if origin == 'SEA' else 0, 'DEST_ATL': 1 if destination == 'ATL' else 0, 'DEST_DTW': 1 if destination == 'DTW' else 0, 'DEST_JFK': 1 if destination == 'JFK' else 0, 'DEST_MSP': 1 if destination == 'MSP' else 0, 'DEST_SEA': 1 if destination == 'SEA' else 0 }] return model.predict_proba(pd.DataFrame(input))[0][0]Jako vstup tato funkce použije datum a čas, kód výchozího letiště a kód cílového letiště a vrátí hodnotu v rozmezí 0,0 až 1,0, která označuje pravděpodobnost, že let dorazí do cíle na čas. Pro výpočet pravděpodobnosti použije model strojového učení, který jste vytvořili v předchozím cvičení. Aby funkce mohla zavolat model, předá metodě
predict_probadatový rámec, který obsahuje vstupní hodnoty. Struktura datového rámce přesně odpovídá struktuře datového rámce, který jsme použili dříve.Poznámka:
Kalendářní data zadávaná funkce
predict_delayjsou v mezinárodním formátu datadd/mm/year.Pomocí kódu uvedeného níže vypočítejte pravděpodobnost, že let z New Yorku do Atlanty ve večerních hodinách dne 1. října přistane na čas. Rok, který zadáte, je irelevantní, protože model ho nepoužije.
predict_delay('1/10/2018 21:45:00', 'JFK', 'ATL')Zkontrolujte, že pravděpodobnost příletu na čas zobrazená ve výstupu je 60 %:

Předpověď, zda let přistane na čas
Změňte kód tak, aby vypočítal pravděpodobnost, že stejný let o den později přistane na čas:
predict_delay('2/10/2018 21:45:00', 'JFK', 'ATL')Jaká je pravděpodobnost, že tento let přistane na čas? Pokud to vaše cestovní plány nijak nenaruší, neodložili byste cestu o jeden den?
Nyní změňte kód tak, aby vypočítal pravděpodobnost, že ranní let ve stejný den z Atlanty do Seattlu přistane na čas:
predict_delay('2/10/2018 10:00:00', 'ATL', 'SEA')Přistane tento let pravděpodobně na čas?
S pomocí jediného řádku kódu jste získali snadný způsob, jak předpovědět, zda let přistane pravděpodobně na čas nebo zda bude opožděn. Bez obav experimentujte s ostatními daty, časy, místy odletu a příletu. Mějte ale na paměti, že výsledky dávají smysl pouze pro letiště s kódy ATL, DTW, JFK, MSP a SEA, protože to jsou jediné letištní kódy, pomocí nichž byl model vytrénován.
Následující kód spusťte, pokud chcete zobrazit pravděpodobnost včasných příletů u večerního letu z letiště JFK na letiště ATL v rozmezí několika dnů:
import numpy as np labels = ('Oct 1', 'Oct 2', 'Oct 3', 'Oct 4', 'Oct 5', 'Oct 6', 'Oct 7') values = (predict_delay('1/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('2/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('3/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('4/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('5/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('6/10/2018 21:45:00', 'JFK', 'ATL'), predict_delay('7/10/2018 21:45:00', 'JFK', 'ATL')) alabels = np.arange(len(labels)) plt.bar(alabels, values, align='center', alpha=0.5) plt.xticks(alabels, labels) plt.ylabel('Probability of On-Time Arrival') plt.ylim((0.0, 1.0))Zkontrolujte, jestli výstup vypadá takto:
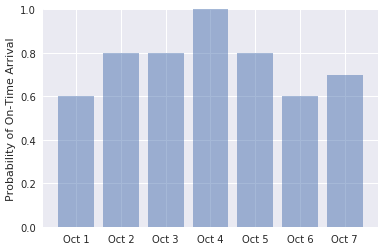
Pravděpodobnost včasných příletů v rozmezí kalendářních dat
Upravte kód tak, aby vytvořil podobný graf pro lety z JFK pro MSP v 13:00 v 10. dubnu až 16. dubna. Jak se bude výstup lišit od výstupu v předchozím kroku?
Napište kód pro graf pravděpodobnosti, že lety opouštějící SEA pro ATL v 9:00, poledne, 3:00, 18:00, 6:00 hod. a 9:00 hod. Zkontrolujte, jestli výstup vypadá takto:
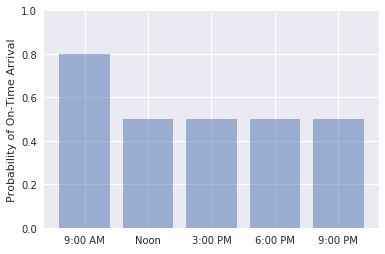
Pravděpodobnost včasných příletů v časovém rozmezí
Pokud s knihovnou Matplotlib teprve začínáte a chcete se o ní dovědět více, najdete vynikající kurz na adrese https://www.labri.fr/perso/nrougier/teaching/matplotlib/. Knihovna Matplotlib toho umí mnohem více, než jsme si tady ukázali, což je jeden z důvodů její velké popularity v komunitě uživatelů Pythonu.