Cvičení – vyčištění a příprava dat
Než se pustíte do přípravy datové sady, musíte porozumět jejímu obsahu a struktuře. V předchozím cvičení jste naimportovali datovou sadu, která obsahovala informace o včasných příletech u významné americké letecké společnosti. Tato data zahrnovala 26 sloupců a tisíce řádků, přičemž každý řádek představoval jeden let a obsahoval informace, jako je místo odletu a příletu a plánovaný čas odletu. Data jste také načetli do poznámkového bloku Jupyter a pomocí jednoduchého skriptu Pythonu jste z nich vytvořili datový rámec Pandas.
Datový rámec je dvoudimenzionální datová struktura s popiskem. Sloupce v datovém rámci mohou mít různé typy, stejně jako tomu je u sloupců v excelové nebo databázové tabulce. Jedná se o nejčastěji používaný objekt v Pandasu. V tomto cvičení se podrobněji zaměříme na datový rámec a data, která obsahuje.
Přejděte zpět do poznámkového bloku Azure, který jste vytvořili v předchozí části. Pokud jste poznámkový blok zavřeli, můžete se znovu přihlásit k portálu Microsoft Azure Notebooks, otevřít poznámkový blok a po otevření poznámkového bloku znovu spustit všechny buňky v poznámkovém bloku.>
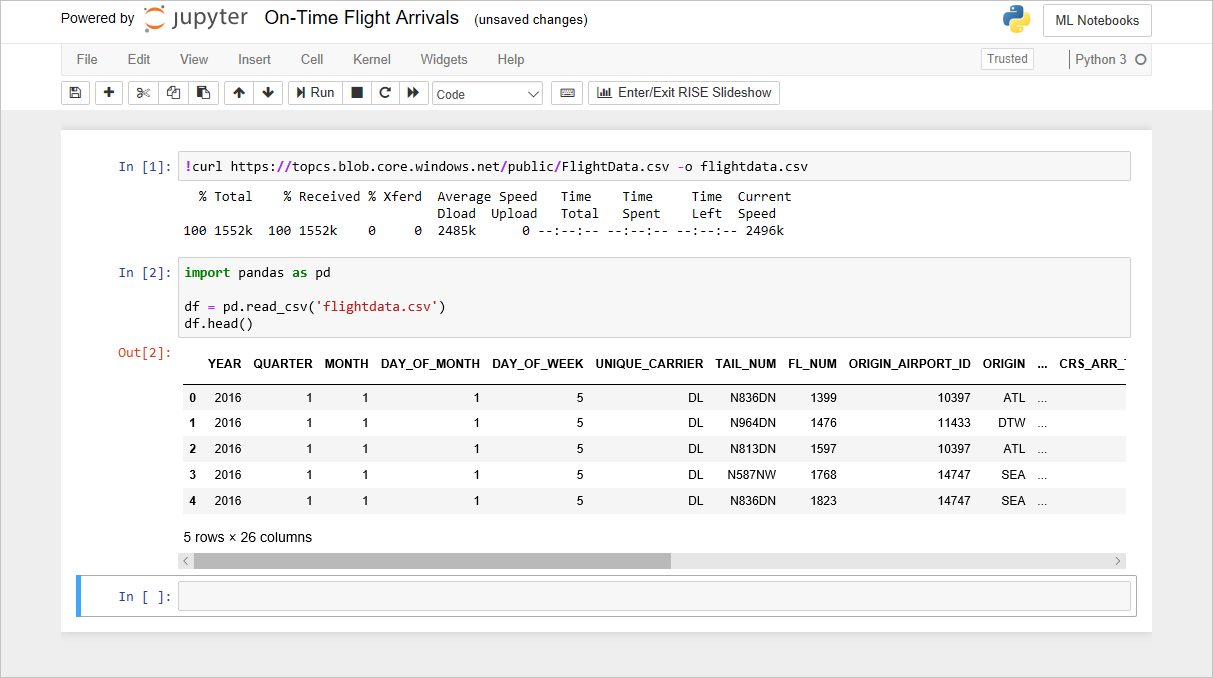
Poznámkový blok s letovými údaji
Kód, který jste přidali do poznámkového bloku v předchozím cvičení, vytvoří ze souboru flightdata.csv datový rámec a zavolá u něj DataFrame.head, aby se zobrazilo prvních pět řádků. Jedna z první věcí, která vás obvykle na datové sadě zajímá, je počet řádků. Jejich počet získáte tak, že spustíte následující příkaz, který přidáte do prázdné buňky na konci poznámkového bloku:
df.shapeVšimněte si, že datový rámec obsahuje 11 231 řádků a 26 sloupců:

Získání počtu řádků a sloupců
Nyní se blíže podíváme na 26 sloupců v datové sadě. Datová sada obsahuje důležité informace, například datum letu (YEAR, MONTH a DAY_OF_MONTH), místo odletu a příletu (ORIGIN a DEST), plánované časy odletu a příletu (CRS_DEP_TIME a CRS_ARR_TIME), rozdíl mezi plánovaným a skutečným časem příletu v minutách (ARR_DELAY) a zda byl let opožděn o 15 nebo více minut (ARR_DEL15).
Tady je kompletní seznam sloupců v datové sadě. Časy jsou vyjádřeny ve 24hodinovém vojenském formátu. Například 1130 se rovná 11:30 a 1500 se rovná 3:00.
Sloupec Popis YEAR Rok, ve kterém se let uskutečnil QUARTER Čtvrtletí, ve kterém se let uskutečnil (1–4) MONTH Měsíc, ve kterém se let uskutečnil (1–12) DAY_OF_MONTH Den v měsíci, kdy se let uskutečnil (1–31) DAY_OF_WEEK Den v týdnu, kdy se let uskutečnil (1 = pondělí, 2 = úterý atd.) UNIQUE_CARRIER Kód letecké společnosti (např. DL) TAIL_NUM Číslo na zádi letadla FL_NUM Číslo letu ORIGIN_AIRPORT_ID ID výchozího letiště ORIGIN Kód výchozího letiště (ATL, DFW, SEA atd.) DEST_AIRPORT_ID ID cílového letiště DEST Kód cílového letiště (ATL, DFW, SEA atd.) CRS_DEP_TIME Plánovaný čas odletu DEP_TIME Skutečný čas odletu DEP_DELAY Počet minut, o které byl odlet opožděn DEP_DEL15 0 = odlet opožděn o méně než 15 minut, 1 = odlet opožděn o 15 nebo více minut CRS_ARR_TIME Plánovaný čas příletu ARR_TIME Skutečný čas příletu ARR_DELAY Počet minut, o které byl přílet opožděn ARR_DEL15 0 = přílet opožděn o méně než 15 minut, 1 = přílet opožděn o 15 nebo více minut CANCELLED 0 = let nebyl zrušen, 1 = let byl zrušen DIVERTED 0 = let nebyl odkloněn, 1 = let byl odkloněn CRS_ELAPSED_TIME Plánovaný čas příletu v minutách ACTUAL_ELAPSED_TIME Skutečný čas příletu v minutách DISTANCE Vzdálenost letu v mílích
Datová sada obsahuje data, která jsou zhruba rovnoměrně distribuovaná v průběhu celého roku. To je důležité, protože pravděpodobnost zpoždění letu z Minneapolis kvůli sněhové bouři je menší v červenci než v lednu. Ale tato datová sada ještě zdaleka není „čistá“ a připravená k použití. Napíšeme si kód Pandas, pomocí něhož sadu vyčistíme.
Jedním z nejdůležitějších aspektů přípravy datové sady na použití ve strojovém učení je výběr „důležitých“ sloupců relevantních pro výsledek, který se pokoušíte předpovědět. Pokud byste vyfiltrovali i sloupce, které nemají na výsledek žádný vliv, mohlo by dojít ke zkreslení nebo dokonce k multikolinearitě. Dalším důležitým úkolem je eliminovat chybějící hodnoty, a to buď tak, že odstraníte řádky nebo sloupce, které je obsahují, nebo tak, že chybějící hodnoty nahradíte smysluplnými hodnotami. V tomto cvičení eliminujete nadbytečné sloupce a ve zbývajících sloupcích nahradíte chybějící hodnoty.
Jednou z prvních věcí, po kterých se obvykle odborníci na data dívají, jsou chybějící hodnoty. Pandas nabízí jednoduchý způsob, jak chybějící hodnoty vyhledat. Abychom si to mohli předvést, spusťte v buňce na konci poznámkového bloku následující kód:
df.isnull().values.any()Zkontrolujte, že výstupem je hodnota True, která označuje, že někde v datové sadě chybí minimálně jedna hodnota.

Vyhledání chybějících hodnot
Dalším krokem je zjištění, na kterých místech hodnoty chybí. Uděláte to spuštěním následujícího kódu:
df.isnull().sum()Zkontrolujte, že se zobrazil následující výstup, který uvádí počet chybějících hodnot v jednotlivých sloupcích:
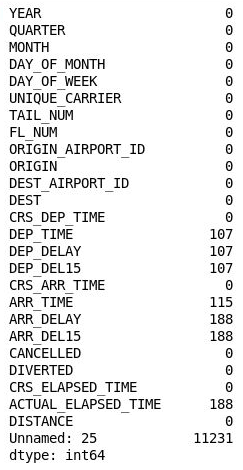
Počet chybějících hodnot v jednotlivých sloupcích
26. sloupec (Bez názvu: 25) obsahuje 11 231 chybějících hodnot, což se rovná počtu řádků v datové sadě. Tento sloupce se vytvořil omylem, protože soubor CSV, který jste naimportovali, obsahuje čárku na konci každého řádku. Pokud chcete tento sloupec vyřadit, přidejte do poznámkového bloku následující kód a spusťte ho:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Projděte si výstup a zkontrolujte, že z datového rámce zmizel tento sloupec 26:
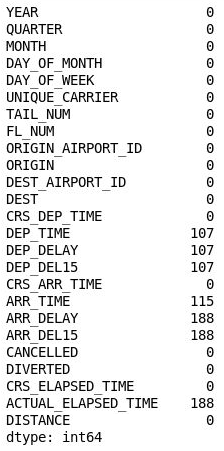
Datový rámec s odebraným sloupcem 26
Datový rámec stále obsahuje mnoho chybějících hodnot, ale některé z nich nejsou potřeba, protože sloupce, které je obsahují, nejsou pro vytvářený model relevantní. Cílem daného modelu je předpovědět to, zda let, který si chcete zarezervovat, pravděpodobně přistane na čas. Když budete vědět, že let bude mít pravděpodobně zpoždění, můžete si zarezervovat jiný.
Dále je proto třeba z datové sady vyřadit sloupce, které nejsou pro prediktivní model relevantní. Číslo na zádi letadla zřejmě bude mít jen malý vliv na to, zda letadlo přiletí na čas; stejně tak čas, kdy si letenku rezervujete, vám neřekne nic o tom, zda let bude zrušen, odkloněn nebo zpožděn. Naproti tomu plánovaný čas odletu by mohl mít na včasné přílety velký vliv. Většina leteckých společností využívá systém uzlových letišť s návazností na dálkové lety, a proto u odpoledních nebo večerních letů existuje vyšší pravděpodobnost zpoždění než u ranních letů. Na některých velkých letištích se provoz v průběhu dne hromadí, což zvyšuje pravděpodobnost zpoždění letů v pozdějších hodinách.
Pandas poskytuje snadný způsob, jak můžete vyfiltrovat sloupce, které nepotřebujete. V nové buňce na konci poznámkového bloku spusťte následující kód:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()Výstup ukazuje, že datový rámec nyní obsahuje pouze sloupce, které jsou pro model relevantní, a že počet chybějících hodnot se výrazně snížil:
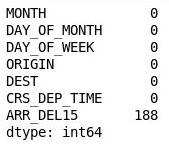
Filtrovaný datový rámec
Jediným sloupcem, který teď obsahuje chybějící hodnoty, je sloupec ARR_DEL15, v němž jsou lety na čas označené číslem 0 a zpožděné lety číslem 1. Pomocí následujícího kódu zobrazte prvních pět řádků s chybějícími hodnotami:
df[df.isnull().values.any(axis=1)].head()Pandas vyjadřuje chybějící hodnoty pomocí řetězce
NaN, což je zkratka pro Not a Number (Nejedná se o číslo). Z výstupu je patrné, že tyto řádky jsou skutečně chybějícími hodnotami ve sloupci ARR_DEL15: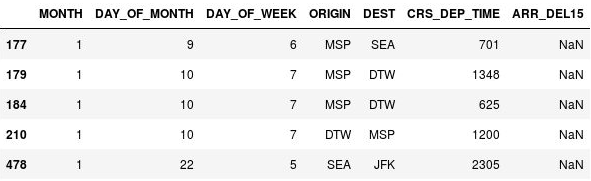
Řádky s chybějícími hodnotami
Důvodem, proč v těchto řádcích chybí hodnoty ARR_DEL15, je to, že všechny odpovídají letům, které byly zrušeny nebo odkloněny. Tyto řádky můžete odebrat tak, že u datového rámce zavoláte dropna. Vzhledem k tomu, že zrušený let nebo let odkloněný na jiné letiště lze považovat za „opožděný“, nahradíme chybějící hodnoty řetězcem 1s pomocí metody fillna.
Pomocí následujícího kódu nahradíte chybějící hodnoty ve sloupci ARR_DEL15 řetězcem 1s a zobrazíte řádky 177 až 184:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Zkontrolujte, že se v řádcích 177, 179 a 184 nahradila zkratka
NaNřetězcem 1s, který označuje, že lety přistály později: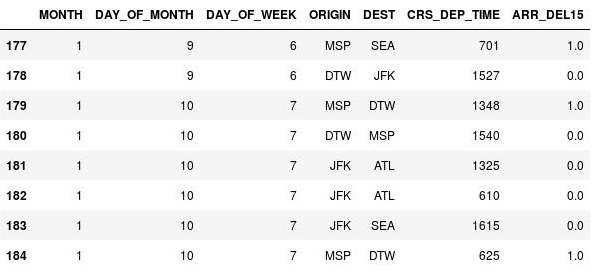
Zkratky NaN nahrazené řetězcem 1s
Datová sada je nyní „čistá“ v tom smyslu, že chybějící hodnoty byly nahrazeny a seznam sloupců byl zúžen na sloupce, které jsou pro model nejrelevantnější. Tím ale nekončíme. Abychom mohli datovou sadu použít při strojovém učení, je třeba provést další přípravné kroky.
Sloupec CRS_DEP_TIME v používané datové sadě představuje plánované časy odletu. Členitost čísel v tomto sloupci, který obsahuje více než 500 jedinečných hodnot, by mohla mít negativní vliv na přesnost v modelu strojového učení. To lze vyřešit pomocí techniky zvané binning, neboli kvantování. Co kdybyste každé číslo v tomto sloupci vydělili číslem 100 a výsledek zaokrouhlili na nejbližší celé číslo? Číslo 1030 by se změnilo na 10, 1925 na 19 atd. V tomto sloupci byste tak získali maximálně 24 samostatných hodnot. Intuitivně to dává smysl, protože pravděpodobně nezáleží na tom, zda let odjíždí v 10:30 nebo 10:40. Záleží na tom, zda odchází v 10:30 nebo 5:30 hodin.
Kromě toho sloupce ORIGIN a DEST v datové sadě obsahují kódy letišť, které představují hodnoty strojového učení zařazené do kategorií. Tyto sloupce je třeba převést na samostatné sloupce obsahující proměnné indikátoru, které se někdy označují jako „fiktivní“ proměnné. Jinými slovy, sloupec ORIGIN obsahující pět letištních kódů je třeba převést na pět sloupců (jeden sloupec pro jedno letiště), aby každý sloupec obsahoval řetězec 1s a 0s označující, zda místem odletu bylo letiště, které daný sloupec reprezentuje. Se sloupcem DEST je třeba naložit obdobně.
V tomto cvičení provedete binning časů odletu ve sloupci CRS_DEP_TIME a pomocí metody get_dummies v Pandasu vytvoříte sloupce indikátorů ze sloupců ORIGIN a DEST.
Pomocí následujícího příkazu zobrazte prvních pět řádků datového rámce:
df.head()Všimněte si, že sloupec CRS_DEP_TIME obsahuje hodnoty v rozmezí 0 až 2359, které vyjadřují vojenský čas.
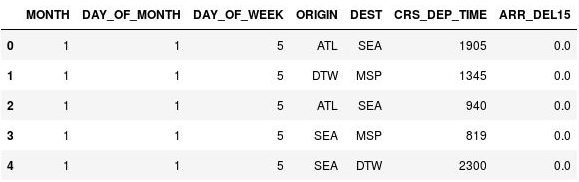
Datový rámec s časy odletů, u nichž neproběhl binning
Pomocí následujících příkazů proveďte binning časů odletů:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Zkontrolujte, že čísla ve sloupci CRS_DEP_TIME nyní spadají do rozsahu 0 až 23:
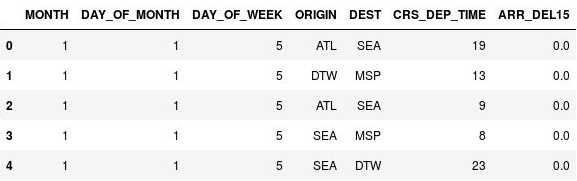
Datový rámec s časy odletů, u nichž proběhl binning
Teď pomocí následujících příkazů vygenerujte sloupce indikátorů ze sloupců ORIGIN a DEST a samotné sloupce ORIGIN a DEST vyřaďte:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Projděte si výsledný datový rámec a všimněte si, že sloupce ORIGIN a DEST byly nahrazeny sloupci, které odpovídají letištním kódům uvedeným v původních sloupcích. Nové sloupce obsahují řetězce 1s a 0s označující, zda příslušné letiště bylo pro let výchozím nebo cílovým letištěm.
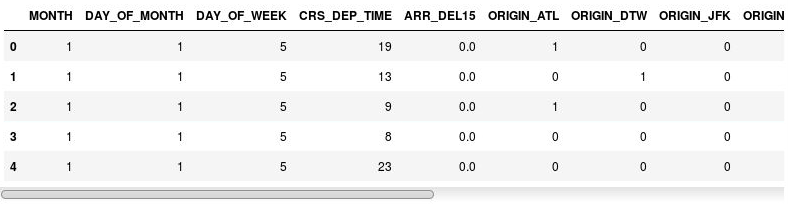
Datový rámec se sloupci indikátoru
K uložení poznámkového bloku použijte příkaz File ->Save a Checkpoint.
Datová sada nyní vypadá zcela jinak než na začátku, ale je optimalizovaná pro použití ve strojovém učení.