Cvičení – streamování dat Kafka do poznámkového bloku Jupyter a okno dat
Cluster Kafka teď zapisuje data do svého protokolu, který je možné zpracovat prostřednictvím strukturovaného streamování Sparku.
Poznámkový blok Sparku je součástí ukázky, kterou jste naklonovali, takže ho musíte nahrát do clusteru Spark, abyste ho mohli použít.
Nahrání poznámkového bloku Pythonu do clusteru Spark
Na webu Azure Portal klikněte na domovské > clustery HDInsight a pak vyberte cluster Spark, který jste právě vytvořili (ne cluster Kafka).
V podokně Řídicí panely clusteru klikněte na poznámkový blok Jupyter.
Po zobrazení výzvy k zadání přihlašovacích údajů zadejte uživatelské jméno správce a zadejte heslo, které jste vytvořili při vytváření clusterů. Zobrazí se web Jupyter.
Klikněte na PySpark a potom na stránce PySpark klikněte na Nahrát.
Přejděte do umístění, kam jste stáhli ukázku z GitHubu, vyberte soubor RealTimeStocks.ipynb, klikněte na Otevřít, potom klikněte na Nahrát a potom klikněte na Aktualizovat v internetovém prohlížeči.
Jakmile se poznámkový blok nahraje do složky PySpark, kliknutím na RealTimeStocks.ipynb otevřete poznámkový blok v prohlížeči.
První buňku v poznámkovém bloku spusťte umístěním kurzoru do buňky a následným kliknutím na Shift+Enter buňku spusťte.
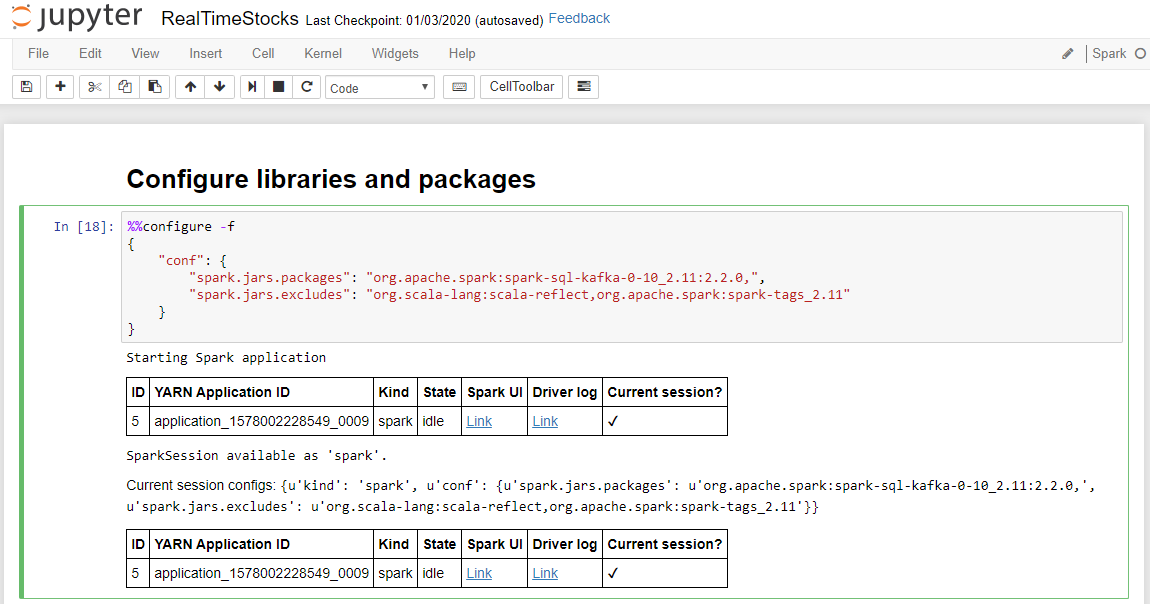
Buňka Konfigurovat knihovny a balíčky se úspěšně dokončí, když zobrazí zprávu o spuštění aplikace Spark a další informace, jak je znázorněno na následujícím titulku obrazovky.
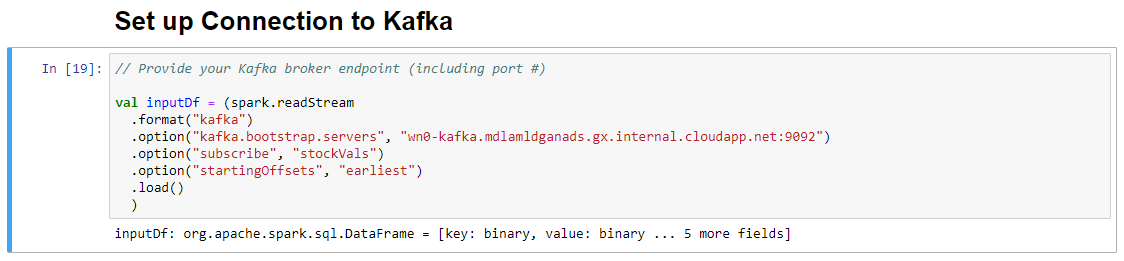
V buňce Nastavit připojení k Systému Kafka na řádku .option("kafka.bootstrap.servers"; "") zadejte zprostředkovatele Kafka mezi druhou sadou uvozovek. Například. .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092") a potom kliknutím na Shift+Enter buňku spusťte.
Při zobrazení vstupní hodnoty zprávy se úspěšně dokončí připojení k buňce Kafka: org.apache.spark.sql.DataFrame = [klíč: binární, hodnota: binární... 5 dalších polí]. Spark ke čtení dat používá rozhraní API readStream.
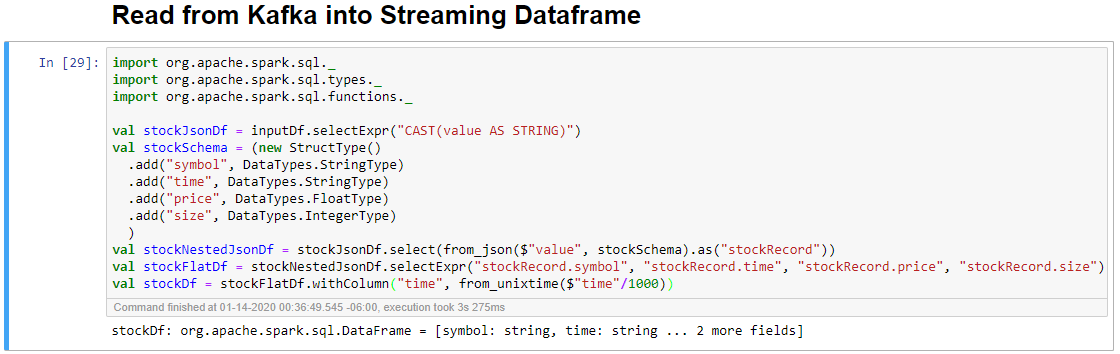
Vyberte buňku Číst ze systému Kafka do buňky streamovaného datového rámce a potom kliknutím na Shift+Enter buňku spusťte.
Buňka se úspěšně dokončí, když zobrazí následující zprávu: stockDf: org.apache.spark.sql.DataFrame = [symbol: řetězec, čas: řetězec ... 2 další pole]
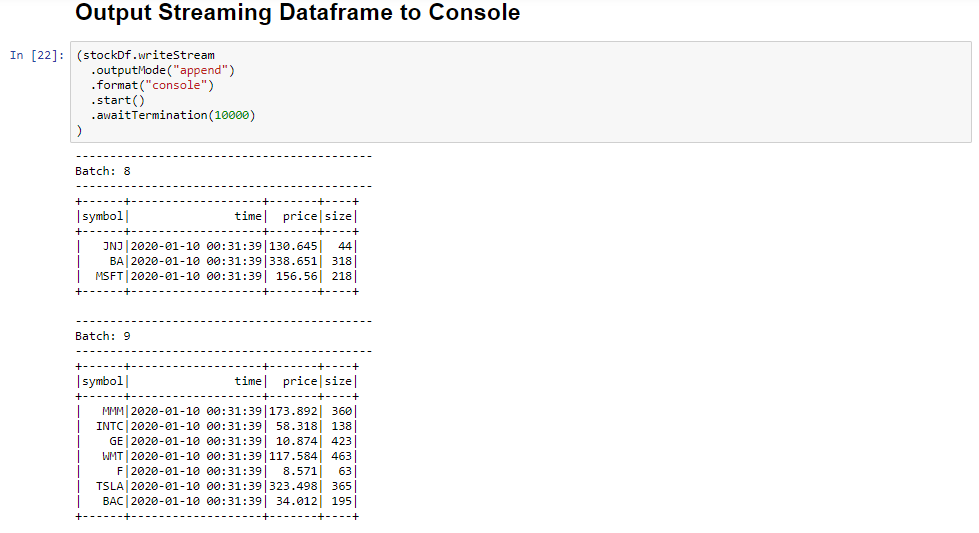
Vyberte výstupní datový rámec streamování do buňky konzoly a kliknutím na Shift+Enter buňku spusťte.
Buňka se úspěšně dokončí, když zobrazí podobné informace. Výstup zobrazuje hodnotu pro každou buňku, jak byla předána v mikrodávce, a existuje jedna dávka za sekundu.
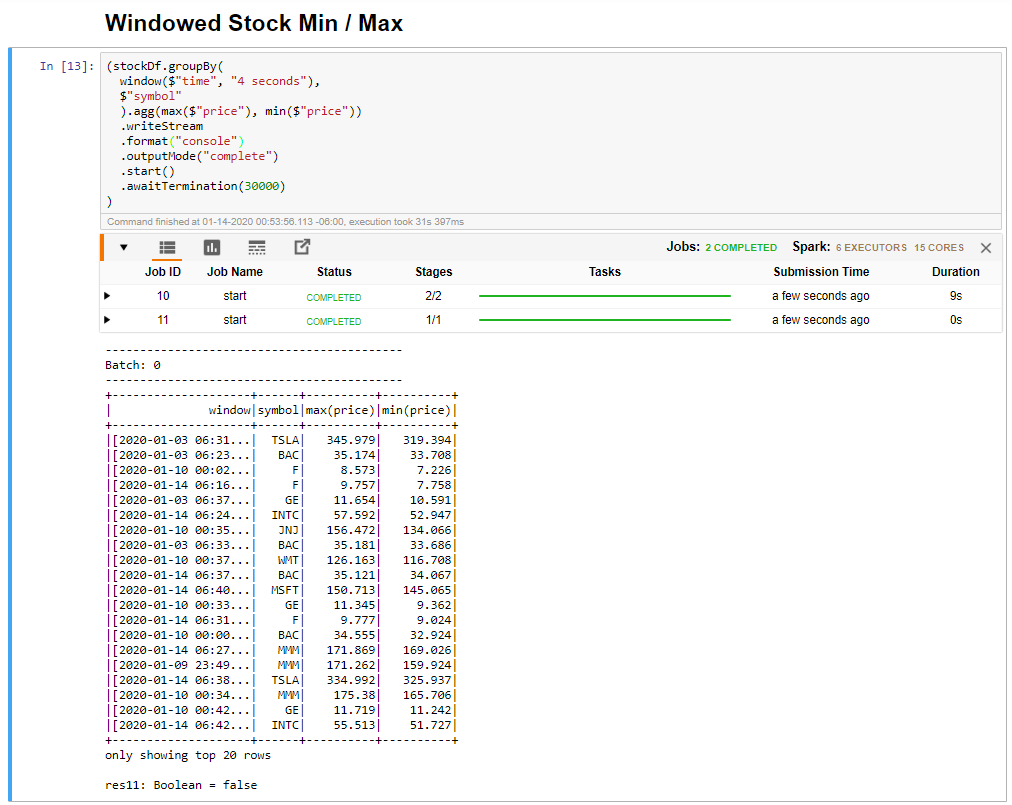
Vyberte buňku Min/ Max s oknem a potom kliknutím na Shift +Enter buňku spusťte.
Buňka se úspěšně dokončí, když poskytne maximální a minimální cenu pro každou akcii v 4sekundovém okně, které je definováno v buňce. Jak je popsáno v předchozí lekci, poskytování informací o konkrétních časových obdobích je jednou z výhod, které získáte pomocí strukturovaného streamování Sparku.
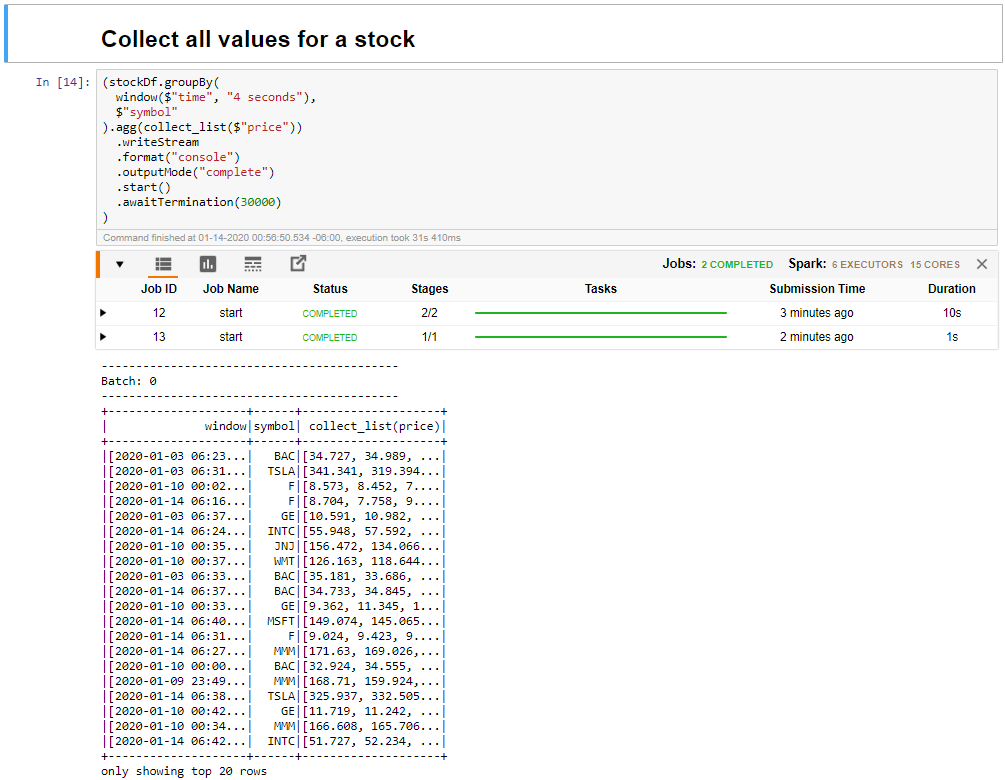
Vyberte možnost Shromáždit všechny hodnoty akcií v buňce okna a potom kliknutím na Shift +Enter buňku spusťte.
Buňka se úspěšně dokončí, když poskytuje tabulku hodnot pro akcie v tabulce. Výstupnímode je dokončen, takže se zobrazí všechna data.
V této lekci jste nahráli poznámkový blok Jupyter do clusteru Spark, připojili jste ho ke clusteru Kafka, vypíšete streamovaná data vytvořená souborem producenta Pythonu do poznámkového bloku Sparku, definovali jste okno pro streamovaná data a zobrazili jste v tomto okně vysoké a nízké ceny akcií a zobrazili jste všechny hodnoty akcií v tabulce. Blahopřejeme, úspěšně jste provedli strukturované streamování pomocí Sparku a Kafka!