Streamování dat pomocí Apache Kafka
Apache Kafka vytvořil LinkedIn v roce 2010 s cílem přesunout data ve velmi velkém měřítku s velmi nízkou latencí s vysokou úrovní odolnosti proti chybám. LinkedIn pak projekt daroval nadace Apache v roce 2012, ale LinkedIn stále používá Kafka v celém svém ekosystému ke sledování aktivit uživatelů, výměně zpráv a shromažďování metrik.
Kafka je distribuovaná streamovací platforma navržená tak, aby:
- Zjednodušení datových kanálů
- Zpracování velkých objemů dat ve vzoru streamování
- Podpora systémů v reálném čase a dávkových systémech
- Masivně škálovat horizontálně
Nejprve se seznámíme s čistým Apache Kafka a pak o Platformě Kafka ve službě Azure HDInsight.
Komponenty Kafka
Než se podíváme na to, jak Kafka funguje, podíváme se na role některých klíčových komponent Kafka a na to, jak dohromady poskytují vysoce škálovatelný systém zasílání zpráv odolný proti chybám.
Zprostředkovatel
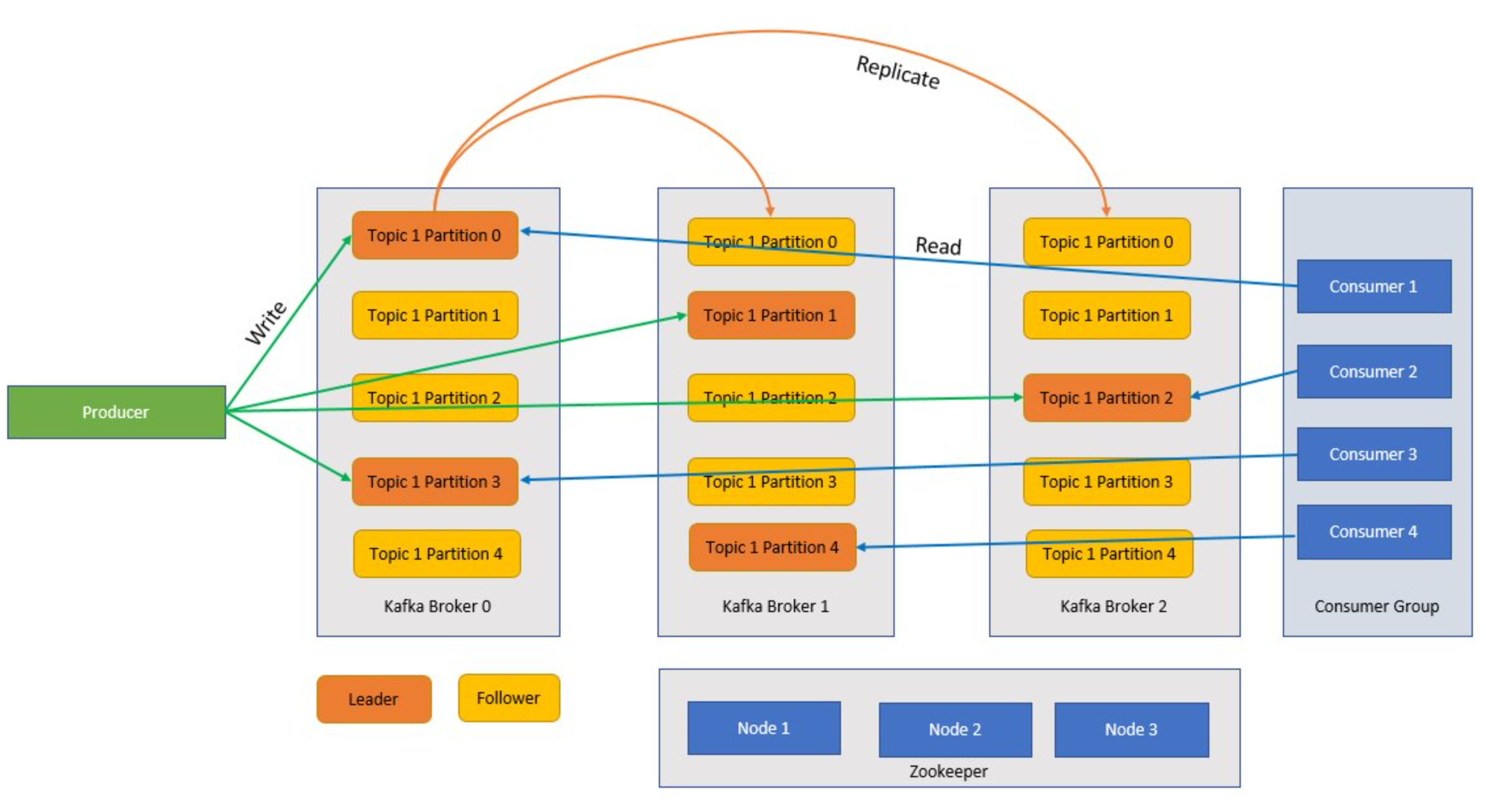
Kafka je clusterová služba a jeden cluster Kafka se také nazývá zprostředkovatel. Zprostředkovatelé přijímají zprávy od producentů a ukládají tyto zprávy na disk. Zprostředkovatel také reaguje na načítání požadavků od příjemců. V rámci clusteru zprostředkovatelů slouží jeden zprostředkovatel jako kontroler a zodpovídá za operace správy a přiřazování oddílů zprostředkovatelům.
Zpráva
Jednotka dat v clusteru Kafka. Zprávy ve většině případů jsou páry klíč-hodnota.
Témata a oddíly
Témata a oddíly jsou kategorie zpráv v systému Kafka. Témata jsou obvykle rozdělena do řady oddílů, které se mají zlepšit v celém prostředí s doporučeným minimem tří oddílů. Zprávy se zapisují do oddílu tématu pouze způsobem připojení. Oddíly se dále replikují napříč několika zprostředkovateli, aby se zlepšila redundance v případě selhání zprostředkovatele. Oddíly umožňují paralelní čtení témat, protože umožňují rozdělení dat mezi několik zprostředkovatelů. Existuje replika vedoucího serveru, která zpracovává všechny žádosti o čtení i zápis a sledující se replikují od vedoucího serveru. V případě selhání vedoucího serveru se stane jednou z replik vedoucího serveru.
Producenti a spotřebitelé
Producenti a příjemci jsou klienti, kteří vytvářejí a využívají zprávy ze systému Kafka. Producenti publikují nové zprávy a směrují je na konkrétní téma. Příjemci mohou být také navrženi tak, aby zapisovat do konkrétního oddílu tématu. Uživatelé se zase přihlásí k odběru jednoho nebo více témat a čtou zprávy z těchto témat.
Skupiny příjemců
Jeden nebo více příjemců může spolupracovat jako skupina a využívat zprávy jako skupinu. Pokud se počet příjemců rovná počtu oddílů tématu, každý příjemce spotřebovává z jednoho oddílu tématu, který vytváří paralelismus.
Uchovávání
Zprávy v systému Kafka je možné trvale uchovávat v clusteru Kafka po předdefinované časové období. Po dosažení limitů uchovávání informací může Kafka tyto zprávy vypršet a odstranit.
Odsazení
Posun je jednoduše pozice zprávy v oddílu. Aktualizace aktuální pozice v oddílu při zpracování zpráv se nazývá potvrzení. Po zpracování zprávy kafka potvrdí posun zprávy do speciálního interního tématu Kafka. Když producent publikuje zprávu do oddílu, přepošla se na vedoucího. Vedoucí přidá zprávu do protokolu potvrzení a zvýší posun zprávy. Posun zprávy je způsob identifikace zpráv v rámci tématu. Zpráva je dostupná pouze pro příjemce poté, co byla zpráva potvrzena do clusteru.
Zookeeper
Zookeeper je koordinační služba a v clusteru Kafka zookeeper poskytuje zobrazení stavu clusteru v synchronizaci. Kafka používá Zookeeper k volbě vedoucího mezi zprostředkovatelskými oddíly a oddíly témat. Kafka používá Zookeeper ke správě zjišťování služeb pro zprostředkovatele Kafka, které tvoří cluster. Zookeeper odesílá změny topologie do systému Kafka, takže každý uzel v clusteru ví, kdy se nový zprostředkovatel připojil, zemřel zprostředkovatel, odebral se téma nebo se přidalo téma.
Jak se to všechno spojí?
Aplikace (označované také jako producenti) odesílají zprávy do zprostředkovatele Kafka a tyto zprávy zpracovávají jeden nebo mnoho příjemců. Zprávy v clusteru jsou kategorizovány podle témat. Zákazník může například vytvořit téma "Prodej", které odešle všechny zprávy, které jsou relevantní pro prodej a tak dále. S rostoucí velikostí témat se zvyšujícími se zprávami jsou rozděleny do oddílů a tyto oddíly se dále replikují napříč zprostředkovateli Kafka kvůli redundanci. Oddíly jsou kategorizovány jako vedoucí a sledující. Vedoucí oddíl se zapisuje a čte z nich, zatímco následující oddíly jsou jednoduše repliky, které dohoní stav vedoucího serveru. Pokud chcete určit, do kterého oddílu se má zapisovat a číst, musí producenti a spotřebitelé vědět, které oddíly jsou navrženy jako vedoucí. Uzly Zookeeper spravují stav clusteru Kafka a mimo jiné volí vedoucí oddíly a poskytují tyto informace producentům a příjemcům.
Kafka zaručuje, že zprávy s oddílem jsou seřazené ve stejném pořadí, ve které přišly. Konkrétní zprávu lze jednoznačně identifikovat prostřednictvím posunu, což je jeho pozice v rámci oddílu. Příjemce čte zprávy z oddílů a následného zpracování, potvrďte posun označující, že zpráva byla úspěšně zpracována. Kafka ukládá všechny svoje záznamy na disk a udržuje trvalost zpráv. V případě, že se příjemce z nějakého důvodu přeruší a zpracování se zastaví, Kafka tyto zprávy zachovají po předem stanovenou dobu uchovávání a po návratu do režimu online může příjemce restartovat zpracování z potvrzeného posunu, kde skončil před přerušením.
Témata Kafka
Téma Kafka je informační kanál nebo fronta, ve které se ukládají a publikují zprávy. Producenti odsílali zprávy do témat a příjemci si je přečetli z témat. Každý uzel v zprostředkovateli Kafka může obsahovat více témat.
Jaké jsou výhody Kafka ve službě Azure HDInsight?
Opensourcová verze Kafka nabízí mnoho funkcí, ale při nastavování je toho hodně práce. Azure HDInsight přináší do Azure to nejlepší z opensourcových analytických architektur a usnadňuje zákazníkům nastavení opensourcových clusterů během několika minut, místo toho, aby tyto clustery nastavily týdny nebo měsíce, a můžete je okamžitě použít. HDInsight je také připravený pro podniky s následujícími výhodami:
- Jedná se o spravovanou službu, která poskytuje zjednodušený proces konfigurace. Výsledkem je konfigurace otestovaná a podporovaná Microsoftem.
- Microsoft poskytuje smlouvu o úrovni služeb (SLA) o 99,9% dostupnosti Sparku a Kafka.
- Jako záložní úložiště pro platformu Kafka se používají Spravované disky Azure. Spravované disky může poskytovat až 16 TB úložiště na zprostředkovatele Kafka s několika zprostředkovateli Kafka.
- HDInsight nabízí nejlepší podnikové zabezpečení s virtuálními sítěmi, jemně odstupňované zabezpečení pomocí Apache Rangeru a šifrování BYOK (Bring Your Own Key) pro neaktivní uložená data.
- Dodržování předpisů pro HIPAA, SOC a PCI
- Možnost nasadit kompletní streamovací kanály se Sparkem a úložištěm prostřednictvím automatizovaných šablon Azure Resource Manageru (ARM) ve stejné virtuální síti.
- Vysokou dostupnost lze dosáhnout pomocí nástroje Kafka MirrorMaker, který může využívat záznamy z témat v primárním clusteru a pak vytvořit místní kopii v sekundárním clusteru.
- HDInsight umožňuje změnit počet pracovních uzlů (které jsou hostiteli zprostředkovatele Kafka) po vytvoření clusteru. Škálování lze provádět z webu Azure Portal, prostředí Azure PowerShell a dalších rozhraní správy Azure. V případě platformy Kafka byste po operacích škálování měli obnovit rovnováhu replik oddílů. Díky vyrovnání rovnováhy oddílů může platforma Kafka využívat nový počet pracovních uzlů.
- Protokoly služby Azure Monitor je možné použít k monitorování Kafka ve službě HDInsight. Protokoly služby Azure Monitor obsahují informace o úrovni virtuálních počítačů, jako jsou metriky disků a síťových adaptérů a metriky JMX ze systému Kafka.