Kombinování a optimalizace dat
Organizace často kompletují různé typy informací z mnoha zdrojů. Informace se ukládají do velkého počtu tabulek. Někdy může být potřeba spojit tabulky na základě logických relací mezi nimi, abyste mohli provádět hlubší analýzu nebo vytváření sestav. Ve scénáři maloobchodní společnosti používáte tabulky pro zákazníky, produkty a informace o prodeji.
V tomto modulu se dozvíte o různých způsobech kombinování dat v dotazech Kusto, abyste členům týmu poskytli informace, které potřebují ke zvýšení povědomí o produktech a růstu prodeje.
Pochopení vašich dat
Než začnete psát dotazy, které kombinují informace z tabulek, musíte porozumět datům. Při práci s dotazy Kusto si chcete tabulky představit jako široce patřící do jedné ze dvou kategorií:
- Tabulky faktů: Tabulky, jejichž záznamy jsou neměnné fakta, jako je tabulka SalesFact ve scénáři maloobchodní společnosti. Vtěchtoch Záznamy zůstanou v tabulce, dokud nebudou odebrány a nebudou aktualizovány.
- Tabulky dimenzí: Tabulky, jejichž záznamy jsou proměnlivé dimenze, jako jsou tabulky Zákazníci a Produkty ve scénáři maloobchodní společnosti. Tyto tabulky obsahují referenční data, jako jsou vyhledávací tabulky z identifikátoru entity a jejich vlastnosti. Tabulky dimenzí se pravidelně neaktualizují s novými daty.
V našem scénáři maloobchodní společnosti použijete tabulky dimenzí k obohacení tabulky SalesFact dalšími informacemi nebo poskytnutím dalších možností pro filtrování dat pro dotazy.
Chcete také porozumět objemům dat, se kterými pracujete, a jejich strukturou nebo schématem (názvy a typy sloupců). Spuštěním následujících dotazů získáte tyto informace nahrazením TABLE_NAME názvem tabulky, kterou zkoumáte:
Pokud chcete získat počet záznamů v tabulce, použijte
countoperátor:TABLE_NAME | countPokud chcete získat schéma tabulky, použijte
getschemaoperátor:TABLE_NAME | getschema
Spuštění těchto dotazů na tabulky faktů a dimenzí ve scénáři maloobchodní společnosti poskytuje informace jako v následujícím příkladu:
| Table | Záznamy | Schéma |
|---|---|---|
| SalesFact | 2,832,193 | - SalesAmount (real) - TotalCost (real) - DateKey (datetime) - ProductKey (dlouhý) - CustomerKey (long) |
| Zákazníci | 18,484 | - CityName (řetězec) - CompanyName (řetězec) – ContinentName (řetězec) - CustomerKey (long) - Education (řetězec) - FirstName (řetězec) - Pohlaví (řetězec) - LastName (řetězec) - MaritalStatus (řetězec) - Zaměstnání (řetězec) – RegionCountryName (řetězec) – StateProvinceName (řetězec) |
| Produkty | 2,517 | – ProductName (řetězec) - Výrobce (řetězec) - ColorName (řetězec) – ClassName (řetězec) – ProductCategoryName (řetězec) – ProductSubcategoryName (řetězec) - ProductKey (dlouhý) |
V tabulce jsme zvýraznili jedinečné identifikátory CustomerKey a ProductKey , které slouží ke kombinování záznamů mezi tabulkami.
Principy dotazů s více tabulkami
Po analýze dat je potřeba porozumět tomu, jak kombinovat tabulky a poskytovat potřebné informace. Dotazy Kusto poskytují několik operátorů, které můžete použít ke kombinování dat z více tabulek, včetně lookupoperátorů , joina union operátorů.
Operátor join sloučí řádky dvou tabulek odpovídajícími hodnotami zadaných sloupců z každé tabulky. Výsledná tabulka závisí na typu spojení, které používáte. Pokud například použijete vnitřní spojení, tabulka má stejné sloupce jako levá tabulka (někdy označovaná jako vnější tabulka), plus sloupce z pravé tabulky (někdy označované jako vnitřní tabulka). Další informace o typech spojení najdete v další části. Nejlepšího výkonu dosáhnete, pokud je jedna tabulka vždy menší než druhá, použijte ji jako levou stranu operátoru join .
Operátor lookup je speciální implementace operátoru join , která optimalizuje výkon dotazů, ve kterých je tabulka faktů obohacena o data z tabulky dimenzí. Rozšiřuje tabulku faktů o hodnoty, které jsou vyhledány v tabulce dimenzí. Pro zajištění nejlepšího výkonu systém ve výchozím nastavení předpokládá, že levá tabulka je větší (fakta) a pravá tabulka je menší (dimenze). Tento předpoklad je přesně opakem předpokladu používaného operátorem join .
Operátor union vrátí všechny řádky ze dvou nebo více tabulek. Je užitečné, když chcete zkombinovat data z více tabulek.
Funkce materialize() ukládá výsledky do mezipaměti při provádění dotazu pro následné opakované použití v dotazu. Je to jako pořízení snímku výsledků poddotazu a jeho použití několikrát v rámci dotazu. Tato funkce je užitečná při optimalizaci dotazů pro scénáře, ve kterých výsledky:
- Výpočet je nákladný
- Jsou nedeterministické
Za chvíli se dozvíte více o různých operátorech slučování tabulek a materialize() funkci a o tom, jak je používat.
Druhy spojení
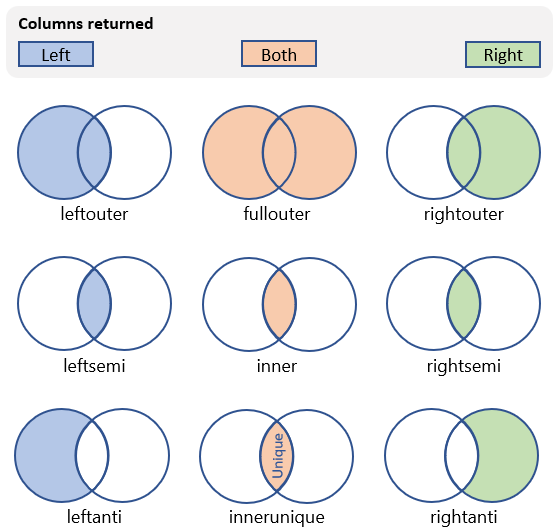
Existuje mnoho různých druhů spojení, které lze provést, které ovlivňují schéma a řádky ve výsledné tabulce. Následující tabulka uvádí typy spojení podporovaných dotazovací jazyk Kusto a schématem a řádky, které vrací:
| Typ spojení | Popis | Ilustrace |
|---|---|---|
innerunique (výchozí) |
Vnitřní spojení s odstraněním duplicitních dat na levé straně Schéma: Všechny sloupce z obou tabulek, včetně odpovídajících klíčů Řádky: Všechny řádky odstraněné duplicitními daty z levé tabulky, které odpovídají řádkům z pravé tabulky |
|
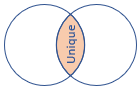
inner |
Standardní vnitřní spojení Schéma: Všechny sloupce z obou tabulek, včetně odpovídajících klíčů Řádky: Pouze odpovídající řádky z obou tabulek |
|
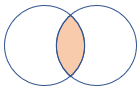
leftouter |
Levé vnější spojení Schéma: Všechny sloupce z obou tabulek, včetně odpovídajících klíčů Řádky: Všechny záznamy z levé tabulky a pouze odpovídající řádky z pravé tabulky |
|
rightouter |
Pravé vnější spojení Schéma: Všechny sloupce z obou tabulek, včetně odpovídajících klíčů Řádky: Všechny záznamy z pravé tabulky a pouze odpovídající řádky z levé tabulky |
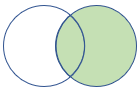
|
fullouter |
Úplné vnější spojení Schéma: Všechny sloupce z obou tabulek, včetně odpovídajících klíčů Řádky: Všechny záznamy z obou tabulek s chybějícími buňkami naplněnými hodnotou null |
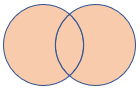
|
leftsemi |
Levé střední spojení Schéma: Všechny sloupce z levé tabulky Řádky: Všechny záznamy z levé tabulky, které odpovídají záznamům z pravé tabulky |
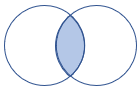
|
leftanti, , antileftantisemi |
Levá anti join a polo varianta Schéma: Všechny sloupce z levé tabulky Řádky: Všechny záznamy z levé tabulky, které neodpovídají záznamům z pravé tabulky |
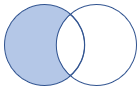
|
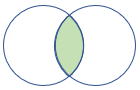
rightsemi |
Pravé střední spojení Schéma: Všechny sloupce z pravé tabulky Řádky: Všechny záznamy z pravé tabulky, které odpovídají záznamům z levé tabulky |
|
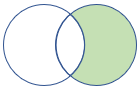
rightanti, rightantisemi |
Pravá anti join a polo varianta Schéma: Všechny sloupce z pravé tabulky Řádky: Všechny záznamy z pravé tabulky, které neodpovídají záznamům z levé tabulky |
|
Všimněte si, že výchozí druh spojení je inneruniquea není nutné ho zadat. Osvědčeným postupem je však vždy explicitně určit typ spojení, aby bylo jasné.
Během procházení tohoto modulu se také dozvíte o funkcích arg_min() a arg_max() agregaci, operátoru as jako alternativě let k příkazu a startofmonth() funkci, která vám pomůže se seskupováním dat podle měsíců.