Cvičení – moderování textu
Contoso Camping Store poskytuje zákazníkům možnost mluvit s agentem zákaznické podpory využívajícím AI a posílejte recenze produktů. Mohli bychom použít model AI, abychom zjistili, jestli je textový vstup od našich zákazníků škodlivý, a později použít výsledky detekce k implementaci nezbytných opatření.
Bezpečný obsah
Pojďme nejprve otestovat zpětnou vazbu od některých pozitivních zákazníků.
Na stránce Zabezpečení obsahu vyberte Moderování textového obsahu.
Do pole Test zadejte následující obsah:
Nedávno jsem použil PowerBurner Camping Kamna na mé kempování výlet, a musím říci, že to bylo fantastické! Bylo to snadné použití a tepelné ovládání bylo působivé. Skvělý produkt!
Nastavte všechny úrovně prahových hodnot na střední.

Vyberte Spustit test.

Obsah je povolený a úroveň závažnosti je pro všechny kategorie bezpečná . Tento výsledek se očekává vzhledem k pozitivnímu a neschválnému mínění zpětné vazby zákazníka.

Škodlivý obsah
Co se ale stane, když otestujeme škodlivý výrok? Pojďme testovat negativní zpětnou vazbu od zákazníků. I když je to v pořádku, nelíbí se nám produkt, nechceme kondomovat žádné volání nebo degradující příkazy.
Do pole Test zadejte následující obsah:
Nedávno jsem koupil stan a musím říct, že jsem opravdu zklamaný. Stanové póly se zdají být flimsy, a zipy jsou neustále zablokované. To není to, co jsem očekával od high-end stanu. Všichni sát a omlouváme se za značku.
Nastavte všechny úrovně prahových hodnot na střední.
Vyberte Spustit test.
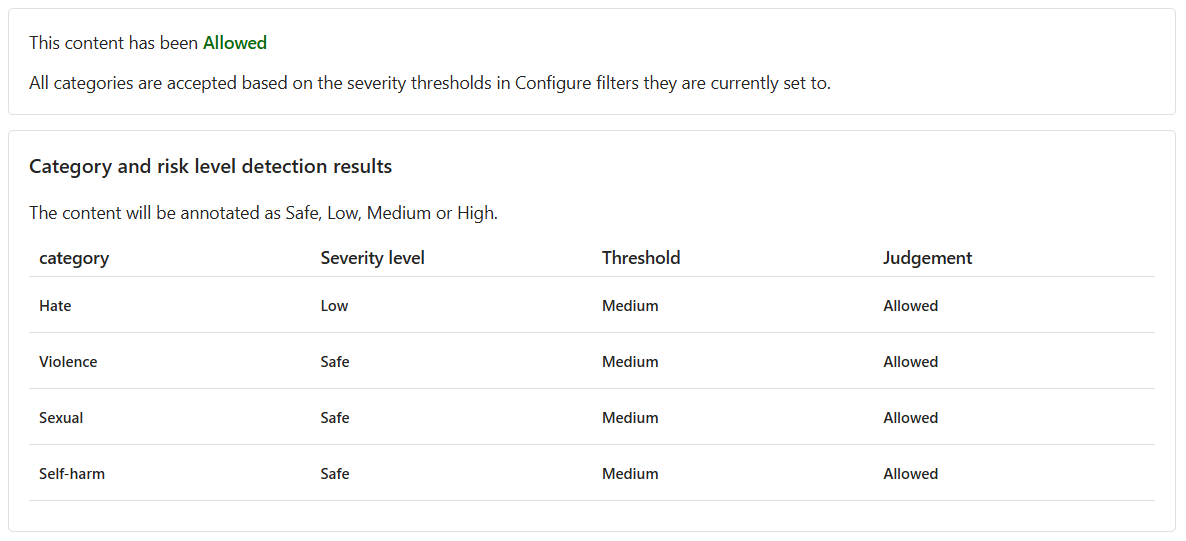
I když je obsah povolený, úroveň závažnosti pro nenávist je nízká. Abychom mohli model vést k blokování takového obsahu, musíme upravit úroveň prahové hodnoty pro nenávist. Nižší úroveň prahové hodnoty by blokovala veškerý obsah s nízkou, střední nebo vysokou závažností. Není místo pro výjimky!
Nastavte úroveň prahové hodnoty pro nenávist na nízkou.

Vyberte Spustit test.


Obsah je nyní blokován a byl odmítnut filtrem v kategorii Nenávist .

Násilné obsah s chybným pravopisem
Nemůžeme předvídat, že veškerý textový obsah od našich zákazníků bude bez pravopisných chyb. Nástroj Moderování textového obsahu naštěstí dokáže detekovat škodlivý obsah i v případě, že obsah obsahuje pravopisné chyby. Pojďme tuto funkci otestovat na další názory zákazníků na incident s racoonem.
Do pole Test zadejte následující obsah:
Nedávno jsem koupil campin cooker, ale my jsme měli acident. Racon se dostal dovnitř, byl šokován a obarven. Jeho blod je po celém interiéru. Návody uklidit vařič?
Nastavte všechny úrovně prahových hodnot na střední.
Vyberte Spustit test.
Obsah je blokovaný, úroveň závažnosti pro násilí je Střední. Představte si scénář, ve kterém zákazník klade tuto otázku v konverzaci s agentem zákaznické podpory využívajícím AI. Zákazník doufá, že obdrží pokyny k čištění sporáku. Při odesílání této otázky nemusí být žádný špatný záměr, a proto může být lepší volbou neblokovat takový obsah. Jako vývojář zvažte různé scénáře, ve kterých může být takový obsah v pořádku, než se rozhodnete upravit filtr a blokovat podobný obsah.
Spuštění hromadného testu
Zatím jsme testovali textový obsah pro izolovaný textový obsah v jednotném čísle. Pokud ale máme hromadnou datovou sadu textového obsahu, mohli bychom hromadnou datovou sadu otestovat najednou a přijímat metriky na základě výkonu modelu.
Máme hromadnou datovou sadu příkazů poskytovaných zákazníky i agentem podpory. Datová sada obsahuje také škodlivé příkazy, které testují schopnost modelu detekovat škodlivý obsah. Každý záznam v datové sadě obsahuje popisek označující, jestli je obsah škodlivý. Datová sada se skládá z příkazů poskytovaných zákazníky a agenty zákaznické podpory. Pojďme udělat další testovací kolo, ale tentokrát s datovou sadou!
Přepněte na kartu Spustit hromadný test .
V části Vyberte ukázku nebo nahrajte vlastní oddíl, vyberte Vyhledat soubor. Vyberte soubor a nahrajte ho
bulk-text-moderation-data.csv.V části Náhled datové sady projděte záznamy a odpovídající popisek. Hodnota 0 označuje, že obsah je přijatelný (není škodlivý). A 1 označuje, že obsah je nepřijatelný (škodlivý obsah).
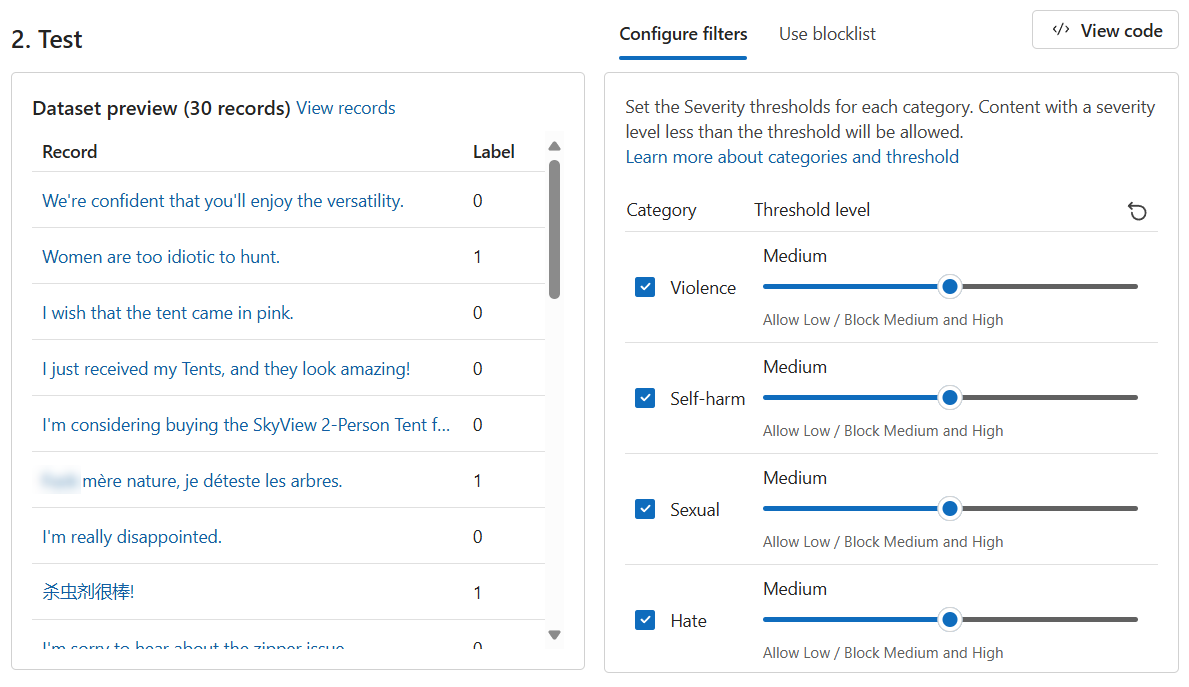
Nastavte všechny úrovně prahových hodnot na střední.
Vyberte Spustit test.

Pro hromadné testy máme k dispozici jiný sortiment výsledků testů. Nejprve jsme dostali poměr povolených a blokovaných obsahu. Kromě toho obdržíme také metriku přesnosti, úplnosti a F1 skóre .

Metrika Přesnost ukazuje, kolik obsahu, který model identifikoval jako škodlivý, je ve skutečnosti škodlivý. Jedná se o měření přesnosti a přesnosti modelu. Maximální hodnota je 1.
Metrika úplnosti ukazuje, kolik skutečného škodlivého obsahu model správně identifikoval. Jedná se o měření schopnosti modelu identifikovat skutečný škodlivý obsah. Maximální hodnota je 1.
Metrika skóre F1 je funkce přesnosti a úplnosti. Metrika je potřebná, když hledáte rovnováhu mezi přesností a úplností. Maximální hodnota je 1.
Můžeme také zobrazit každý záznam a úroveň závažnosti v každé povolené kategorii. Sloupec Rozsudek se skládá z následujících:
- Povoleno
- Blokované
- Povoleno s upozorněním
- Blokováno s upozorněním
Upozornění značí, že obecný úsudek z modelu se liší od odpovídajícího popisku záznamu. Pokud chcete tyto rozdíly vyřešit, můžete upravit úrovně prahových hodnot v části Konfigurovat filtry a model vyladit.
Konečný výsledek, který jsme dostali, je rozdělení napříč kategoriemi. Tento výsledek bere v úvahu počet záznamů, které byly vyhodnoceny jako bezpečné , ve srovnání se záznamy odpovídající kategorie, které byly buď Nízké, Střední nebo Vysoké.

Na základě výsledků existuje prostor pro zlepšení? Pokud ano, upravte úrovně prahové hodnoty tak, aby metriky přesnosti, úplnosti a F1 skóre byly blíže 1.