Optimalizace zdrojového systému – pokročilé
Tyto pokročilejší pokyny můžou být užitečné pro zdrojový export systémů VLDB:
Rozdělení tabulky ID řádku Oracle
SAP vydal SAP Note #1043380, který obsahuje skript, který převádí klauzuli WHERE v souboru WHR na hodnotu ID ŘÁDKU. Alternativně nejnovější verze SAPInst automaticky generují rozdělené soubory WHR ID řádku, pokud je SWPM nakonfigurovaná pro migraci Oracle do Oracle R3load. Soubory STR a WHR generované SWPM jsou nezávislé na operačním systému a databázi (stejně jako všechny aspekty procesu migrace OS/DB).
Poznámka k OSS obsahuje příkaz "Rozdělení tabulky ROWID nelze použít, pokud je cílová databáze databáze mimo databázi Oracle". Technicky vzato jsou soubory s výpisem paměti R3 nezávislé na databázi a operačním systému. Při importu ale není možné na SQL Serveru restartovat balíček. V tomto scénáři je potřeba vynechat celou tabulku a restartovat všechny balíčky tabulky. Vždy se doporučuje ukončovat úlohy načítání R3 pro konkrétní rozdělenou tabulku, zkrátit tabulku a restartovat celý proces importu, pokud jeden rozdělený R3load přeruší. Důvodem je to, že proces obnovení integrovaný do R3load zahrnuje provádění příkazů DELETE po řádcích k odebrání záznamů načtených procesem R3load, který přeruší. To je pomalé a často způsobí blokování a zamykání situací v databázi. Prostředí ukázalo, že je rychlejší spustit import této konkrétní tabulky od začátku, a proto omezení uvedené v SAP Note #1043380 není omezení.
ID ŘÁDKU má nevýhodu při výpočtu rozdělení, které je nutné provést během výpadku – viz SAP Note #1043380.
Paralelní vytvoření několika klonů zdrojové databáze a exportu
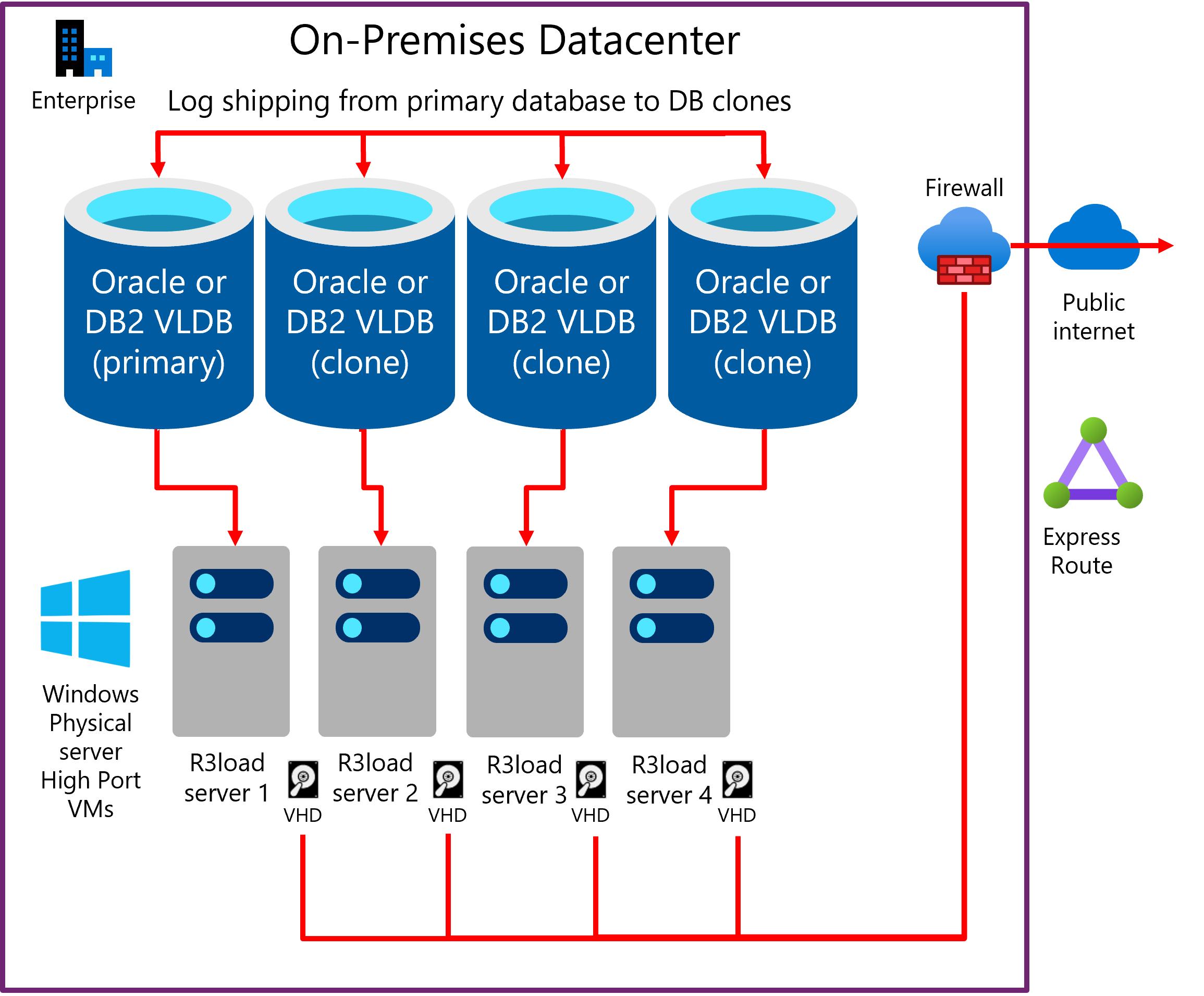
Jednou z metod zvýšení výkonu exportu je export z více kopií stejné databáze. Pokud je základní infrastruktura včetně serverů, sítí a úložiště škálovatelná, je tento přístup obvykle lineární škálovatelný. Export ze dvou kopií stejné databáze je dvakrát rychlejší, čtyři kopie jsou čtyřikrát rychlejší. Nástroj Sledování migrace je nakonfigurovaný tak, aby exportoval podle vybraného počtu tabulek z každého klonu databáze. V následujícím případě se úloha exportu distribuuje přibližně 25 % na každém ze čtyř databázových serverů.
- DB server 1 a export serveru 1 – vyhrazený pro největší tabulky 1–4 (v závislosti na tom, jak nerovnoměrná distribuce dat je ve zdrojové databázi)
- DB server 2 a export serveru 2 – vyhrazené pro tabulky s rozdělením tabulek
- DATABÁZOVÝ server 3 a export serveru 3 – vyhrazený pro tabulky s rozdělením tabulek
- DB server 4 a export serveru 4 – všechny zbývající tabulky
Je třeba dbát na to, aby byly databáze přesně synchronizované, jinak by mohla dojít ke ztrátě dat nebo nekonzistence dat. Pokud jsou zadané kroky přesně dodrženy, integrita dat se zachová.
Technika je jednoduchá a levná se standardním komoditní hardwarem Intel, ale je také možná pro zákazníky, kteří používají proprietární hardware UNIX. Podstatné hardwarové prostředky jsou bezplatné uprostřed projektu migrace operačního systému nebo databáze, když už se do Azure přesunuly systémy sandboxu, vývoje, kontroly kvality, školení a zotavení po havárii. Neexistuje žádný striktní požadavek, aby servery klonování měly identické hardwarové prostředky. Díky dostatečnému výkonu procesoru, paměti RAM, disku a sítě zvyšuje přidání každého klonu výkon.
Pokud se stále vyžaduje další výkon exportu, otevřete incident SAP v BC-DB-MSS, aby se zvýšil výkon exportu (pouze pokročilí konzultanti).
Postup implementace několika paralelních exportů je následující:
- Zálohujte primární databázi a obnovte na n počet serverů (kde n = počet klonů). V tomto příkladu předpokládejme, že n = 3 servery tvoří celkem čtyři databázové servery.
- Obnovte zálohu na tři servery.
- Nastavte odesílání protokolů z primárního zdrojového databázového serveru na tři cílové servery klonování.
- Sledujte přesouvání protokolů po několik dní a ujistěte se, že doprava protokolů spolehlivě funguje.
- Na začátku výpadku vypněte všechny aplikační servery SAP s výjimkou PAS. Ujistěte se, že je zastavené veškeré dávkové zpracování a veškerý provoz RFC je zastavený.
- V transakci SM02 zadejte text "Checkpoint PAS Running". Tím se aktualizuje průvodce odstraňováním potíží s tabulkou.
- Zastavte primární aplikační server. SAP je teď vypnutý. Ve zdrojové databázi nemůže dojít k žádné další aktivitě zápisu. Ujistěte se, že ke zdrojové databázi není připojená žádná aplikace, která není SAP (nikdy by neměla existovat, ale na úrovni databáze zkontrolujte žádné relace jiného systému než SAP).
- Spusťte tento dotaz na primárním databázovém serveru:
SELECT EMTEXT FROM [schema].TEMSG; - Spusťte nativní příkaz na úrovni DBMS:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(přesná syntaxe závisí na zdrojové databázi DBMS. VLOŽIT do EMTEXT) - Zastavení automatického zálohování transakčních protokolů Na primárním databázovém serveru ručně spusťte jednu poslední zálohu transakčního protokolu. Ujistěte se, že se záloha protokolu zkopíruje na klonované servery.
- Obnovte konečnou zálohu transakčního protokolu na všech třech uzlech.
- Obnovte databázi na 3 uzlech klonování.
- Na všech čtyřech uzlech spusťte následující příkaz SELECT:
SELECT EMTEXT FROM [schema].TEMSG; - Zachyťte výsledky obrazovky příkazu SELECT pro každý ze čtyř db serverů (primární a tři klony). Nezapomeňte pečlivě zahrnout každý název hostitele – sloužit jako důkaz, že klonovaná databáze a primární jsou identické a obsahují stejná data ze stejného bodu v čase.
- Spusťte export_monitor.bat na každém serveru pro export Intel R3load.
- Spusťte kopírování souboru s výpisem paměti do Azure (AzCopy nebo Robocopy).
- Spusťte import_monitor.bat na virtuálních počítačích Azure R3load.
Následující diagram znázorňuje odeslání existujícího protokolu produkčního databázového serveru do databází klonování. Každý db server má jeden nebo více serverů Intel R3load.