Škálování výpočetních prostředků ve službě Azure Synapse Analytics
Jednou z klíčových funkcí správy, které máte k dispozici ve službě Azure Synapse Analytics, je schopnost škálovat výpočetní prostředky pro fondy SQL nebo Spark tak, aby splňovaly požadavky zpracování dat. V fondech SQL je jednotka škálování abstrakcí výpočetního výkonu, který se označuje jako jednotka datového skladu. Výpočetní funkce jsou oddělené od úložiště, což umožňuje jejich škálování nezávisle na datech v systému. To znamená, že výpočetní výkon můžete vertikálně navýšit a snížit tak, aby vyhovoval vašim potřebám.
Fond Synapse SQL můžete škálovat prostřednictvím webu Azure Portal, Azure Synapse Studia nebo programově pomocí TSQL nebo PowerShellu.
Na webu Azure Portal můžete kliknout na ikonu škálování .
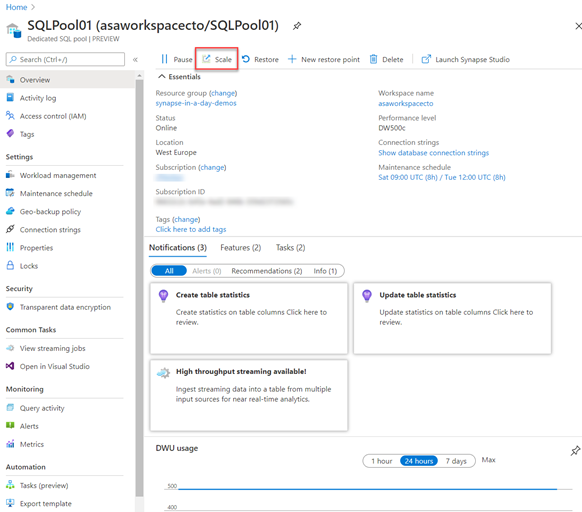
Potom můžete posuvník upravit tak, aby škálovat fond SQL
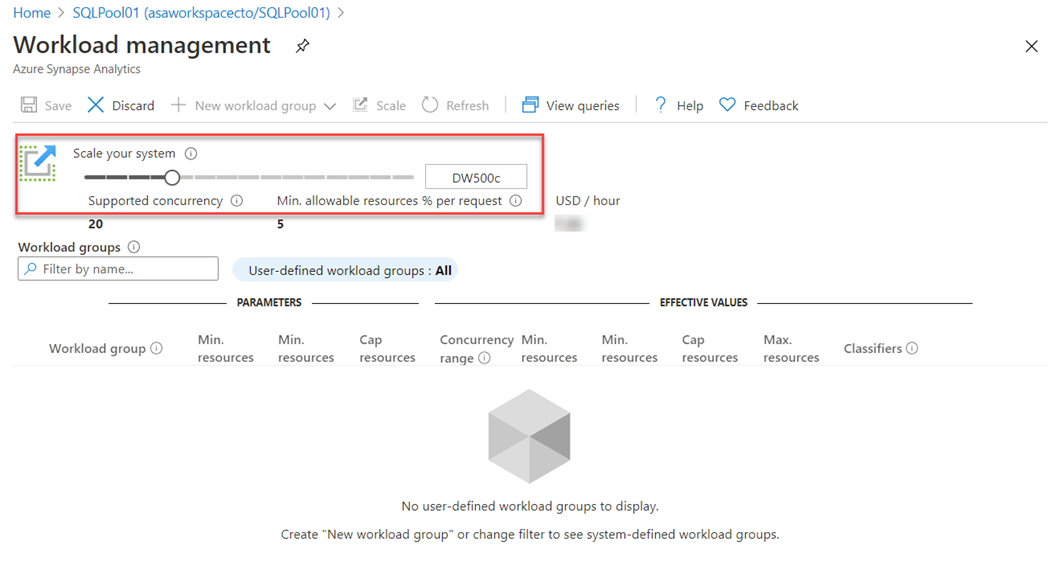
Další možností škálování je azure Synapse Studio, klikněte na ikonu škálování :
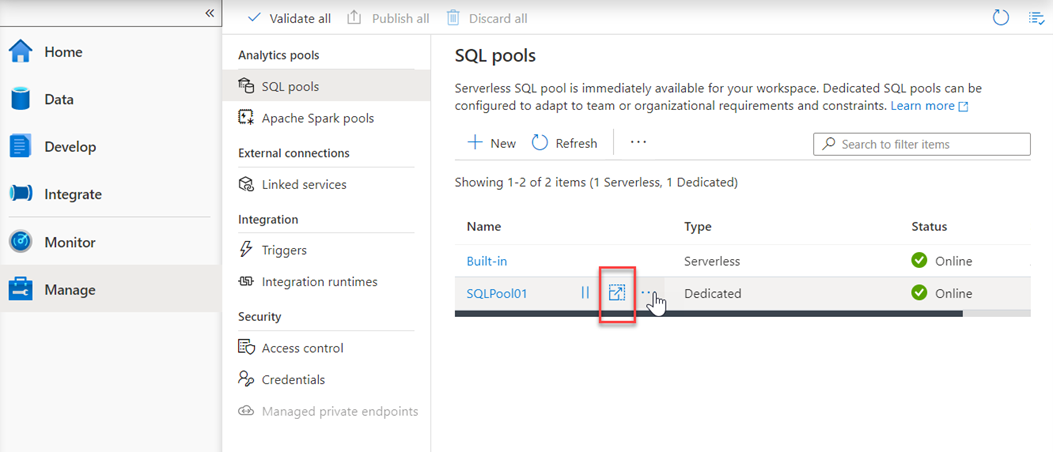
Pak posuvník přesuňte následujícím způsobem:
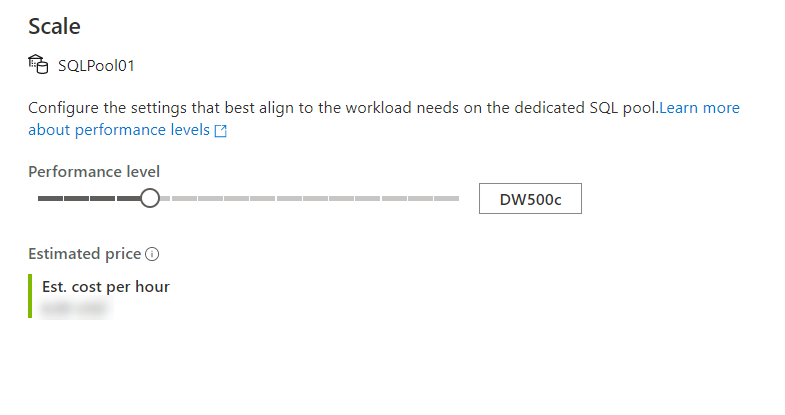
Úpravu můžete provést také pomocí jazyka Transact-SQL.
ALTER DATABASE mySampleDataWarehouse
MODIFY (SERVICE_OBJECTIVE = 'DW300c');
Nebo pomocí PowerShellu
Set-AzSqlDatabase -ResourceGroupName "resourcegroupname" -DatabaseName "mySampleDataWarehouse" -ServerName "sqlpoolservername" -RequestedServiceObjectiveName "DW300c"
Škálování fondů Apache Sparku ve službě Azure Synapse Analytics
Fondy Apache Sparku pro Azure Synapse Analytics používají funkci automatického škálování , která automaticky škáluje počet uzlů v instanci clusteru nahoru a dolů. Při vytváření nového fondu Sparku je možné nastavit minimální a maximální počet uzlů při výběru automatického škálování . Automatické škálování pak bude monitorovat požadavky na prostředky při zatížení a zvyšovat nebo snižovat počet uzlů. Pokud chcete funkci automatického škálování povolit, proveďte následující kroky jako součást normálního procesu vytváření fondu:
- Na kartě Základy zaškrtněte políčko Povolit automatické škálování.
- Zadejte požadované hodnoty pro následující vlastnosti:
- Minimální počet uzlů
- Maximální počet uzlů
Počáteční počet uzlů bude minimální. Tato hodnota definuje počáteční velikost instance při jejím vytvoření. Minimální počet uzlů nesmí být menší než tři.
Můžete to také upravit na webu Azure Portal. Můžete kliknout na ikonu nastavení automatického škálování .
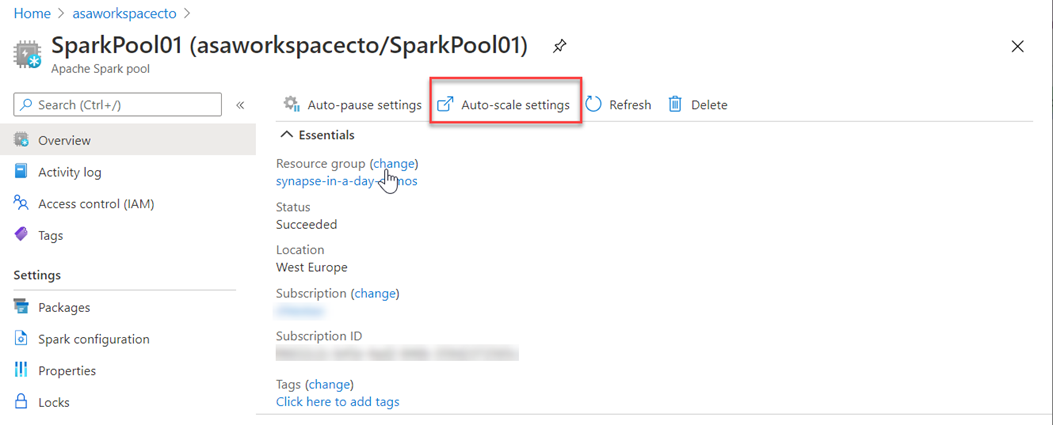
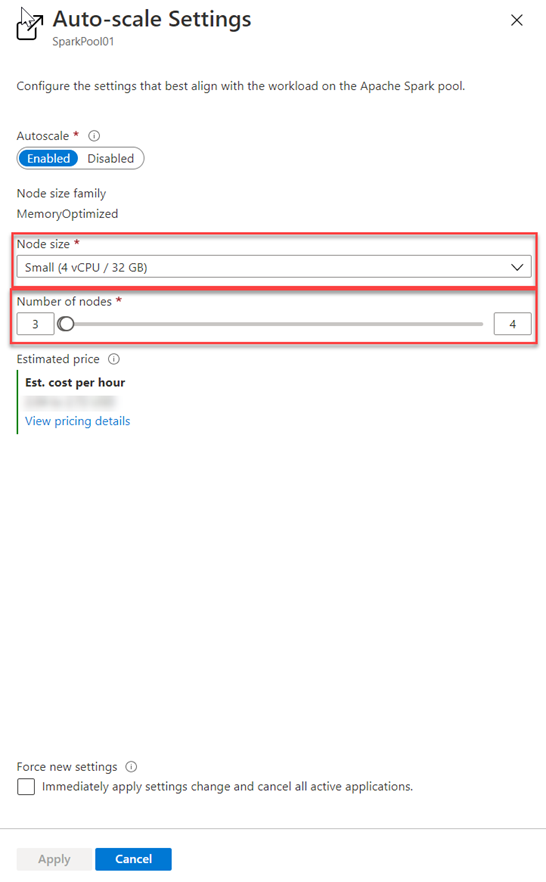
Zvolte velikost uzlu a počet uzlů.
a pro Azure Synapse Studio následujícím způsobem:
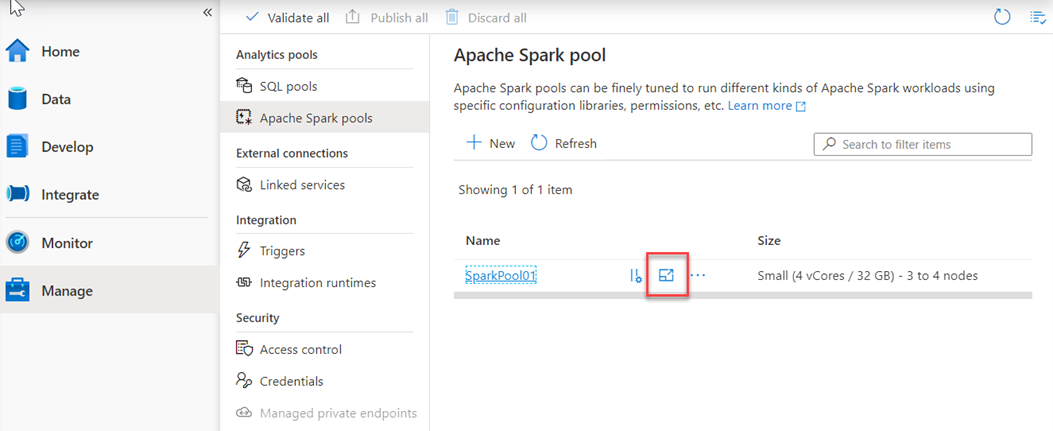
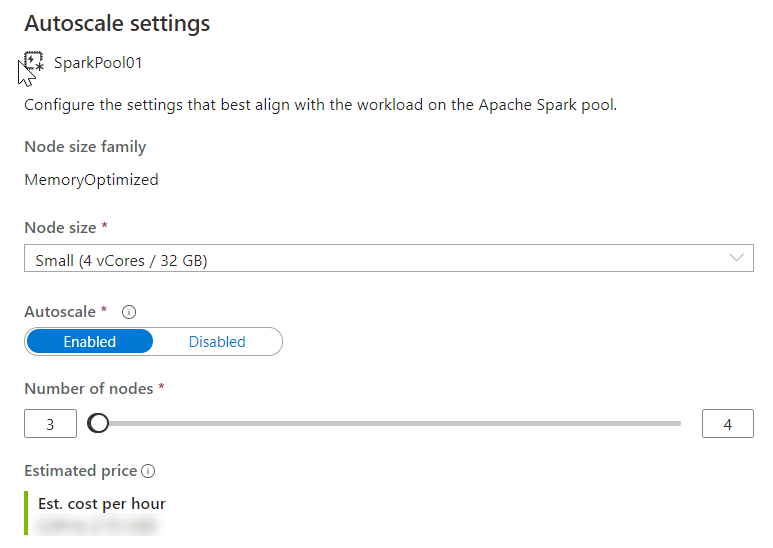
A zvolte velikost uzlu a počet uzlů.
Automatické škálování nepřetržitě monitoruje instanci Sparku a shromažďuje následující metriky:
| Metrický | Popis |
|---|---|
| Celkový počet nevyřízených procesorů | Celkový počet jader potřebných ke spuštění provádění všech čekajících uzlů. |
| Celková nevyřízená paměť | Celková paměť (v MB) potřebná ke spuštění provádění všech čekajících uzlů. |
| Celkový počet bezplatných procesorů | Součet všech nepoužívaných jader na aktivních uzlech. |
| Celková paměť volného místa | Součet nevyužité paměti (v MB) na aktivních uzlech. |
| Využitá paměť na uzel | Zatížení uzlu. Uzel, na kterém se používá 10 GB paměti, se považuje za méně zatížení než pracovní proces s 2 GB využité paměti. |
Následující podmínky pak automaticky škáluje paměť nebo procesor.
| Vertikální navýšení kapacity | Vertikální snížení kapacity |
|---|---|
| Celkový počet nevyřízených procesorů je větší než celkový bezplatný procesor za více než 1 minutu. | Celkový počet nevyřízených procesorů je menší než celkový bezplatný procesor za více než 2 minuty. |
| Celková nevyřízená paměť je větší než celková bezplatná paměť za více než 1 minutu. | Celková nevyřízená paměť je menší než celková bezplatná paměť po dobu delší než 2 minuty. |
Operace škálování může trvat 1 až 5 minut. Během instance, kde probíhá proces vertikálního snížení kapacity, umístí automatické škálování uzly do stavu vyřazení z provozu, aby se na tomto uzlu nespustí žádné nové exekutory.
Spuštěné úlohy budou i nadále spuštěné a dokončené. Čekající úlohy budou čekat na naplánování jako normální s menším počtem dostupných uzlů.