Optimalizace výkonu řešení Azure AI Search
Výkon řešení vyhledávání může být ovlivněn velikostí a složitostí indexů. Potřebujete také vědět, jak napsat efektivní dotazy, abyste je mohli prohledávat, a zvolit správnou úroveň služby.
Tady prozkoumáte všechny tyto dimenze a uvidíte kroky, které můžete provést, abyste zlepšili výkon vašeho vyhledávacího řešení.
Měření aktuálního výkonu vyhledávání
Pokud nevíte, jak dobře vaše vyhledávací služba funguje, nemůžete ji optimalizovat. Vytvořte srovnávací test standardního výkonu, abyste mohli ověřit vylepšení, která uděláte, ale můžete také zkontrolovat případné snížení výkonu v průběhu času.
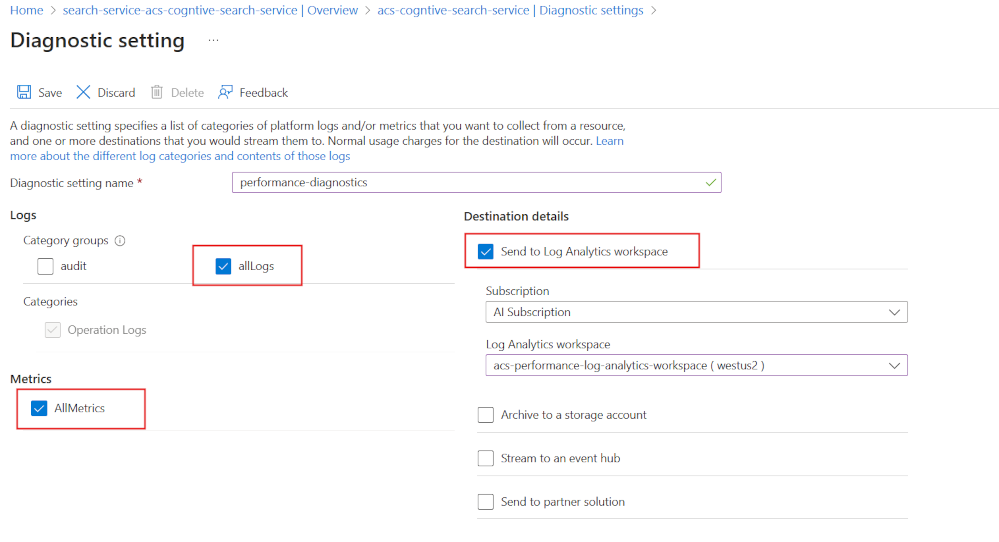
Začněte tím, že povolíte protokolování diagnostiky pomocí Log Analytics:
- Na webu Azure Portal vyberte Nastavení diagnostiky.
- Vyberte + Přidat nastavení diagnostiky.

- Zadejte název nastavení diagnostiky.
- Vyberte všechny protokoly a metriky.
- Vyberte Možnost Odeslat do pracovního prostoru služby Log Analytics.
- Zvolte nebo vytvořte pracovní prostor služby Log Analytics.
Tyto diagnostické informace je důležité zachytit na úrovni vyhledávací služby. Vzhledem k tomu, že koncoví uživatelé nebo aplikace můžou vidět problémy s výkonem, je několik míst.

Pokud můžete prokázat, že vaše vyhledávací služba funguje dobře, můžete ji eliminovat z možných faktorů, pokud máte problémy s výkonem.
Zkontrolujte, jestli je vaše vyhledávací služba omezena.
Hledání a indexy Azure AI Search je možné omezovat. Pokud uživatelé nebo aplikace mají omezené vyhledávání, zachytí se v Log Analytics s odpovědí HTTP 503. Pokud dochází k omezování indexů, zobrazí se jako odpovědi HTTP 207.
Tento dotaz, který můžete spustit v protokolech vyhledávací služby, ukazuje, jestli je vaše vyhledávací služba omezena.

Na webu Azure Portal v části Monitorování vyberte Protokoly. Na kartě Nový dotaz 1 byste použili tento dotaz:
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
Spuštěním příkazu byste zobrazili pruhový graf odpovědí HTTP vyhledávacích služeb. Ve výše uvedeném příkladu vidíte, že existuje několik 503 odpovědí.
Kontrola výkonu jednotlivých dotazů
Nejlepším způsobem, jak otestovat výkon jednotlivých dotazů, je klientský nástroj, jako je Postman. Můžete použít libovolný nástroj, který zobrazí hlavičky v odpovědi na dotaz. Azure AI Search vždy vrátí hodnotu uplynulé doby, po kterou služba dotaz dokončila.

Pokud chcete vědět, jak dlouho by odeslání a přijetí odpovědi od klienta trvalo, odečtěte uplynulý čas od celkové doby odezvy. Ve výše uvedeném příkladu by to bylo 125 ms - 21 ms dává vám 104 ms.
Optimalizace velikosti a schématu indexu
Způsob, jakým vaše vyhledávací dotazy fungují, jsou přímo propojené s velikostí a složitostí indexů. Menší a optimalizovanější indexy, rychlá služba Azure AI Search může reagovat na dotazy. Tady je několik tipů, které vám můžou pomoct, pokud jste zjistili, že máte problémy s výkonem jednotlivých dotazů.
Pokud nezadáte pozornost, indexy se můžou v průběhu času rozšiřovat. Měli byste zkontrolovat, že všechny dokumenty v indexu jsou stále relevantní a musí být prohledávatelné.
Pokud nemůžete odebrat žádné dokumenty, můžete snížit složitost schématu? Potřebujete stále stejná pole, aby bylo možné prohledávat? Stále potřebujete všechny sady dovedností, se kterými jste index začali?

Zvažte kontrolu všech atributů, které jste povolili u každého pole. Například přidání podpory filtrů, omezujících vlastností a řazení může násobit úložiště potřebné k podpoře indexu.
Poznámka:
Příliš mnoho atributů u pole omezuje jeho možnosti. Například v poli, které je fasetovatelné, filtrovatelné a prohledávatelné, můžete uložit pouze 16 kB. Zatímco prohledávatelné pole může obsahovat až 16 MB textu.
Pokud je index optimalizovaný, ale výkon stále není tam, kde je potřeba, můžete vertikálně navýšit kapacitu nebo vertikálně navýšit kapacitu vyhledávací služby.
Zlepšení výkonu dotazů
Pokud víte, jak vyhledávací služba funguje, můžete dotazy ladit tak, aby výrazně zlepšily výkon. Pomocí tohoto kontrolního seznamu můžete psát lepší dotazy:
- Pomocí parametru searchFields zadejte pouze pole, která potřebujete hledat. Vzhledem k tomu, že další pole vyžadují další zpracování.
- Vrátí nejmenší počet polí, která je potřeba vykreslit na stránce výsledků hledání. Vrácení dalších dat trvá déle.
- Snažte se vyhnout částečným hledanému výrazu, jako je hledání předpon nebo regulární výrazy. Tyto druhy hledání jsou výpočetně dražší.
- Nepoužívejte vysoké hodnoty přeskočení. Tím se vynutí, aby vyhledávací modul načetl a rozřadil větší objemy dat.
- Omezte použití omezujících a filtrovatelných polí na data s nízkou kardinalitou.
- Místo jednotlivých hodnot v kritériích filtru používejte vyhledávací funkce. Můžete například použít
search.in(userid, '123,143,563,121',',')místo$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121.
Pokud jste použili všechny výše uvedené a stále máte jednotlivé dotazy, které se neprovádějí, můžete škálovat index na více instancí. V závislosti na úrovni služby, kterou jste použili k vytvoření řešení vyhledávání, můžete přidat až 12 oddílů. Oddíly jsou fyzické úložiště, ve kterém se nachází váš index. Ve výchozím nastavení se všechny nové indexy vyhledávání vytvoří s jedním oddílem. Pokud přidáte další oddíly, index se v nich uloží. Pokud je například index 200 GB a máte čtyři oddíly, každý oddíl obsahuje 50 GB indexu.
Přidání dalších oddílů může pomoct s výkonem, protože vyhledávací modul může běžet paralelně v každém oddílu. Nejlepší vylepšení jsou vidět u dotazů, které vracejí velký počet dokumentů a dotazů, které používají omezující vlastnosti, které poskytují počty nad velkým počtem dokumentů. To je faktor, jak výpočetně nákladné je určení skóre levnosti dokumentů.
Použití nejlepší úrovně služby pro potřeby hledání
Viděli jste, že můžete škálovat úrovně služby přidáním dalších oddílů. Pokud potřebujete škálovat z důvodu zvýšení zatížení, můžete kapacitu škálovat pomocí replik. Můžete také vertikálně navýšit kapacitu vyhledávací služby pomocí vyšší úrovně.

Výše uvedené dva indexy vyhledávání mají velikost 200 GB. Úroveň S1 používá osm oddílů a úroveň S2 má pouze dvě. Obě repliky mají dvě repliky a obě by stály přibližně stejné. Volba nejlepší úrovně pro vaše řešení vyhledávání vyžaduje, abyste věděli přibližnou celkovou velikost úložiště, kterou budete potřebovat. Největší podporovaný index je aktuálně 12 oddílů na úrovni L2 a nabízí celkem 24 TB.
| Úroveň | Typ | Úložiště | Repliky | Oddíly |
|---|---|---|---|---|
| F | Free | 50 MB | 1 | 1 |
| T | Basic | 2 GB | 3 | 0 |
| S1 | Standard | 25 GB/oddíl | 12 | 12 |
| S2 | Standard | 100 GB/oddíl | 12 | 12 |
| S3 | Standard | 200 GB/oddíl | 12 | 12 |
| S3HD | Vysoká hustota | 200 GB/oddíl | 12 | 3 |
| L1 | Optimalizované pro úložiště | 1 TB/ oddíl | 12 | 12 |
| L2 | Optimalizované pro úložiště | 2 TB/ oddíl | 12 | 12 |
Která z výše uvedených dvou úrovní v předchozím příkladu je podle vás nejlepší? Zjistili jste, že horizontální navýšení kapacity přináší výhody výkonu kvůli paralelismu. Vyšší úrovně ale mají také premium storage, výkonnější výpočetní prostředky a další paměť. Když zvolíte druhou možnost, získáte výkonnější infrastrukturu a umožníte budoucí růst indexu. Na tom, která úroveň funguje nejlépe, bohužel závisí na velikosti a složitosti indexu a dotazech, které zapisujete, aby ho vyhledal. Takže to může být nejlepší.
Plánování budoucího růstu využití vašeho vyhledávacího řešení znamená, že byste měli zvážit jednotky hledání. Jednotka vyhledávání (SU) je produkt replik a oddílů. To znamená, že výše uvedená úroveň S1 používá 16 SU a úroveň S2 je pouze 4 SU. Náklady se podobají poplatkům za vyšší úrovně na SU.
Zamyslete se nad tím, že potřebujete škálovat řešení vyhledávání kvůli zvýšenému zatížení. Přidání další repliky do obou úrovní zvýší úroveň S1 na 24 SU , ale úroveň S2 se zvýší pouze na 6 SU.