Matrice záměny
Data si můžete představit jako průběžná, kategorická nebo řadová (kategorická, ale s pořadím). Matrice nejasnosti představují způsob vyhodnocení, jak dobře model kategorií funguje. Pro kontext, jak tyto funkce fungují, nejprve aktualizujeme naše znalosti o průběžných datech. Díky tomu můžeme vidět, jak konfuzní matice představují jednoduše rozšíření histogramů, které už víme.
Průběžné distribuce dat
Když chceme porozumět průběžným datům, prvním krokem je často zjistit, jak se distribuují. Představte si následující histogram:
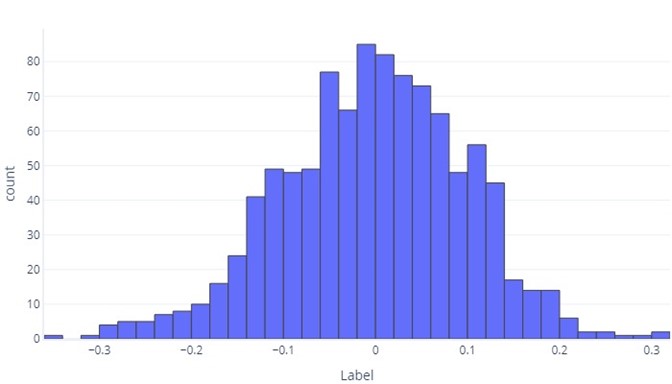
Vidíme, že popisek je v průměru přibližně nula a většina datových bodů spadá mezi -1 a 1. Zdá se jako symetrické; existuje přibližně sudý počet menších a větších než průměr. Pokud bychom chtěli, mohli bychom místo histogramu použít tabulku, ale mohlo by to být nepraktní.
Kategorické distribuce dat
V některých ohledech nejsou kategorická data tak odlišná od průběžných dat. Stále můžeme vytvořit histogramy, abychom posoudili, jak často se hodnoty zobrazují pro každý popisek. Například binární popisek (true/false) se může objevit s frekvencí, například takto:
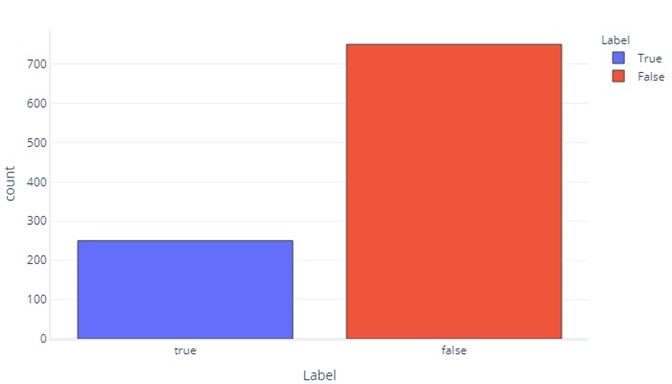
To nám říká, že jako popisek je 750 vzorků s "false" a jako popisek je 250 s "true".
Popisek pro tři kategorie je podobný:
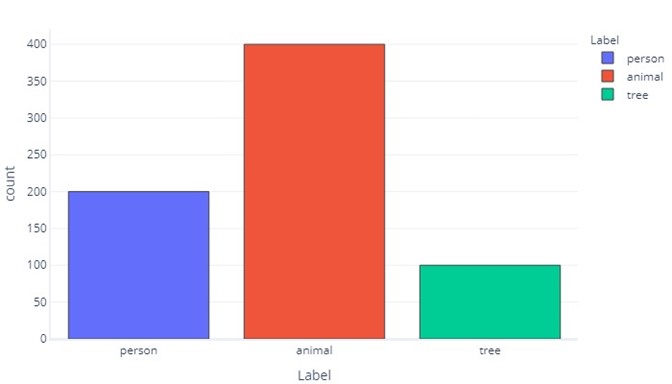
To nám říká, že existuje 200 vzorků, které jsou "osoba", 400, které jsou "zvíře" a 100, které jsou "strom".
Protože popisky kategorií jsou jednodušší, můžeme je často zobrazit jako jednoduché tabulky. Dva předchozí grafy by vypadaly takto:
| Popisek | False | True |
|---|---|---|
| Počet | 750 | 250 |
A:
| Popisek | Osoba | Zvíře | Strom |
|---|---|---|---|
| Počet | 200 | 400 | 100 |
Pohled na předpovědi
Můžeme se podívat na předpovědi, které model dělá stejně, jako se podíváme na popisky základní pravdy v našich datech. Můžeme například vidět, že v testovací sadě náš model předpověděl "false" 700krát a "true" 300krát.
| Predikce modelu | Počet |
|---|---|
| False | 700 |
| True | 300 |
To poskytuje přímé informace o předpovědích, které náš model vytváří, ale neřekne nám, které z nich jsou správné. I když můžeme použít nákladovou funkci, abychom pochopili, jak často jsou zadány správné odpovědi, nákladová funkce nám neřekne, jaké druhy chyb se provádějí. Model může například správně uhodnout všechny "true" hodnoty, ale také odhadnout "true", když by měl uhodnout "false".
Konfuzní matice
Klíčem k pochopení výkonu modelu je zkombinovat tabulku pro predikci modelu s tabulkou pro popisky dat pro pravdivou pravdu:
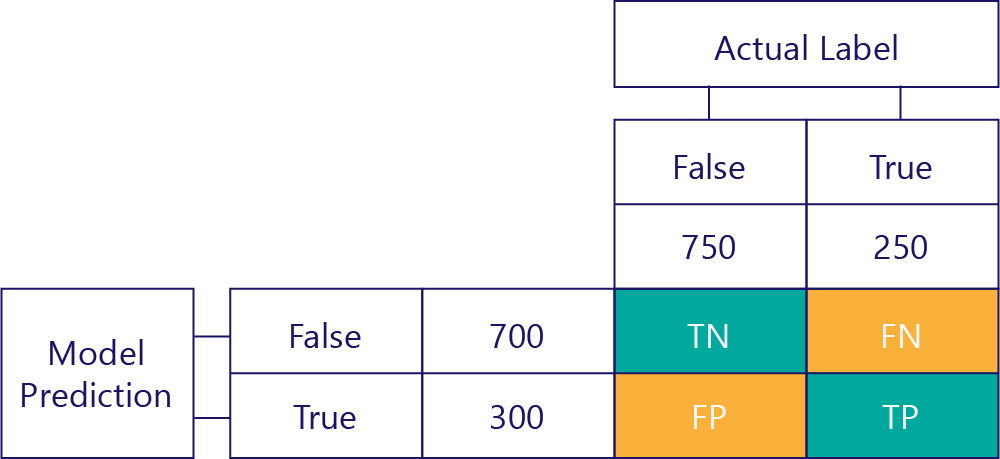
Čtverec, který jsme nevyplnili, se nazývá konfuzní matice.
Každá buňka v konfuzní matici nám říká jednu věc o výkonu modelu. Jedná se o true negatives (TN), false negatives (FN), false positives (FP) a true positives (TP).
Pojďme tyto zkratky vysvětlit jeden po druhém a nahradit je skutečnými hodnotami. Modré zelené čtverce znamenají, že model provedl správnou předpověď a oranžové čtverce znamenají, že model vytvořil nesprávnou předpověď.
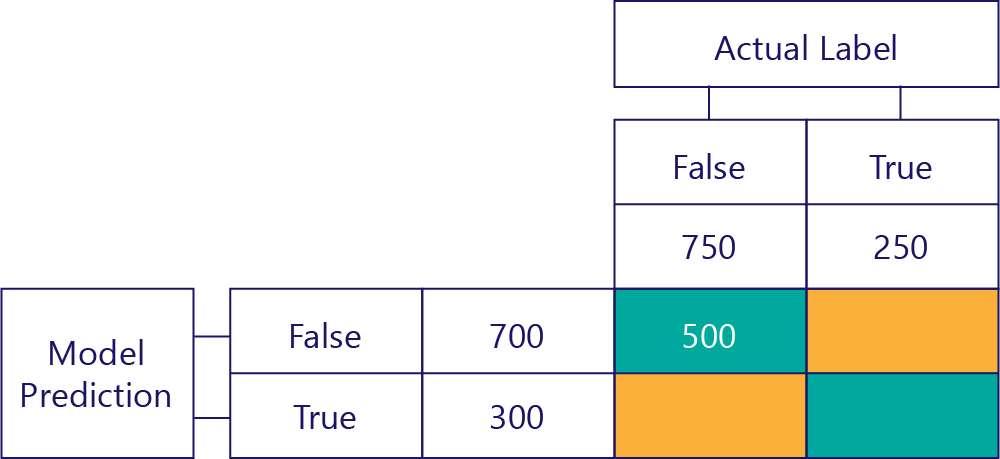
True Negatives (TN)
Levá horní hodnota vypíše, kolikrát model predikoval hodnotu false a skutečný popisek byl také false. Jinými slovy, tento seznam uvádí, kolikrát model správně predikoval hodnotu false. Řekněme například, že k tomu došlo 500krát:
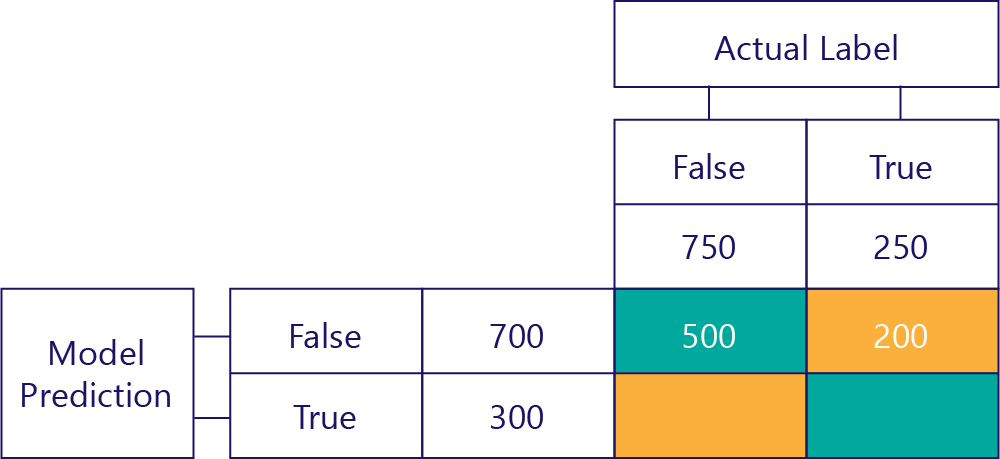
Falešně negativní (FN)
Hodnota vpravo nahoře nám říká, kolikrát model predikoval hodnotu false, ale skutečný popisek byl pravdivý. Teď víme, že je to 200. Jak? Vzhledem k tomu, že model předpověděl hodnotu false 700krát a 500 z těchto časů to udělal správně. Proto 200krát musí mít předpověděnou hodnotu false, pokud by neměla mít.
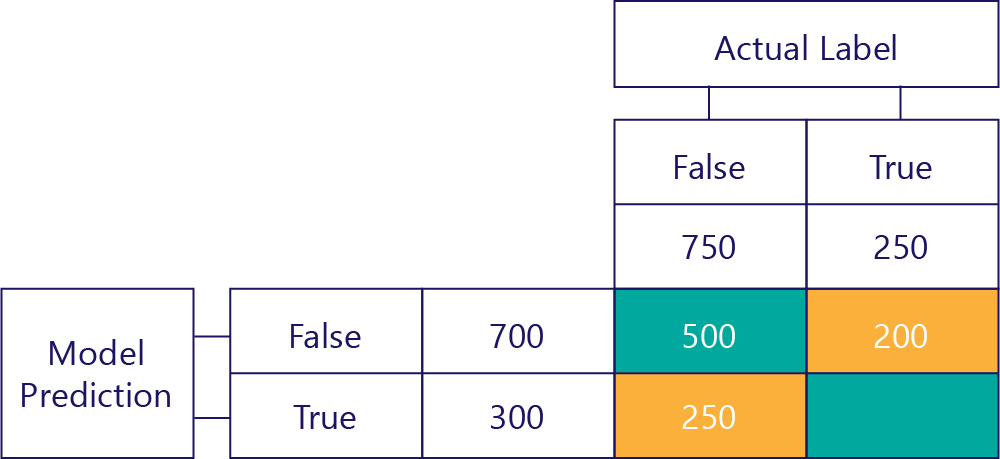
Falešně pozitivní (FP)
Levá dolní hodnota obsahuje falešně pozitivní výsledky. To nám říká, kolikrát model predikoval hodnotu true, ale skutečný popisek byl false. Víme teď, že je to 250, protože 750krát bylo, že správná odpověď byla nepravda. 500 z těchto časů se zobrazí v levé horní buňce (TN):
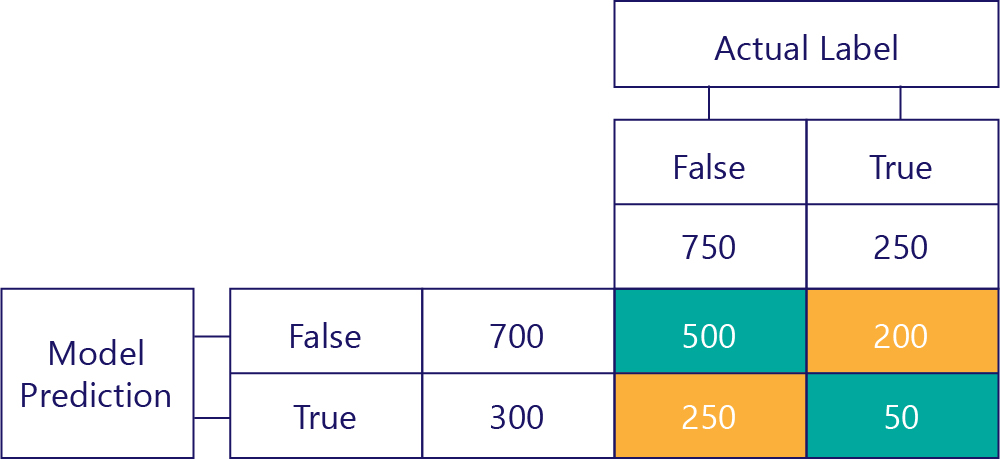
Pravdivě pozitivní (TP)
Nakonec máme pravdivě pozitivní výsledky. Toto je počet, kolikrát model správně predikuje hodnotu true. Víme, že to je 50 ze dvou důvodů. Za prvé model předpověděl 300krát hodnotu true, ale 250krát byl nesprávný (levá dolní buňka). Za druhé, pravda byla 250krát správná odpověď, ale 200krát model předpověděl false.
Konečná matice
My obvykle zjednodušujeme konfuzní matici mírně, například takto:
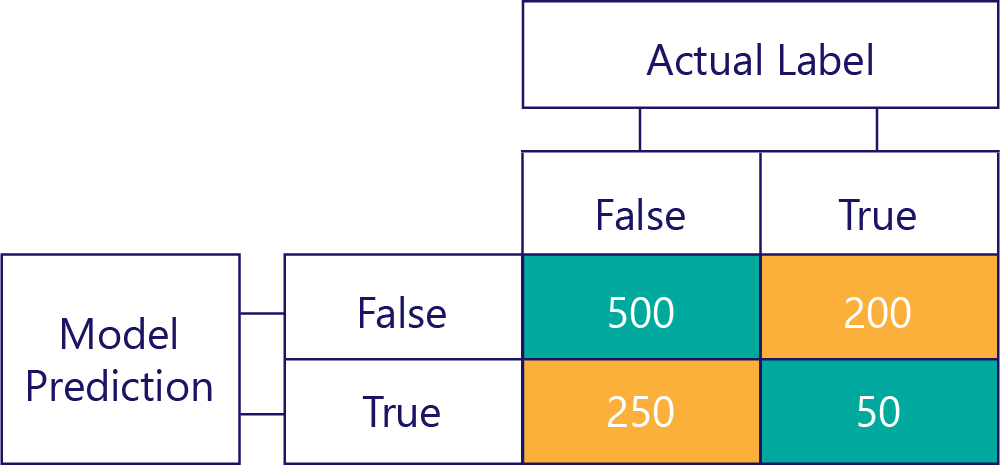
Vybarvení buněk jsme zde zvýraznili, když model provedl správné předpovědi. Z toho víme nejen, jak často model provedl určité typy predikcí, ale také jak často byly tyto předpovědi správné nebo nesprávné.
Matrice záměny lze také vytvořit, pokud existuje více popisků. Například pro naši osobu/ zvíře/ stromový příklad můžeme získat matici takto:
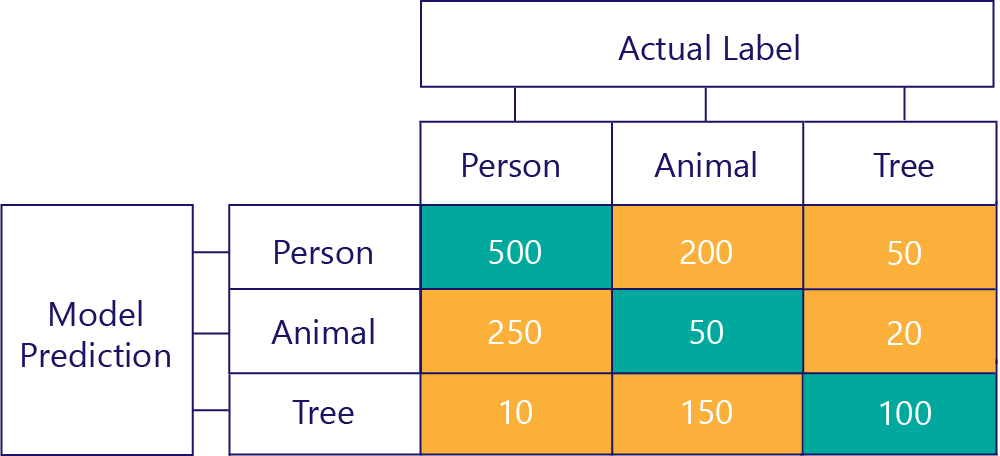
Pokud existují tři kategorie, metriky, jako jsou pravdivě pozitivní výsledky, už se nepoužijí, ale stále vidíme, jak často model provedl určité druhy chyb. Vidíme například, že model předpověděl, že "osoba" 200krát, když skutečný správný výsledek byl "zvíře".