Úvod
Jazyk SQL
SQL je zkratka pro jazyk SQL (Structured Query Language). SQL se používá ke komunikaci s relačními databázemi. Příkazy jazyka SQL se používají k provádění úkolů, jako je například aktualizace dat v databázi nebo načítání dat z databáze. Příkaz SQL SELECT se například používá k dotazování databáze a vrácení sady datových řádků. Mezi běžné systémy pro správu relačních databází používající SQL patří Microsoft SQL Server, MySQL, PostgreSQL, MariaDB a Oracle.
Existuje standard jazyka SQL definovaný americkým national standards institutem (ANSI). Každý dodavatel přidá vlastní varianty a rozšíření.
V tomto modulu se naučíte:
- Vysvětlení toho, co je SQL a jak se používá
- Identifikace databázových objektů ve schématech
- Identifikace typů příkazů SQL
- Použití příkazu SELECT k dotazování tabulek v databázi
- Práce s datovými typy
- Zpracování seznamů NUL
Transact-SQL
Základní příkazy SQL, jako je SELECT, INSERT, UPDATE a DELETE , jsou k dispozici bez ohledu na to, s jakým relačním databázovým systémem pracujete. I když jsou tyto příkazy SQL součástí standardu ANSI SQL, mnoho systémů pro správu databází má také vlastní rozšíření. Tato rozšíření poskytují funkce, které nejsou součástí standardu SQL, a zahrnují oblasti, jako je například správa zabezpečení a programovatelnost. Databázové systémy Microsoftu, jako je SQL Server, Azure SQL Database, Microsoft Fabric a další, používají dialekt SQL s názvem Transact-SQL nebo T-SQL. T-SQL obsahuje jazyková rozšíření pro psaní uložených procedur a funkcí, což jsou kód aplikace uložený v databázi a správa uživatelských účtů.
SQL je deklarativní jazyk
Programovací jazyky lze kategorizovat jako procedurální nebo deklarativní. Procedurální jazyky umožňují definovat posloupnost instrukcí, které počítač následuje k provedení úkolu. Deklarativní jazyky umožňují popsat požadovaný výstup a nechat podrobnosti o krocích potřebných k vytvoření výstupu do prováděcího modulu.
SQL podporuje určitou procedurální syntaxi, ale dotazování dat pomocí SQL se obvykle řídí deklarativní sémantikou. Sql použijete k popisu požadovaných výsledků a procesoru dotazů databázového stroje vyvíjí plán dotazu, který ho načte. Procesor dotazů používá statistiky o datech v databázi a indexech definovaných v tabulkách k vytvoření vhodného plánu dotazů.
Relační data
SQL se nejčastěji (i když ne vždy) používá k dotazování dat v relačních databázích. Relační databáze je taková, ve které jsou data uspořádaná do více tabulek (technicky označovaných jako relace), každá představuje konkrétní typ entity (například zákazník, produkt nebo prodejní objednávku). Atributy těchto entit (například jméno zákazníka, cena produktu nebo datum objednávky prodejní objednávky) jsou definované jako sloupce nebo atributy tabulky a každý řádek v tabulce představuje instanci typu entity (například konkrétního zákazníka, produktu nebo prodejní objednávky).
Tabulky v databázi se vzájemně souvisejí pomocí klíčových sloupců, které jednoznačně identifikují konkrétní entitu reprezentovanou. Primární klíč je definován pro každou tabulku a odkaz na tento klíč je definován jako cizí klíč v jakékoli související tabulce. Tento postup je srozumitelnější, když se podíváte na příklad:
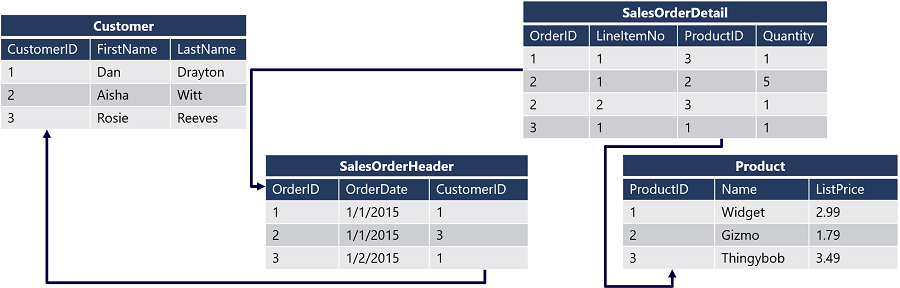
Diagram znázorňuje relační databázi, která obsahuje čtyři tabulky:
- Zákazník
- SalesOrderHeader
- SalesOrderDetail
- Product (Produkt)
Každý zákazník je identifikován jedinečným polem CustomerID – toto pole je primárním klíčem tabulky Zákazník . Tabulka SalesOrderHeader má primární klíč s názvem OrderID , který identifikuje každou objednávku, a obsahuje také cizí klíč CustomerID , který odkazuje na primární klíč v tabulce Zákazník , aby identifikoval zákazníka přidružený ke každé objednávce. Data o jednotlivých položkách v objednávce jsou uložena v tabulce SalesOrderDetail , která obsahuje složený primární klíč, který kombinuje IDobjednávky v tabulce SalesOrderHeader s hodnotou LineItemNo . Kombinace těchto hodnot jednoznačně identifikuje položku řádku. Pole OrderID se používá také jako cizí klíč k označení objednávky, do které položky řádku patří, pole IDproduktu se používá jako cizí klíč primárního klíče Idproduktu v tabulce Product k označení, ke kterému produktu bylo objednáno.
Zpracování založené na sadě
Teorie množin je jedním z matematických základů relačního modelu správy dat a je zásadní pro práci s relačními databázemi. I když můžete být schopni psát dotazy v T-SQL bez důkladného porozumění sadám, může být nakonec obtížné napsat některé složitější typy příkazů, které můžou být potřeba pro optimální výkon.
Aniž byste se ponořili do matematiky teorie množiny, můžete si představit sadu jako "kolekci určitých, odlišných objektů, které se považují za celek". Pokud jde o databáze SQL Serveru, můžete si sadu představit jako kolekci jedinečných objektů obsahujících nula nebo více členů stejného typu. Například tabulka Zákazník představuje sadu: konkrétně sadu všech zákazníků. Uvidíte, že výsledky příkazu SELECT tvoří také sadu.
Když se dozvíte více o příkazech dotazů T-SQL, je důležité vždy myslet na celou sadu místo jednotlivých členů. Tato sada myšlení vám bude lépe vybavit psaním kódu založeného na sadách, místo abyste si mysleli na jeden řádek najednou. Práce se sadami vyžaduje myšlení z hlediska operací, které se vyskytují "všechny najednou" místo jednoho po druhém.
Jednou z důležitých vlastností, které je třeba poznamenat o teorii množiny, je, že neexistuje žádná specifikace týkající se řazení členů sady. Tento nedostatek pořadí platí pro tabulky relačních databází. Neexistuje žádný koncept prvního řádku, druhého řádku nebo posledního řádku. K elementům je možné přistupovat (a načíst) v libovolném pořadí. Pokud potřebujete vrátit výsledky v určitém pořadí, musíte je explicitně zadat pomocí klauzule ORDER BY v dotazu SELECT.