Použití Azure Data Lake Storage Gen2 v úlohách analýzy dat
Azure Data Lake Store Gen2 je technologie umožňující použití více případů použití analýzy dat. Pojďme se podívat na několik běžných typů analytických úloh a zjistit, jak Azure Data Lake Storage Gen2 funguje s dalšími službami Azure, které je podporují.
Zpracování a analýza velkých objemů dat
Scénáře s velkými objemy dat obvykle odkazují na analytické úlohy, které zahrnují obrovské objemy dat v různých formátech, které je potřeba zpracovávat rychle – tzv. "three v". Azure Data Lake Storage Gen2 poskytuje škálovatelné a zabezpečené distribuované úložiště dat, ve kterém můžou služby pro velké objemy dat, jako jsou Azure Synapse Analytics, Azure Databricks a Azure HDInsight, používat architektury pro zpracování dat, jako jsou Apache Spark, Hive a Hadoop. Distribuovaná povaha úložiště a výpočetních prostředků zpracování umožňuje provádět úlohy paralelně, což vede k vysokému výkonu a škálovatelnosti i při zpracování velkého množství dat.
Datové sklady
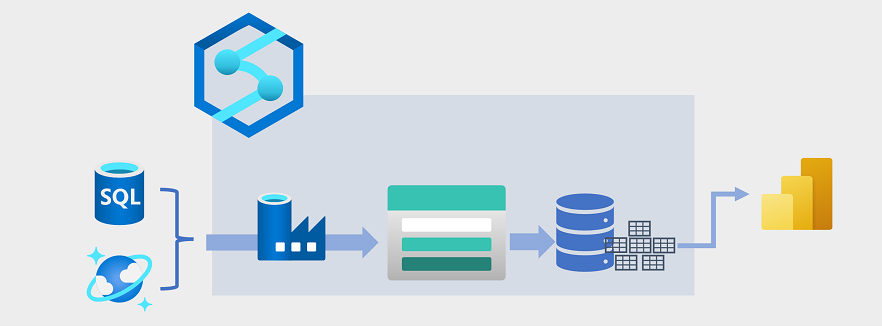
Datové sklady se v posledních letech vyvinuly, aby integrovaly velké objemy dat uložených jako soubory v datovém jezeře s relačními tabulkami v datovém skladu. V typickém příkladu řešení datových skladů se data extrahují z provozních úložišť dat, jako je databáze Azure SQL nebo Azure Cosmos DB, a transformují se na struktury, které jsou vhodnější pro analytické úlohy. Data se často fázují v datovém jezeře, aby bylo možné před načtením do relačního datového skladu usnadnit distribuované zpracování. V některých případech datový sklad používá externí tabulky k definování vrstvy relačních metadat nad soubory v datovém jezeře a vytvoření hybridní architektury Data Lakehouse nebo Lake Database. Datový sklad pak může podporovat analytické dotazy pro vytváření sestav a vizualizaci.
Tento typ architektury datových skladů lze implementovat několika způsoby. Diagram znázorňuje řešení, ve kterém Azure Synapse Analytics hostuje kanály , které provádějí procesy extrakce, transformace a načítání (ETL) pomocí technologie Azure Data Factory. Tyto procesy extrahují data z provozních zdrojů dat a načítají je do data lake hostovaného v kontejneru Azure Data Lake Storage Gen2. Data se pak zpracovávají a načítají do relačního datového skladu ve vyhrazeném fondu SQL azure Synapse Analytics, odkud můžou podporovat vizualizaci dat a vytváření sestav pomocí Microsoft Power BI.
Analýza dat v reálném čase
Firmy a další organizace stále častěji potřebují zaznamenávat a analyzovat časově neomezené datové proudy a analyzovat je v reálném čase (nebo co nejblíže k reálnému čase). Tyto datové proudy je možné generovat z připojených zařízení (často označovaných jako internet věcí nebo zařízení IoT ) nebo z dat generovaných uživateli na platformách sociálních médií nebo jiných aplikacích. Na rozdíl od tradičních úloh dávkového zpracování vyžaduje streamovaná data řešení, které dokáže zachytit a zpracovat neomezený datový proud událostí při jejich výskytu.
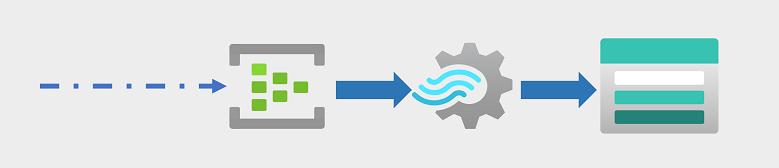
Události streamování se často zaznamenávají do fronty ke zpracování. K provedení této úlohy můžete použít několik technologií, včetně služby Azure Event Hubs, jak je znázorněno na obrázku. Odsud se data zpracovávají, často kvůli agregaci dat v časových oknech (například k počítání počtu zpráv sociálních médií s danou značkou každých pět minut nebo k výpočtu průměrného čtení senzoru připojeného k internetu za minutu). Azure Stream Analytics umožňuje vytvářet úlohy , které dotazují a agregují data událostí při jejich doručení a zapisují výsledky do výstupní jímky. Jednou z těchto jímek je Azure Data Lake Storage Gen2; z místa, kde lze zachycená data v reálném čase analyzovat a vizualizovat.
Datové vědy a strojové učení

Datové vědy zahrnují statistickou analýzu velkých objemů dat, často pomocí nástrojů, jako jsou Apache Spark a skriptovací jazyky, jako je Python. Azure Data Lake Storage Gen2 poskytuje vysoce škálovatelné cloudové úložiště dat pro objemy dat vyžadovaných v úlohách datových věd.
Strojové učení je podoblast datových věd, která se zabývá trénováním prediktivních modelů. Trénování modelu vyžaduje obrovské objemy dat a schopnost efektivně zpracovávat tato data. Azure Machine Learning je cloudová služba, ve které můžou datoví vědci spouštět kód Pythonu v poznámkových blocích pomocí dynamicky přidělených distribuovaných výpočetních prostředků. Výpočetní prostředky zpracovávají data v kontejnerech Azure Data Lake Storage Gen2 k trénování modelů, které je pak možné nasadit jako produkční webové služby pro podporu prediktivních analytických úloh.