DevOps pro strojové učení
DevOps a MLOps
DevOps je popsáno jako sjednocení lidí, procesů a produktů, aby koncovým uživatelům umožnil průběžné doručování hodnot– Donovan Brown v Co je DevOps?.
Abychom pochopili, jak se používá při práci s modely strojového učení, pojďme se podrobněji seznámit s některými základními principy DevOps.
DevOps je kombinace nástrojů a postupů, které vedou vývojáře při vytváření robustních a reprodukovatelných aplikací. Cílem použití principů DevOps je rychle poskytovat hodnotu koncovému uživateli.
Pokud chcete snadněji poskytovat hodnotu integrací modelů strojového učení do kanálů transformace dat nebo aplikací v reálném čase, můžete využít implementace principů DevOps. Informace o DevOps vám pomůžou organizovat a automatizovat vaši práci.
Vytváření, nasazování a monitorování robustních a reprodukovatelných modelů pro zajištění hodnoty koncovým uživatelům je cílem operací strojového učení (MLOps).
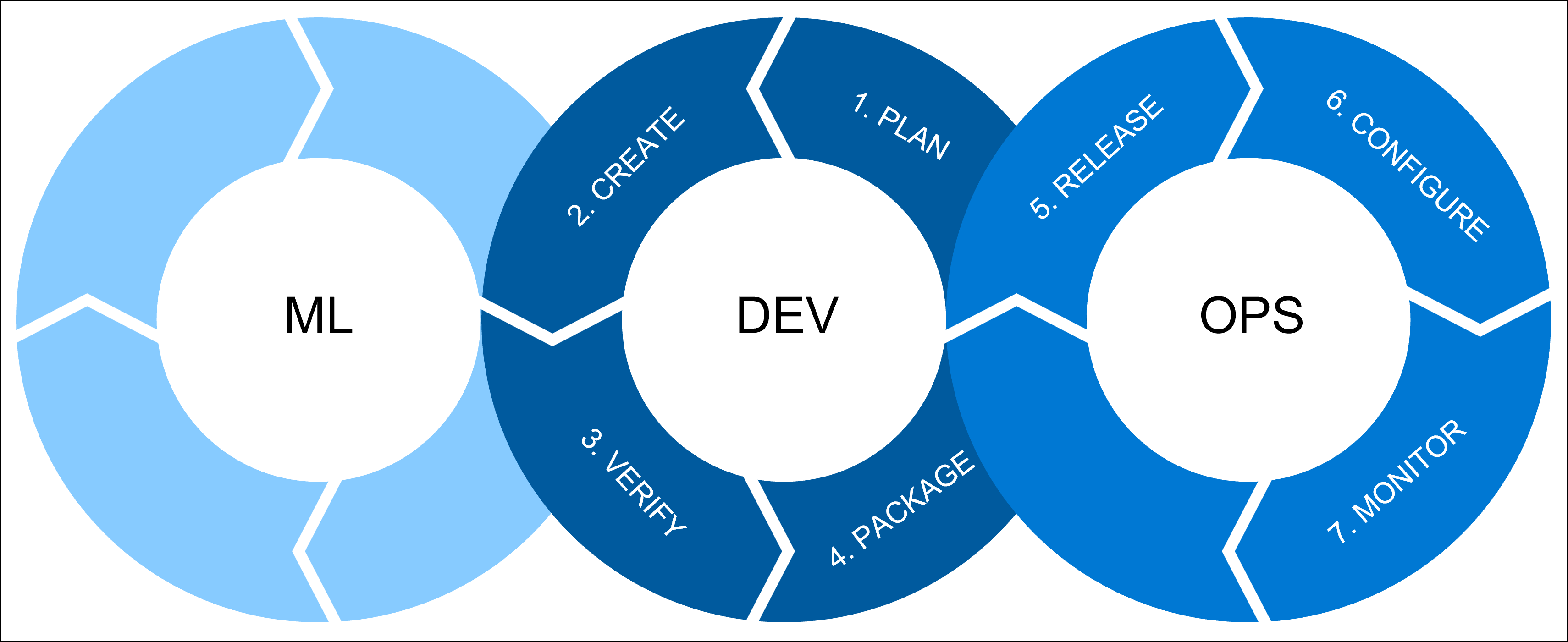
Existují tři procesy, které chceme kombinovat pokaždé, když mluvíme o operacích strojového učení (MLOps):
ml zahrnuje všechny úlohy strojového učení, za které zodpovídá datový vědec. Datový vědec provede:
- Průzkumná analýza dat (EDA)
- Inženýrství příznaků
- Trénování a ladění modelů
dev odkazuje na vývoj softwaru, který zahrnuje:
- plán: Definujte požadavky modelu a metriky výkonu.
- Vytvořte: Vytvořte trénovací a bodovací skripty modelu.
- Ověření: Zkontrolujte kvalitu kódu a modelu.
- balíček: Připravte řešení pro nasazení.
OPS odkazuje na operace a zahrnuje:
- Verze: Nasazení modelu do produkčního prostředí.
- Konfigurace– Standardizace konfigurací infrastruktury pomocí Infrastruktura jako kód (IaC).
- Monitorování: Sledujte metriky a zajistěte, aby model a infrastruktura fungovaly podle očekávání.
Pojďme si projít některé principy DevOps, které jsou nezbytné pro MLOps.
Principy DevOps
Jedním ze základních principů DevOps je automatizace. Automatizací úloh se snažíme rychleji nasazovat nové modely do produkčního prostředí. Prostřednictvím automatizace vytvoříte také reprodukovatelné modely, které jsou spolehlivé a konzistentní napříč prostředími.
Zejména pokud chcete model pravidelně v průběhu času vylepšit, automatizace umožňuje rychle provádět všechny nezbytné aktivity, aby se zajistilo, že model v produkčním prostředí je vždy nejvýkonnější.
Klíčovým konceptem automatizace je CI/CD, což je zkratka pro kontinuální integraci a průběžné doručování.
Kontinuální integrace
Průběžná integrace se zabývá vytvářením a ověřováním aktivit. Cílem je vytvořit kód a ověřit kvalitu kódu i modelu automatizovaným testováním.
S MLOps může kontinuální integrace zahrnovat:
- Refaktoring průzkumného kódu v poznámkových blocích Jupyter do skriptů v Pythonu nebo R
- Kontrola pomocí lintingu na zjištění případných programových nebo stylistických chyb ve skriptech Python nebo R. Zkontrolujte například, jestli řádek ve skriptu obsahuje méně než 80 znaků.
- Testování částí pro kontrolu výkonu obsahu skriptů Zkontrolujte například, jestli model generuje přesné předpovědi testovací datové sady.
Spropitné
Zjistěte, jak převádět experimenty strojového učení na produkční kód Pythonu
K provádění lintingu a jednotkového testování můžete použít automatizační nástroje, jako jsou Azure Pipelines v Azure DevOpsnebo GitHub Actions.
Průběžné doručování
Po ověření kvality kódu skriptů Pythonu nebo R použitých k trénování modelu budete chtít model přenést do produkčního prostředí. průběžného doručování zahrnuje kroky potřebné k nasazení modelu do produkčního prostředí, pokud možno automatizaci co nejvíce.
Pokud chcete nasadit model do produkčního prostředí, budete ho nejdřív chtít zabalit a nasadit ho do předprodukčního prostředí. Přípravou modelu v předprodukčním prostředí můžete zkontrolovat, jestli všechno funguje podle očekávání.
Po nasazení modelu do přípravné fáze je úspěšné a bez chyb můžete schválit nasazení modelu do produkčního prostředí .
Pokud chcete spolupracovat na skriptech Pythonu nebo R pro trénování modelu a veškerého potřebného kódu pro nasazení modelu do každého prostředí, použijete správu zdrojového kódu.
Správa zdrojového kódu
Řízení zdrojového kódu (nebo řízení verzí) se nejčastěji dosahuje prací s úložištěm na bázi Gitu. Úložiště odkazuje na umístění, kde mohou být uloženy všechny relevantní soubory softwarového projektu.
U projektů strojového učení pravděpodobně budete mít úložiště pro každý projekt, který máte. Úložiště bude obsahovat poznámkové bloky Jupyter, trénovací skripty, bodovací skripty a definice pracovních postupů mimo jiné.
Poznámka
Pokud možno, nejste ukládat trénovací data do úložiště. Místo toho se trénovací data ukládají v databázi nebo datovém jezeře a Azure Machine Learning načte data přímo ze zdroje dat pomocí úložiště dat .
Úložiště založená na Gitu jsou dostupná pomocí Azure Repos v Azure DevOps nebo úložiště GitHubu.
Hostováním veškerého relevantního kódu v úložišti můžete snadno spolupracovat na kódu a sledovat všechny změny, které člen týmu provede. Každý člen může pracovat na vlastní verzi kódu. Uvidíte všechny předchozí změny a změny si můžete prohlédnout, než se potvrdí do hlavního úložiště.
Pokud chcete rozhodnout, kdo pracuje na které části projektu, doporučujeme použít agilní plánování.
Agilní plánování
Vzhledem k tomu, že chcete model rychle nasadit do produkčního prostředí, je agilní plánování ideální pro projekty strojového učení.
agilní plánování znamená, že rozdělíte práci na sprinty. sprinty jsou krátká časová období, během kterých chcete dosáhnout části cílů projektu.
Cílem je naplánovat sprinty, které rychle zlepší jakýkoli kód. Ať už se jedná o kód používaný pro zkoumání dat a modelů, nebo nasazení modelu do produkčního prostředí.
Trénování modelu strojového učení může být nikdy nekončící proces. Například jako datový vědec možná budete muset zlepšit výkon modelu kvůli posunu dat. Nebo budete muset model upravit tak, aby lépe odpovídal novým obchodním požadavkům.
Aby se předešlo přílišnému trávení času na trénování modelu, může agilní plánování pomoci stanovit rozsah projektu a sladit všechny účastníky tím, že se dohodnou na krátkodobějších výsledcích.
K plánování práce můžete použít nástroj, jako je Azure Boards v Azure DevOps, nebo problémy s GitHubem.
Infrastruktura jako kód (IaC)
Použití principů DevOps na projekty strojového učení znamená, že chcete vytvářet robustní reprodukovatelná řešení. Jinými slovy, všechno, co děláte nebo vytváříte, byste měli být schopni opakovat a automatizovat.
K opakování a automatizaci infrastruktury potřebné k trénování a nasazení modelu bude váš tým používat Infrastructure as Code (IaC). Když vytrénujete a nasazujete modely v Azure, znamená to, že definujete všechny prostředky Azure potřebné v procesu v kódu a kód se uloží do úložiště.
Tip
Seznamte se s DevOps prozkoumáním modulů Microsoft Learn na cestě transformace DevOps