Jak azure HDInsight funguje
Tady se dozvíte, jak Azure HDInsight funguje. Dozvíte se o následujících komponentách a o tom, jak se hodí k zajištění řízení a správy dat:
- Apache Hadoop
- Úložiště HDInsight
- Zpracování HDInsight
Co je Apache Hadoop?
Apache Hadoop je cloudově distribuovaný systém pro zpracování dat v jádru SLUŽBY HDInsight. Má tři komponenty, které jsou popsané v následující tabulce:
| Komponenta Apache Hadoop | Popis |
|---|---|
| HDFS | Systém souborů HDFS (Apache Hadoop Distributed File System) poskytuje úložiště pro systém Hadoop. |
| PŘÍZE | Komponenta Apache Hadoop Ještě další komponenta YARN (Resource Negotiator) poskytuje zpracování systému. |
| MapReduce | MapReduce je programovací model, který umožňuje zpracovávat a analyzovat data. |
Jak interagují komponenty?
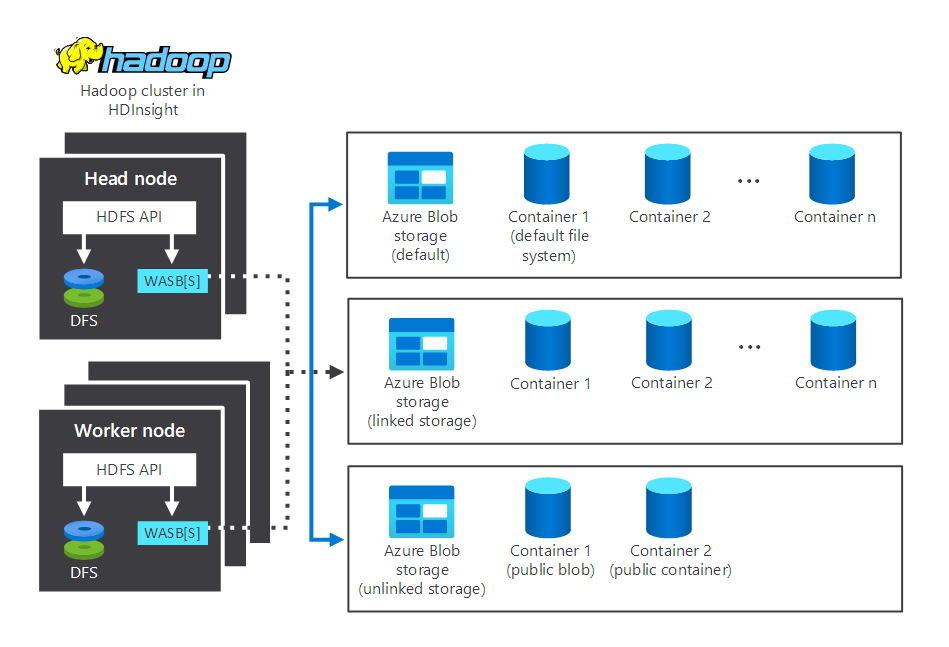
Následující diagram znázorňuje komponenty pro ukládání a zpracování, které komunikují v typickém clusteru HDInsight Hadoop. Znázorňuje následující komponenty:
- Hlavní uzel a pracovní uzly, které provádějí zpracování.
- Několik úložných center Windows Azure Storage Blob (WASB) v rámci uzlů. HDFS s těmito kontejnery komunikuje.
- Několik výchozích úložných kontejnerů, propojených a nepropojených. Ty jsou k dispozici pro dva uzly.
Pojďme se teď podívat, jak funguje úložiště a zpracování.
Jak funguje úložiště?
Komponenta úložiště clusteru se při zřizování clusteru HDInsight nevytvořila automaticky. Místo toho ji poskytuje systém kompatibilní s HDFS, jako je Azure Storage nebo Azure Data Lake.
Při oddělení součásti úložiště clusteru od součásti pro zpracování existují výhody. Můžete například bezpečně odstranit všechny clustery HDInsight používané pouze pro výpočty, aniž byste se museli starat o ztrátu dat. Když přidáváte cluster HDInsight, musíte definovat výchozí systém souborů.
Důležitý
Pro Azure Storage musíte jako výchozí systém souborů zadat kontejner objektů blob.
Poskytnutí výchozího systému souborů zajišťuje, že HDInsight dokáže při hledání souborů vyřešit relativní odkazy na soubory.
Rada
Pokud chcete zvýšit dostupné úložiště, můžete podle potřeby propojit a zrušit propojení dalších systémů souborů.

Jak funguje zpracování?
Při zpracování dat se výpočetní komponenta clusteru Hadoop v HDInsight rozdělí do dvou logických oblastí. Následující tabulka popisuje tyto dvě oblasti:
| Komponenta | Popis |
|---|---|
| Hlavní uzel | Hlavní uzel přijímá a spravuje požadavky klientů a předává je do pracovních uzlů. |
| Pracovní uzel | Pracovní uzly zpracovávají data. |
Poznámka
Hlavní uzel se někdy označuje jako řídicí uzel.
Většina clusterů obsahuje dva hlavní uzly, mezi které patří:
- Aktivní hlavní uzel, který spravuje připojení klientů.
- Pasivní hlavní uzel, který zajišťuje odolnost v případě, že aktivní uzel přejde do režimu offline.
Hlavní i pracovní uzly se můžou připojit přímo k místně připojenému HDFS nebo přistupovat k datům uloženým v Azure Blob nebo Azure Data Lake. Jaká data se spravují, závisí na dvou faktorech:
- Jak programovací model MapReduce definoval způsob práce s daty
- Jak hlavní uzel přiděluje práci
Co dělá YARN?
YARN provádí správu prostředků v rámci clusteru HDInsight. Při zpracování dat tato služba spravuje prostředky a plánování úloh.
YARN se nachází mezi HDFS a výpočetním systémem clusteru HDInsight. Funguje s hlavním uzlem a pomáhá distribuovat úlohu mezi pracovní uzly clusteru. To pomáhá zajistit, aby úlohy zpracování dat probíhaly paralelně.