Co je Azure HDInsight?
Pojďme se podívat na funkce a použití SLUŽBY HDInsight. Tento přehled vám pomůže vyhodnotit, jestli HDInsight řeší požadavky vaší organizace.
What is big data?
Termín velké objemy dat popisují obrovské objemy strukturovaných a nestrukturovaných dat, která organizace shromažďují. Tato data můžou být velmi užitečná pro organizace. Konkrétně platí, že pokud organizace dokáže analyzovat data pro přehledy, je lepší se rozhodnout. Výsledkem je, že tato rozhodnutí můžou organizaci pomoct stát se úspěšnější. Například analýza velkých objemů dat může komerční organizaci umožnit rozpoznávat zvyky zákazníků, což může vést ke zvýšení prodeje.
Definice Služby Azure HDInsight
Azure HDInsight je plně spravovaná cloudová opensourcová analytická služba pro podniky. HDInsight umožňuje řídit a spravovat velké objemy dat. HDInsight:
Je cloudová distribuce komponent Systému Hadoop.
Usnadňuje, rychlejší a nákladově efektivnější zpracování obrovských objemů dat.
Podporuje použití opensourcových architektur, například:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Poznámka:
Tyto architektury podporují širokou škálu scénářů, jako jsou ETL (extrakce, transformace a načítání), datové sklady, strojové učení a IoT.
HDInsight poskytuje organizacím, které pracují s velkými objemy dat, několik výhod. Je to:
Open source: Umožňuje vytvářet optimalizované clustery pro různé opensourcové architektury.
Spolehlivá: Poskytuje komplexní smlouvu SLA pro všechny produkční úlohy.
Škálovatelné: Umožňuje škálovat úlohy tak, aby reagovaly na změny poptávky.
Tip
Vytvořením clusterů na vyžádání můžete snížit náklady. Platíte jenom za to, co používáte.
Zabezpečení: Umožňuje chránit podnikové datové prostředky prostřednictvím integrace s:
- Azure Virtual Network
- Technologie šifrování v Azure
- Microsoft Entra ID
Kompatibilní: Splňuje oblíbené oborové standardy a standardy dodržování předpisů pro státní správu.
Monitorované: Integruje se s protokoly Azure Monitoru a poskytuje jedno rozhraní. Monitorujte všechny clustery pomocí jediného rozhraní.
Jak vám může HDInsight pomoct pracovat s velkými objemy dat
HDInsight můžete použít pro mnoho scénářů využívajících zpracování velkých objemů dat. Vaše data můžou být:
- Historická data: Tato data jsou již shromážděna a uložena.
- Data v reálném čase: Tato data se přímo streamují ze zdroje.
Následující kategorie shrnují scénáře zpracování těchto dat:
- Dávkové zpracování
- Datové sklady
- IoT
- Datové vědy
- Hybridní
Pojďme se podrobněji podívat na tyto kategorie.
Dávkové zpracování
Organizace používají úlohy dávkového zpracování k přípravě velkých objemů dat na další analýzu. Tento proces obvykle zahrnuje tři fáze:
- Čtení zdrojových datových souborů z heterogenních zdrojů dat
- Zpracování dat.
- Zápis dat do škálovatelného úložiště
Poznámka:
Tento proces se často označuje jako ETL.
Transformovaná data můžete použít pro datové sklady nebo datové vědy.
Tip
Důležitým požadavkem etL je horizontální navýšení kapacity výpočetních prostředků. To umožňuje zpracování velkých objemů dat.
Datové sklady
Datový sklad poskytuje organizaci, kde může ukládat velké objemy dat při čekání na jejich analýzu. Datové sklady umožňují:
- Uložte data.
- Připravte data na analýzu.
- Zadejte připravená data ve strukturovaném formátu. Data pak můžete dotazovat pomocí analytických nástrojů.
Následující diagram znázorňuje, jak Apache Hadoop ve službě HDInsight shromažďuje a ukládá data z několika zdrojů. Apache Spark a Apache Hive připraví a analyzuje data. Nakonec se data modelují pro použití s nástroji business intelligence (BI). Power BI se používá pro vizualizaci dat.
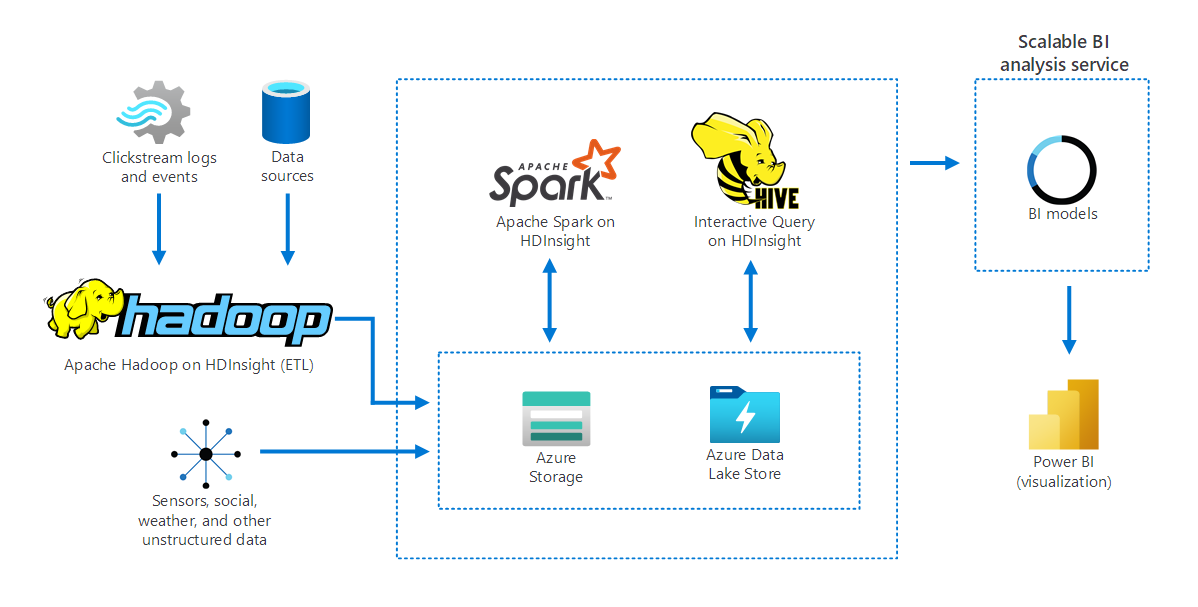
Součásti v tomto scénáři zahrnují:
- Apache Spark je architektura paralelního zpracování. Podporuje zpracování v paměti, což pomáhá zvýšit výkon analytických aplikací pro velké objemy dat.
- Apache Hive ve službě HDInsight je systém datového skladu pro Apache Hadoop. Hive umožňuje sumarizaci dat, dotazování a analýzu. Tyto komponenty můžete použít k provádění dotazů na petabajtové škálování strukturovaných a nestrukturovaných dat v libovolném formátu.
Tip
Dotazy Hive jsou napsané v HiveQL, dotazovací jazyk podobný JAZYKu SQL.
Internet věcí
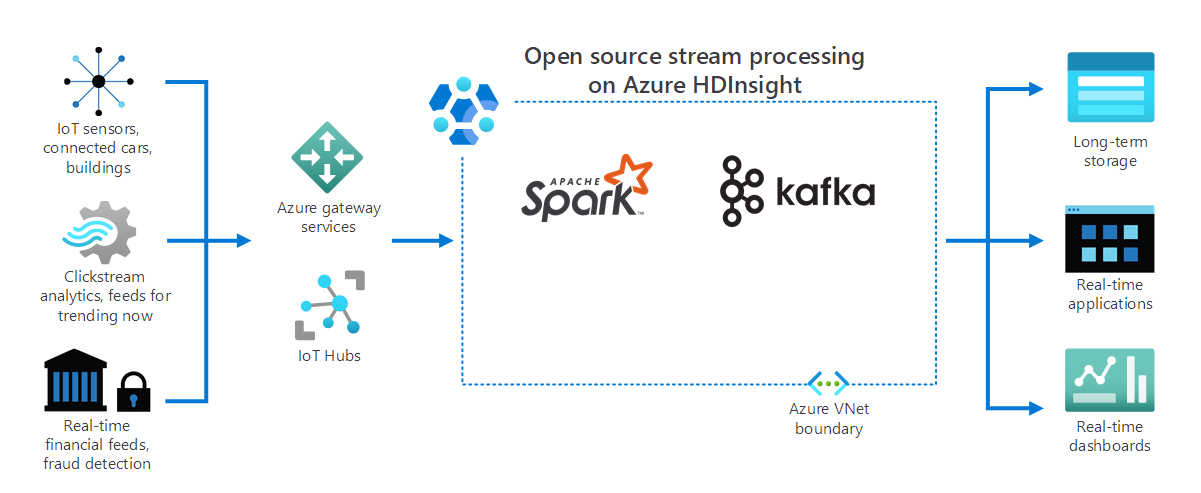
Jak znázorňuje následující diagram, HDInsight zpracovává streamovaná data přijatá v reálném čase z různých zařízení a senzorů. V tomto příkladu několik opensourcových architektur poskytuje zpracování datových proudů, včetně Apache Sparku a Apache Kafka.
Služby brány Azure a ioT Huby směrují data z různých zdrojů do těchto architektur. Architektury pak zpracovávají data a předá se do:
- Dlouhodobé ukládání.
- Aplikace v reálném čase.
- Řídicí panely v reálném čase
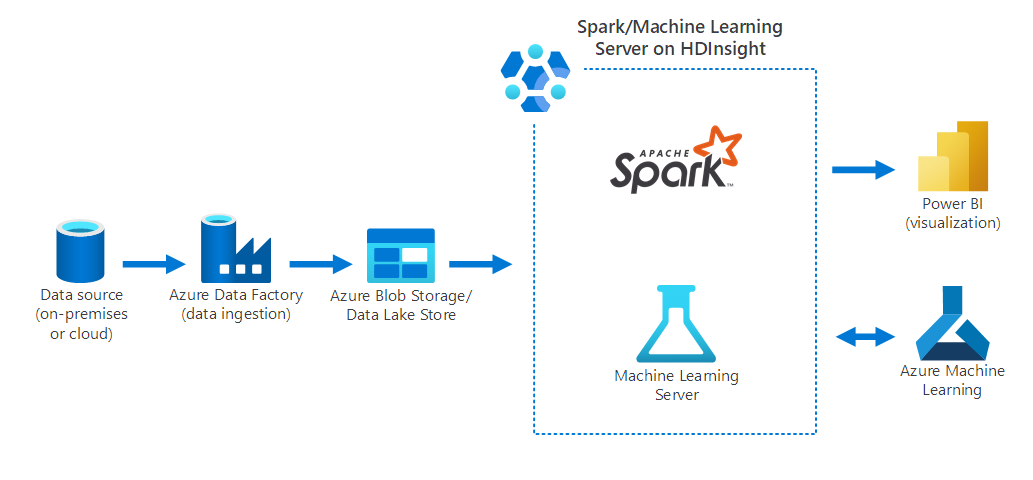
Datové vědy
HdInsight můžete použít k dokončení běžných úloh datových věd, jako jsou:
- Příjem dat.
- Příprava funkcí
- Modelování.
- Vyhodnocení modelu
Následující diagram znázorňuje scénář datových věd, ve kterém:
- Data se shromažďují z místního zdroje dat pomocí služby Azure Data Factory.
- Ingestovaná data se pak ukládají do úložiště Azure (Azure Blob Storage nebo Data Lake Store).
- Azure Spark ve službě HDInsight zpracovává a připravuje data pro Azure Machine Learning. Data se také vizualizují pomocí Power BI.
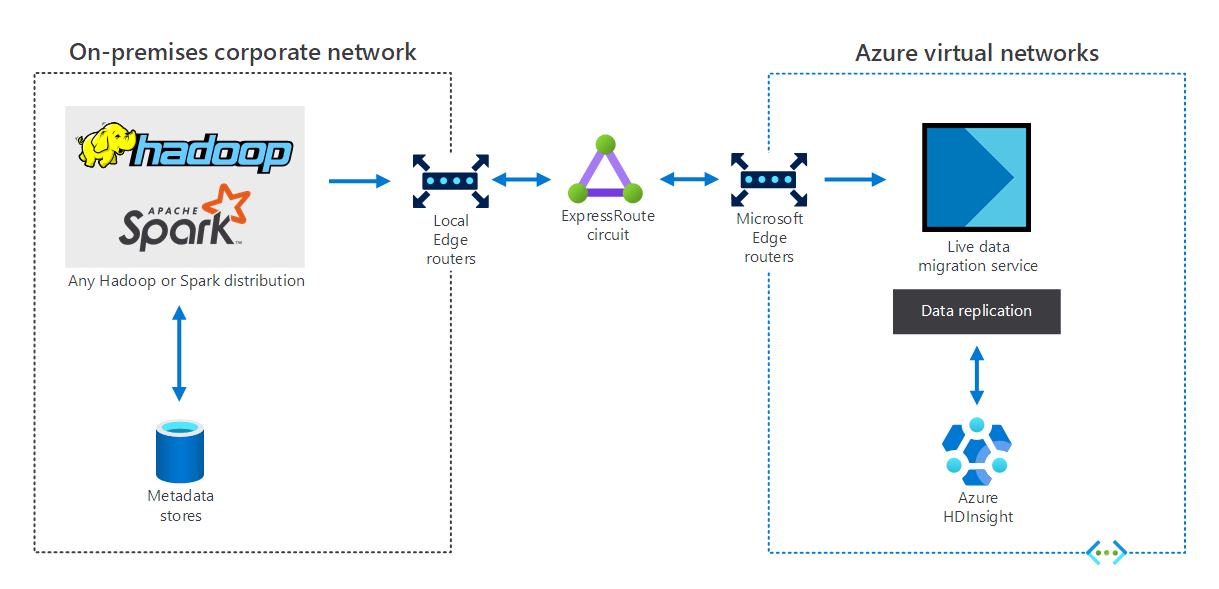
Hybridní
Organizace, které mají místní infrastrukturu pro velké objemy dat, můžou k rozšíření do Azure použít HDInsight. Díky tomu získáte výhody pokročilých analytických možností cloudu Azure. Následující diagram znázorňuje hybridní scénář, ve kterém:
- Místní infrastruktura pro velké objemy dat se skládá z úložišť metadat a distribuce Hadoopu nebo Sparku na místních virtuálních počítačích.
- Okruh Azure ExpressRoute propojuje místní podnikové síťové prostředí s virtuálními sítěmi Azure.
- Migrace živých dat pro Azure replikuje data přijatá z místního prostředí do SLUŽBY HDInsight.