Jak Azure Data Explorer funguje
V této lekci se podíváme na to, jak Azure Data Explorer funguje na pozadí tím, že probereme hlavní komponenty systému. Pak se dozvíte, jak pracovat se službou prozkoumáním běžného pracovního postupu:
- Příjem dat
- Kusto Query Language
- Vizualizace dat
Tyto znalosti vám pomůžou rozhodnout, jestli je Azure Data Explorer vhodný pro vaše potřeby dat.
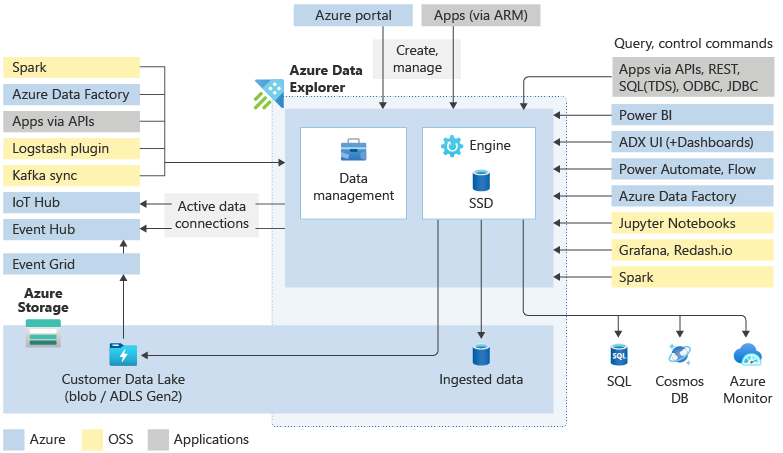
Hlavní komponenty
Cluster Azure Data Exploreru funguje při ingestování, zpracování a dotazování dat. Clustery jsou automaticky škálovatelné podle vašich potřeb. Azure Data Explorer také ukládá data do služby Azure Storage a ukládá některá z těchto dat do mezipaměti do výpočetních uzlů clusteru, aby se dosáhlo optimálního výkonu dotazů.
Co je v clusteru Azure Data Exploreru?
Každý cluster Azure Data Exploreru může obsahovat až 10 000 databází a každou databázi až 10 000 tabulek. Data v každé tabulce jsou uložená v horizontálních oddílech dat označovaných také jako rozsahy. Všechna data se automaticky indexují a rozdělují na základě času příjmu dat. Na rozdíl od relační databáze neexistují žádná omezení primárního cizího klíče ani žádná jiná omezení, například jedinečnost. Tento návrh znamená, že můžete ukládat velké objemy různých dat. A vzhledem k tomu, jak je uložená, získáte rychlý přístup k dotazování.
Logická struktura databáze je podobná mnoha dalším relačním databázím. Databáze Azure Data Exploreru může obsahovat:
- Tabulky: Skládá se ze sady sloupců. Každý sloupec má jeden z devíti různých datových typů.
- Externí tabulky: Tabulky, jejichž podkladové úložiště je v jiných umístěních, jako je Azure Data Lake.
Seznámení s obecným pracovním postupem
Obecně řečeno, když pracujete s Azure Data Explorerem, projdete následující pracovní postup: Nejprve ingestujete data, abyste je získali v systému. Pak data analyzujete. Dále vizualizujete výsledky analýzy. Kdykoli můžete také zapojit funkce správy dat. Tato práce s Azure Data Explorerem se provádí prostřednictvím interakce s clusterem. K těmto prostředkům můžete přistupovat buď ve webovém uživatelském rozhraní, nebo pomocí sad SDK.
Návody získat data do Azure Data Exploreru?
Příjem dat je proces používaný k načtení záznamů dat z jednoho nebo více zdrojů do tabulky v Azure Data Exploreru. Další manipulace s daty zahrnuje odpovídající schéma, uspořádání, indexování, kódování a komprimaci dat. Správce dat pak potvrdí ingestování dat do modulu, kde je k dispozici pro dotaz.
Kromě nativního průvodce webovým uživatelským rozhraním jsou k dispozici různé nástroje pro příjem dat. Včetně spravovaných kanálů, Event Gridu, IoT Hubu a Azure Data Factory. Můžete použít konektory a moduly plug-in, jako jsou modul plug-in Logstash, konektor Kafka, Power Automate a konektor Apache Spark. Programový příjem dat můžete použít také pomocí sad SDK nebo LightIngest.
Data se můžou ingestovat ve dvou režimech: Dávkování nebo streamování. Příjem dávek je optimalizovaný pro vysokou propustnost příjmu dat a rychlé výsledky dotazů. Příjem dat streamování umožňuje latenci téměř v reálném čase u malých sad dat na tabulku.
Návody analyzovat moje data?
Azure Data Explorer k analýze dat používá proprietární dotazovací jazyk Kusto (KQL). Běžně se používá v Microsoftu (Azure Monitor – Log Analytics a Application Insights, Microsoft Sentinel a XDR v programu Microsoft Defender). KQL je optimalizovaná pro rychlé, různorodé zkoumání velkých objemů dat. Dotazy odkazují na tabulky, zobrazení, funkce a jakékoli další tabulkové výrazy. Zahrnutí tabulek do různých databází nebo dokonce clusterů Dotazy je možné spouštět pomocí webového uživatelského rozhraní, různých nástrojů pro dotazy nebo s některou ze sad SDK Azure Data Exploreru.
Jak dotazovací jazyk Kusto funguje?
dotazovací jazyk Kusto je výrazný, intuitivní a vysoce produktivní dotazovací jazyk. Nabízí hladký přechod z jednoduchých oneřádkovačů na složité skripty pro zpracování dat a podporuje dotazování strukturovaných, částečně strukturovaných a nestrukturovaných dat (vyhledávání textu). Jazyk obsahuje celou řadu operátorů a funkcí dotazovacího jazyka (agregace, filtrování, funkce časových řad, geoprostorové funkce, spojení, sjednocení a další). KQL podporuje dotazy napříč clustery a mezi databázemi a je z hlediska analýzy (json, XML atd.) bohaté. Jazyk navíc nativně podporuje pokročilou analýzu.
Jak můžu zobrazit výsledky dotazu?
Webové uživatelské rozhraní Azure Data Exploreru bylo navržené s ohledem na velké objemy dat, které umožňuje spouštět dotazy a sestavovat řídicí panely. Podporuje zobrazení až 500 K záznamů a tisíců sloupců. Je vysoce škálovatelná a bohatá s funkcemi, které vám pomůžou rychle nakreslit přehledy z vašich dat. Na řídicích panelech Azure Data Exploreru můžete také použít různé vizuální zobrazení dat. Výsledky můžete zobrazit také pomocí nativních konektorů k některým špičkovým vizualizačním službám, které jsou dnes k dispozici, jako jsou Power BI a Grafana. Azure Data Explorer má také podporu konektoru ODBC a JDBC pro nástroje, jako jsou Tableau a Qlik.
Návody spravovat moje data?
Správci chtějí na svých clusterech Azure Data Exploreru provádět různé úlohy údržby a zásad a řídicí příkazy jim umožňují to udělat. Pomocí řídicích příkazů můžou vytvářet nové clustery nebo databáze, navazovat datová připojení, provádět automatické škálování a upravovat konfigurace clusteru. Můžou také řídit a upravovat entity, objekty metadat, spravovat oprávnění a zásady zabezpečení. Kromě toho mohou upravovat materializovaná zobrazení (průběžně aktualizovaná filtrovaná zobrazení jiných tabulek), funkce (uložené funkce a uživatelem definované funkce) a zásady aktualizace (funkce aktivované po příjmu dat).
Řídicí příkazy se spouští přímo v modulu pomocí webu WebUI, webu Azure Portal, různých nástrojů pro dotazy nebo jedné ze sad SDK Azure Data Exploreru.