Sledování incidentů
Incidenty mají životní cyklus. Abyste mohli reagovat co nejúčelněji, musíte být schopni sledovat vývoj samotného incidentu a vývoj reakce na něj od samého začátku tohoto životního cyklu.
Posouzení toho, co víte
Dobrým způsobem, jak vyhodnotit postup sledování incidentů pomocí konkrétního incidentu, je položit si řadu otázek:
- Kdy jste o problému poprvé věděli? Pokud vaším cílem je zkrátit dobu potřebnou k zotavení z incidentů, musíte začít zaznamenávat informace od okamžiku, kdy se o těchto problémech dozvíte.
- Jak jste se dozvěděli o problému? Upozorňoval vás váš sledovací systém na incident? Slyšeli jste o tom poprvé od zákazníků, kteří si stěžují, ať už přímo, nebo na sociálních sítích?
- Pokud se o problému teprve dozvídáte, jste první, kdo se to dozvídá? Pokud ano, kdo je potřeba upozornit? Pokud ne, kdo jiný o problému ví?
- Pokud o tom ostatní vědí, co (pokud něco) s tím dělají? Předpokládá každý, že to někdo jiný řeší, nebo už někdo začal podnikat kroky k nápravě?
- Jak je to špatné? Možná nemáme žádnou představu o závažnosti nebo dopadu a neexistuje místo, kde bychom zjistili, jak je problém opravdu špatný a kdo je ovlivněný.
Tyto otázky můžou být obtížné odpovědět, pokud se nic nesleduje.
Standardizace, kde se budou sledovat informace o incidentu
Existuje mnoho možných míst, kde můžete zachovat a sdílet seznam incidentů (aktivní nebo jinak) a všechny aktuální informace o těchto incidentech. Může to být jednoduché jako sdílená oblast souborů s wordovými dokumenty a stejně složité jako vysoce specializovaný software a služby pro sledování incidentů. Mezi těmito dvěma extrémy jsou systémy pro správu lístků a sledování práce, které můžete využít pro tuto úlohu. Který systém, který zvolíte, je ve skutečnosti méně důležitý než způsob jeho použití. Bez ohledu na to, jaký systém používáte, musí všichni, kdo mají vůbec jakékoli spojení s incidenty (technici, zákaznická podpora, správa, vztahy s veřejností, právní a tak dále), vědět, kam se má systém najít, jak vytvořit incident a jak získat přístup k datům, pokud je to vhodné. Jedním z jistých způsobů, jak selhat se sledováním incidentů, je, že lidé, které má systém podporovat, nevědí, jak se do něj dostat ("jaká že vlastně byla URL našeho systému?") ve chvíli, kdy ho potřebují.
V tomto modulu použijeme funkci pracovních položek Azure DevOps pro náš ukázkový sledovací systém.
Vytvoření mostu konverzace
Chcete-li odpovědět na některé otázky v předcházející části Posoudit, co víte a zahájit proces reakce na incident, musíte mít způsob, jak s ostatními komunikovat o incidentu. V ideálním případě by to měl být nějaký elektronický prostředek týmové spolupráce pro komunikaci, ačkoli i telefonní konference fungují dobře. Konferenční hovory a telefonní mosty jsou méně preferované, protože je obtížnější zpětně zkontrolovat komunikaci incidentu (proto je zmíněna role "Scribe").
Ať už zvolíte jakékoli médium, měli byste se ujistit, že vytvoříte speciální kanál, který je přísně omezený na diskusi o tomto incidentu a na nic jiného. V tomto kanálu je důležité vynechat irelevantní debatu, protože potřebujete mít možnost vzít data a analyzovat je později ve vyhodnocení incidentu.
V tomto modulu použijeme Microsoft Teams jako metodu komunikace incidentů.
Automatizace spuštění sledování incidentů
Pojďme se tedy podívat na ty části, které jsme zatím dali dohromady. Máme:
- Seznam pohotovostního personálu (a jejich určená rotace).
- Roli můžeme přiřadit lidem pracujícím na incidentu.
- Konkrétní místo, kde budeme incident ohlásit a sledovat.
- Jedinečný kanál pro lidi pracující na daném incidentu, aby o něm mohli komunikovat.
Můžete a měli byste automatizovat vytváření a správu všech těchto věcí v co největší možné míře. Když dojde k naléhavému problému, nechcete si vzpomenout na všechny kroky potřebné k vyvolání incidentu, uvedení správných lidí a jeho sledování. Vše, co opravdu chcete udělat, je být schopen stisknout tlačítko "start", aby práce mohla okamžitě začít řešit problém.
Použití Logic Apps pro automatizaci bez kódu
Jedním ze způsobů, jak automatizovat počáteční odpověď, je použití Logic Apps, které může zjednodušit úlohu plánování, automatizace a orchestrace úloh, obchodních procesů a pracovních postupů.
Logic Apps je cloudová služba Azure pro vytváření řešení integrace. K vytváření automatizovaných pracovních postupů používá konektory . Triggery spustí Logic App, když nastane konkrétní událost, nebo když data splňují zadaná kritéria. Akce jsou operace prováděné v pracovním postupu Logic App.
V našem příkladu použijeme pro sledování incidentů následující konektory aplikace logiky:
- Azure Boards (součást Azure DevOps), kterou můžete použít k vytváření a sledování problémů a incidentů.
- Azure Storage, kde můžete ukládat a načítat informace o tom, kdo je v pohotovosti, abyste mohli přiřadit správné lidi, kteří na incident zareagují. V našem příkladu budeme používat Azure Table Storage, protože nabízí velmi jednoduché úložiště klíč-hodnota, které usnadňuje ukládání seznamu techniků a jejich stavu při volání.
- Microsoft Teams, který můžete použít k vytvoření nového, jedinečného kanálu incidentu ke sledování konverzací technických týmů v reálném čase, když komunikují o konkrétních incidentech. To vám umožní zachovat interakce ve vztahu k časové ose událostí později při závěrečném vyhodnocení incidentu.
Teď to spojíme s Logic App. Nejprve se podívejte na úplnou aplikaci, jak je znázorněno v Návrháři pro Logic Apps, a pak si ji projdeme krok za krokem.
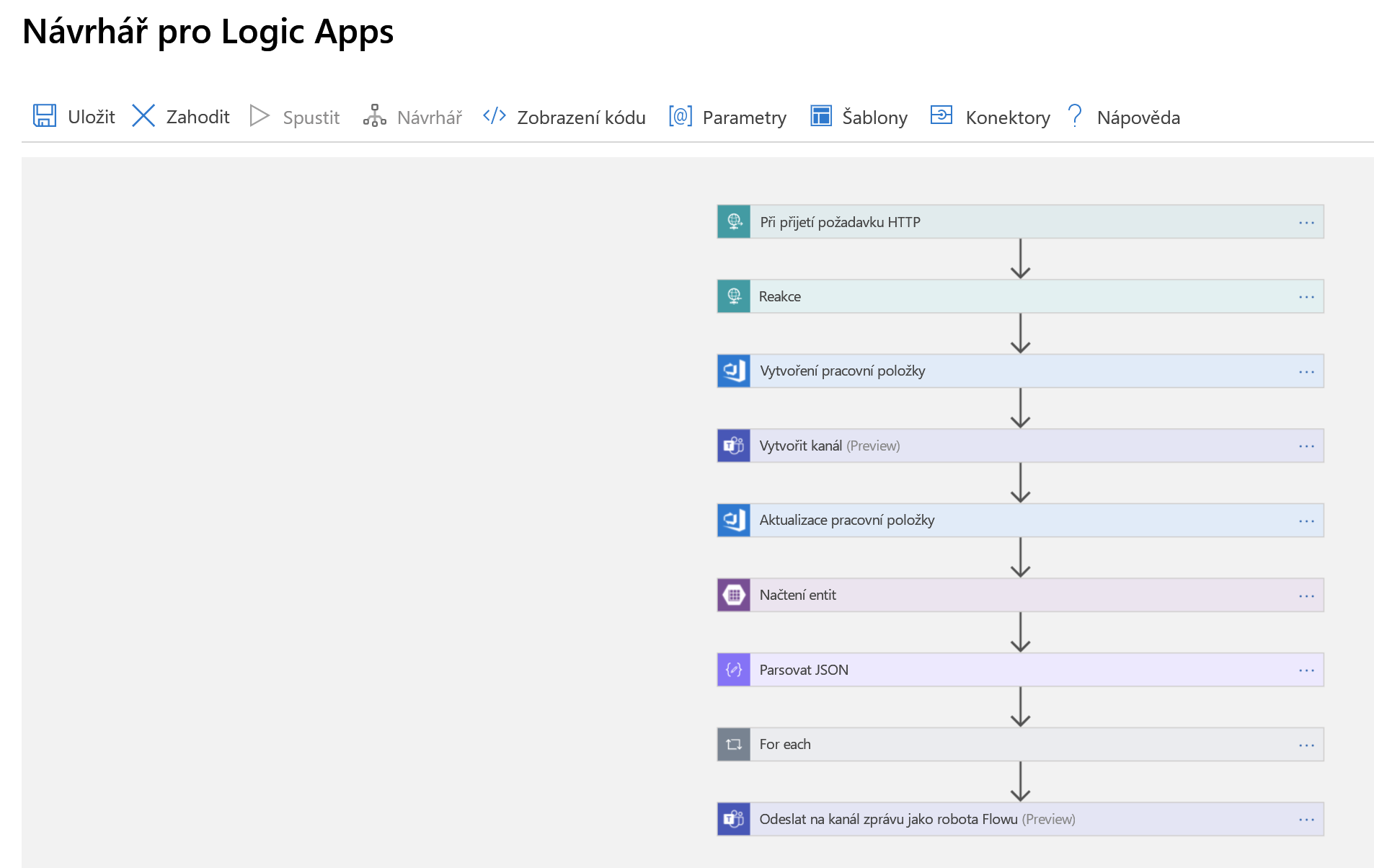
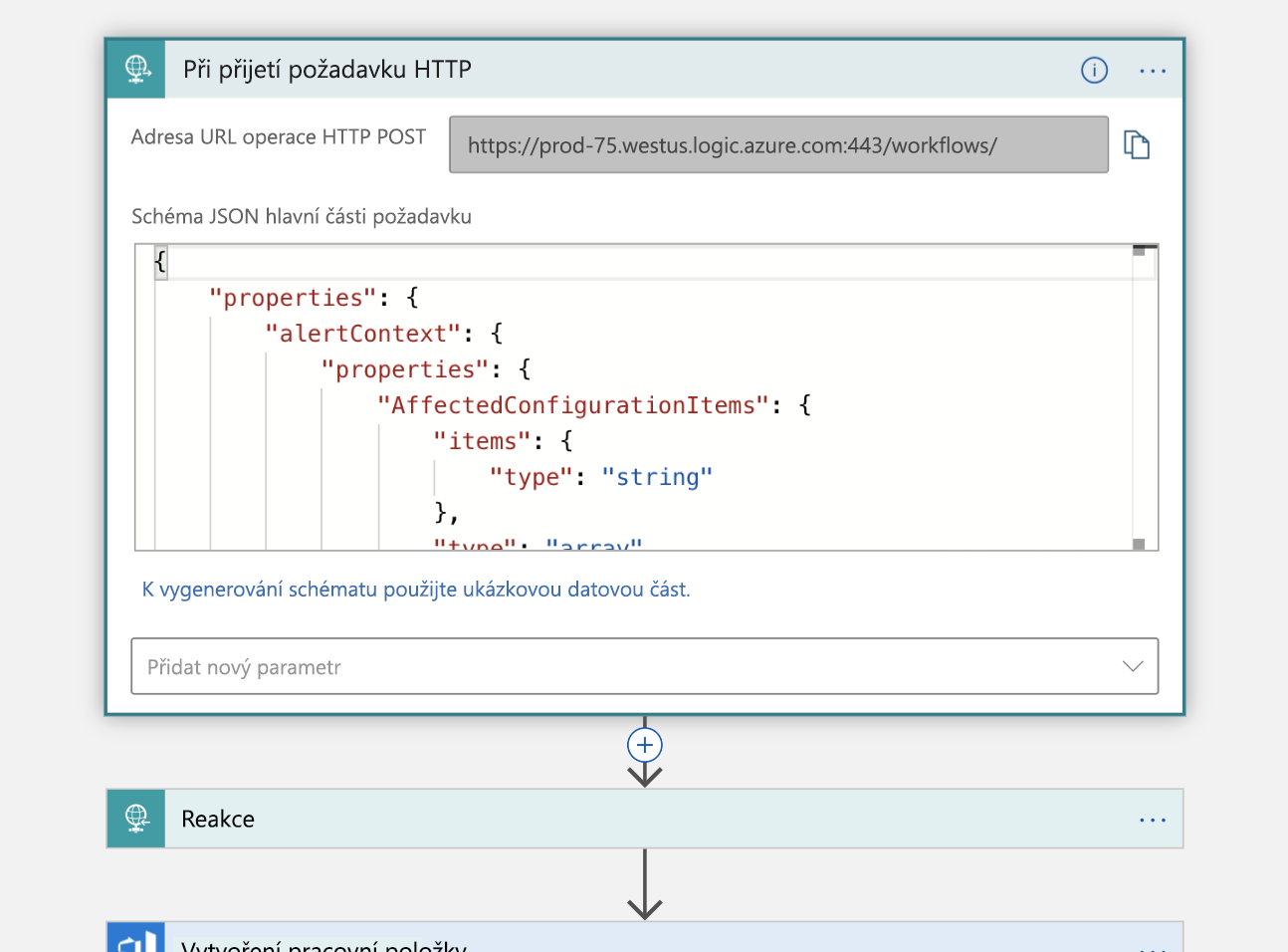
Prvním krokem je zpracování spouštěče, tedy toho požadavku HTTP, který jsme zmínili. Požadavek HTTP POST se provádí v naší aplikaci logiky, která obsahuje datovou část JSON s informacemi o incidentu, který chceme deklarovat. Tuto datovou část parsujeme a pošleme zpět potvrzení, které jsme obdrželi:
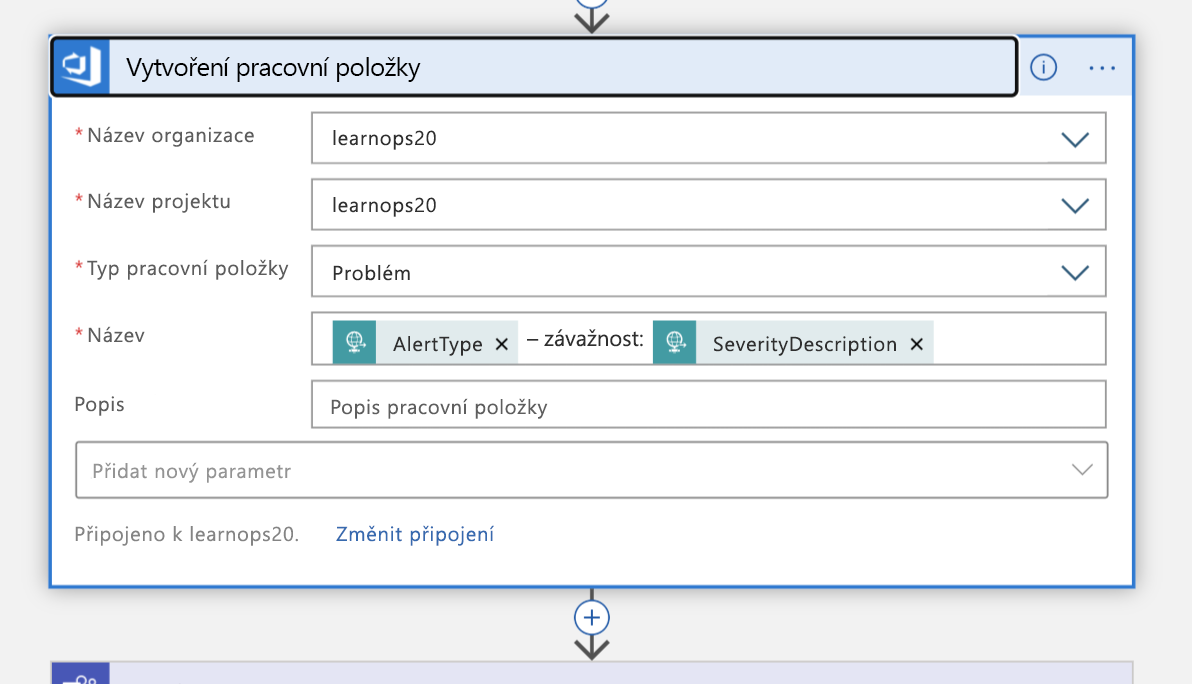
Pomocí těchto informací vytvoříme novou pracovní položku v organizaci Azure DevOps představující tento incident.
Potom vytvoří nový kanál Teams pro incident:
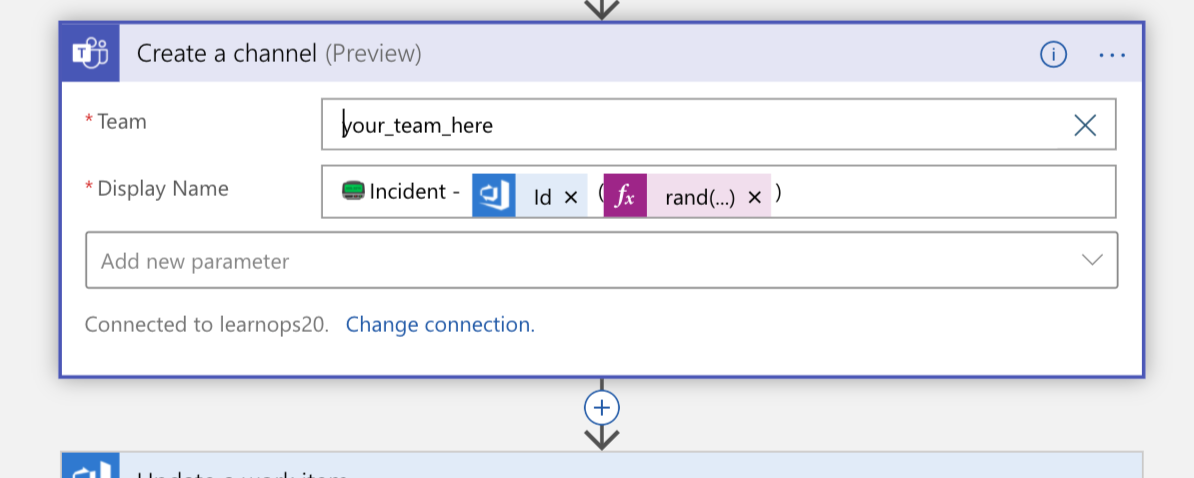
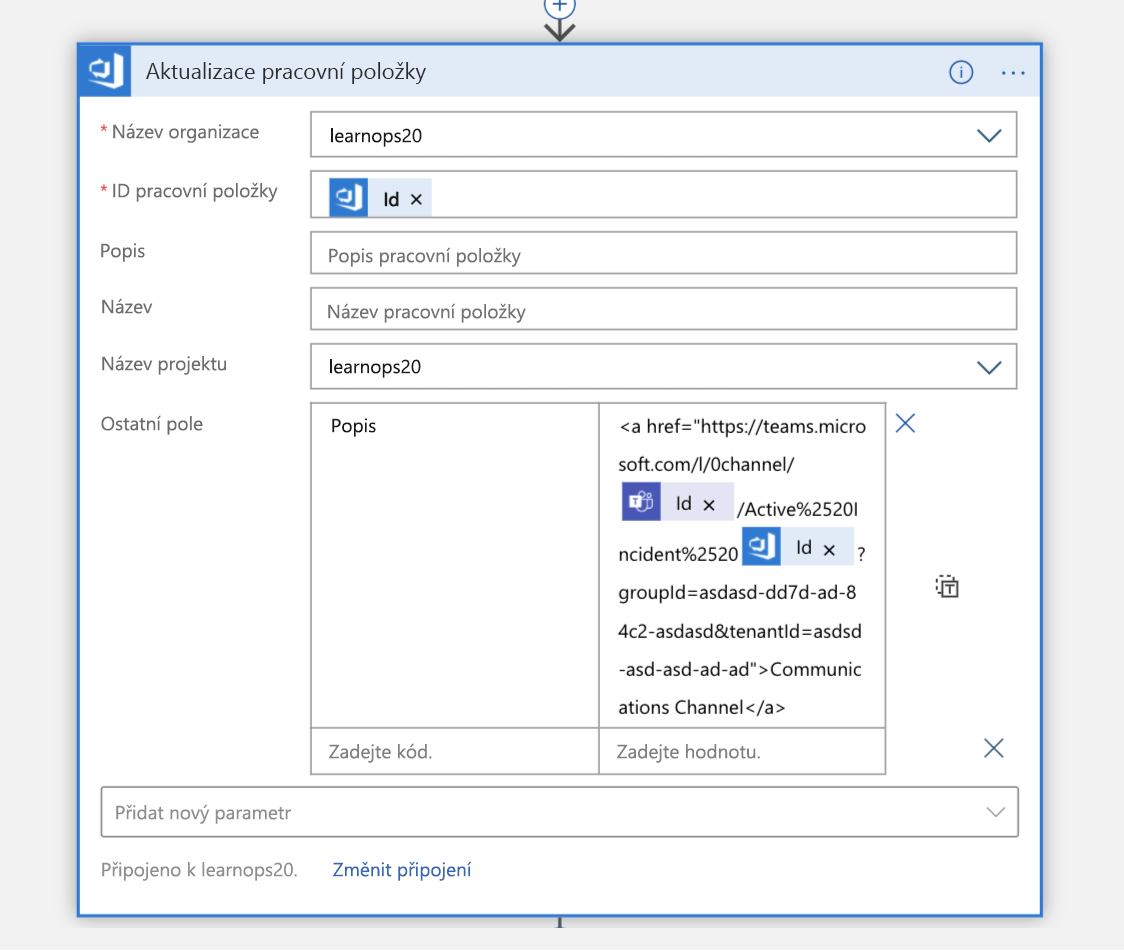
Po vytvoření kanálu se pracovní položka, kterou jsme vytvořili před okamžikem, aktualizuje odkazem na nový kanál. Tím se všechny informace zachovají na stejném místě (pracovní položka) a umožní uživatelům, kteří se na ni později dívají, zjistit, kam se mají dostat, pokud se chtějí připojit k tomuto kanálu.
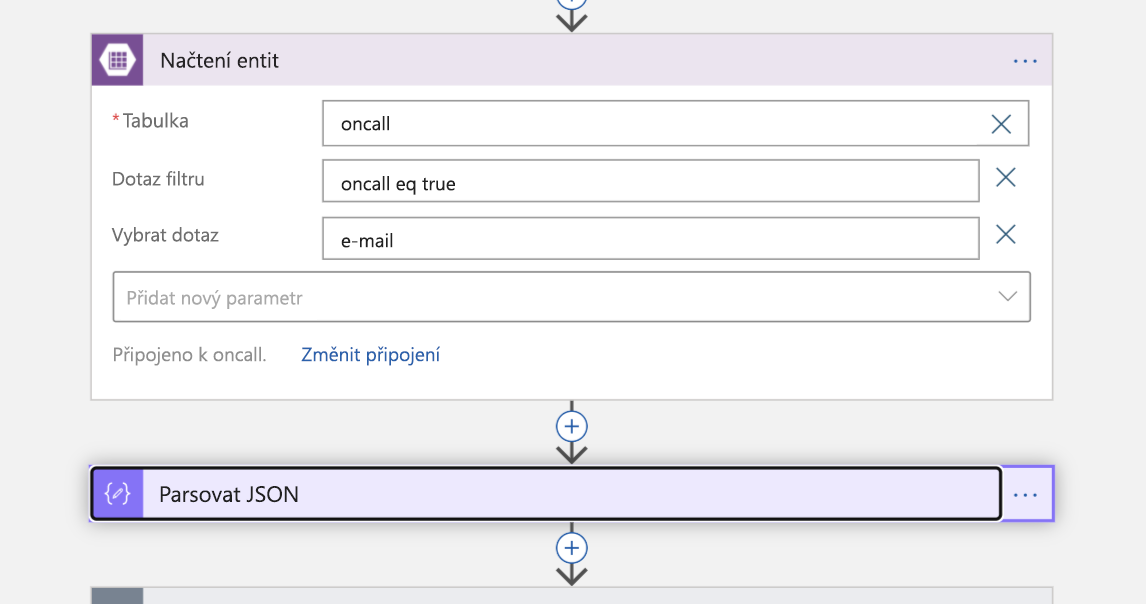
Teď je čas zapojit osobu na pohotovosti do situace. Ve službě Azure Table Storage provádíme vyhledávání pro e-mailovou adresu technika, který je uvedený jako on-call. Tím se vrátí odpověď JSON, kterou pak analyzujeme.
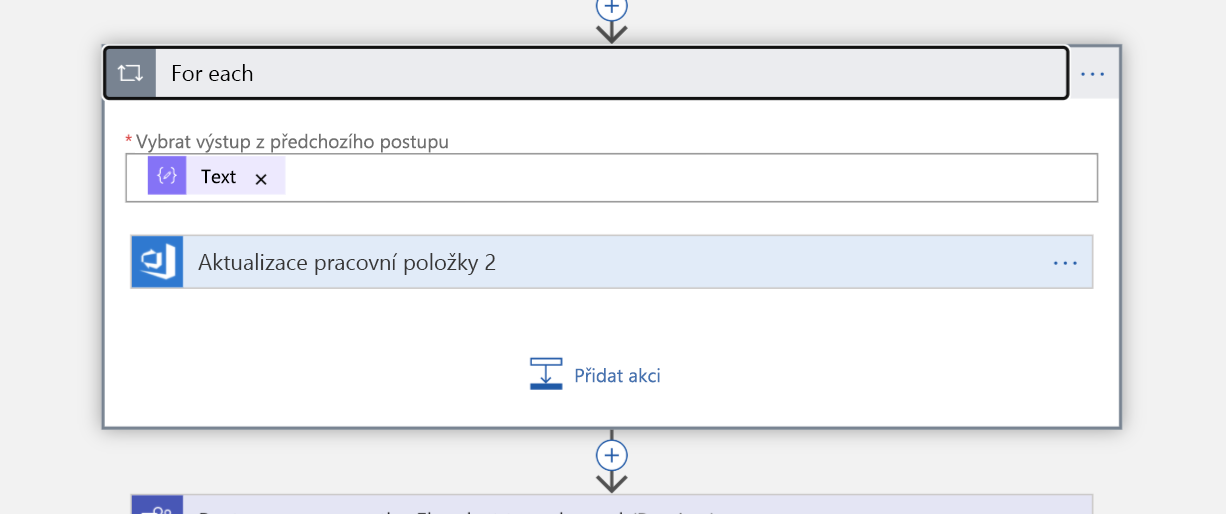
Protože náš dotaz vrátí seznam, musíme jako další krok iterovat jednotlivé položky v seznamu. Pracovní položku přiřadíme každé osobě (nyní jsou "vlastníci" incidentu).
Pak jako poslední krok pošleme do kanálu Teams zprávu s ukazatelem zpět na pracovní položku pro lidi, kteří se připojí k kanálu, a chceme vědět, kde jsou uložené autoritativní informace pro daný incident.
cs-CZ: 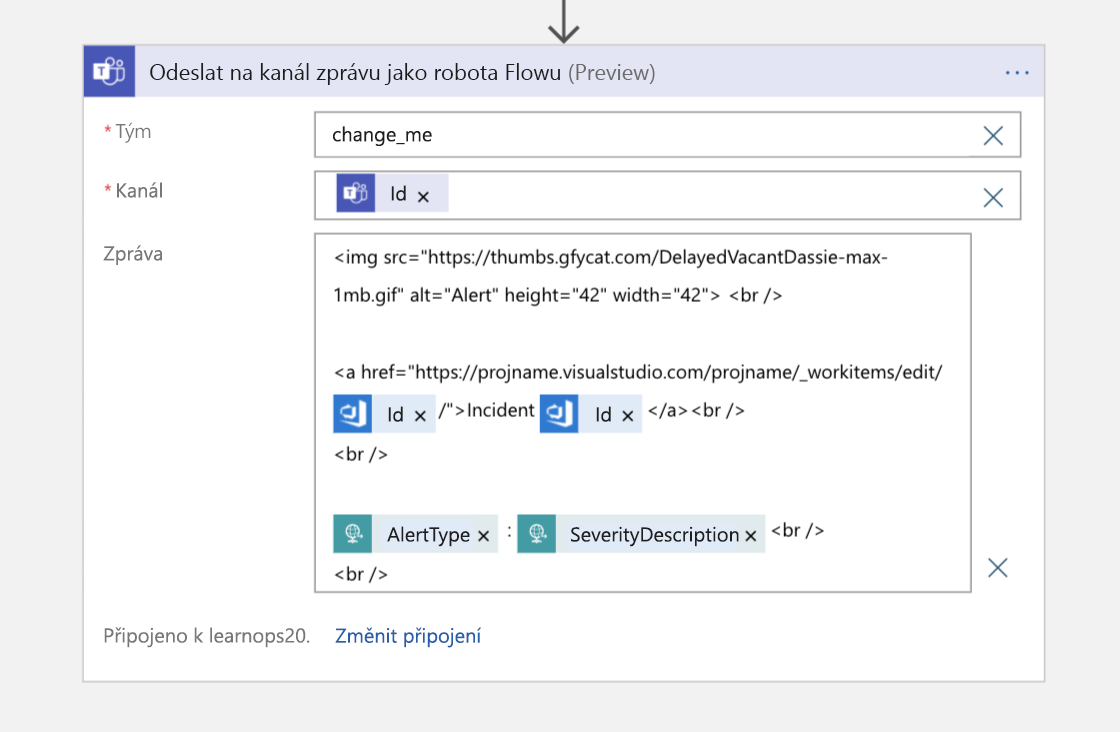
To je jen jeden příklad, jak můžeme automatizovat nastavení mechanismů pro sledování a komunikaci incidentů. V další lekci se podrobněji podíváme na aspekty komunikace kolem incidentu.