Modelování malých vyhledávacích entit
Náš datový model obsahuje dvě malé referenční datové entity ProductCategory a ProductTag. Tyto entity se používají pro referenční hodnoty a souvisejí s jinými entitami, i když .1:Many relationship
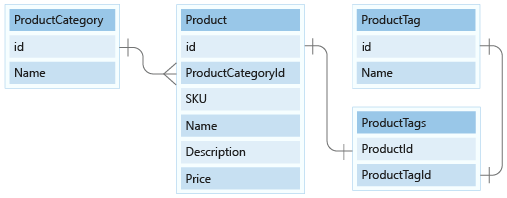
V této lekci modelujeme ProductCategory entity a ProductTag entity v našem modelu dokumentů.
Kategorie produktů modelu
Za prvé pro kategorie budeme modelovat data s id a názvy sloupců jako jediné vlastnosti a dát je do nového kontejneru volaný ProductCategory.
Dále musíme zvolit klíč oddílu. Pojďme prozkoumat operace, které musíme s daty provádět.
Vytvoříme novou kategorii produktu, upravíme kategorii produktu a pak vypíšeme všechny kategorie produktů. Vytváření a úpravy kategorií produktů nejsou často spouštěné operace. Naše aplikace pro elektronické obchodování bude často vypisovat všechny kategorie produktů, když zákazníci navštíví web. Poslední operace je tedy ta, která budeme spouštět nejvíce.
Dotaz na tuto poslední operaci bude vypadat takto: SELECT * FROM c.
S ID jako vybraným klíčem oddílu teď bude tento dotaz napříč oddíly, i když se chceme pokusit tyto operace náročné na čtení optimalizovat, pokud je to možné, použijte pouze jeden oddíl. Víme také, že data pro kategorii produktů se nikdy nezvětší o velikosti 20 GB, takže jak by nám tyto informace pomohly při modelování dat způsobem, který bude mít za následek dotaz na jeden oddíl, když vypíšeme všechny kategorie produktů.
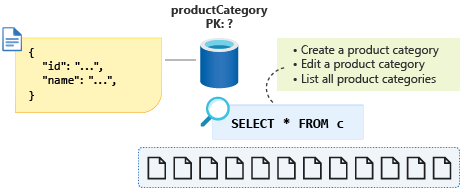
Abychom mohli tento malý objem dat převést zpět do jednoho oddílu, můžeme do schématu přidat nediskriminační vlastnost entity a použít ji jako klíč oddílu pro tento kontejner. Přiřazením této vlastnosti konstantní hodnotu pro všechny dokumenty tohoto typu v kontejneru zajistíme, že teď máme dotaz na jeden oddíl. V tomto případě zavoláme vlastnost type a poskytneme konstantní hodnotu category. Náš dotaz by teď vypadal takto: SELECT * FROM c WHERE c.type = ”category”.

Značky produktů modelu
V dalším kroku je entita ProductTag . Tato entita je téměř identická ve funkci s ProductCategory entitou, o které jsme mluvili v předchozí části. Pojďme sem použít stejný přístup a modelovat dokument tak, aby obsahoval vlastnosti ID a název a vytvořil entitu diskriminující vlastnost s názvem type, v tomto případě s konstantní hodnotou tag. Pojďme vytvořit nový kontejner s názvem ProductTag a vytvořit type nový klíč oddílu.
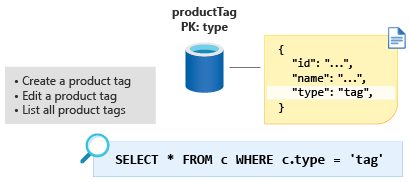
Někteří lidé najdou tuto techniku modelování malých vyhledávacích tabulek podivné. Modelování našich dat tímto způsobem nám ale dává příležitost provést další optimalizaci v dalším modulu.