Požadavky na přístup k hybridním souborům
Předchozí lekce se do značné míry zaměřily na to, co vaše řešení úložiště dělá. Tato lekce se zaměřuje na umístění dat. Konkrétně je potřeba zvážit přístup k hybridním souborům a jak k nim přistupovat.
Přehled hybridního přístupu k souborům
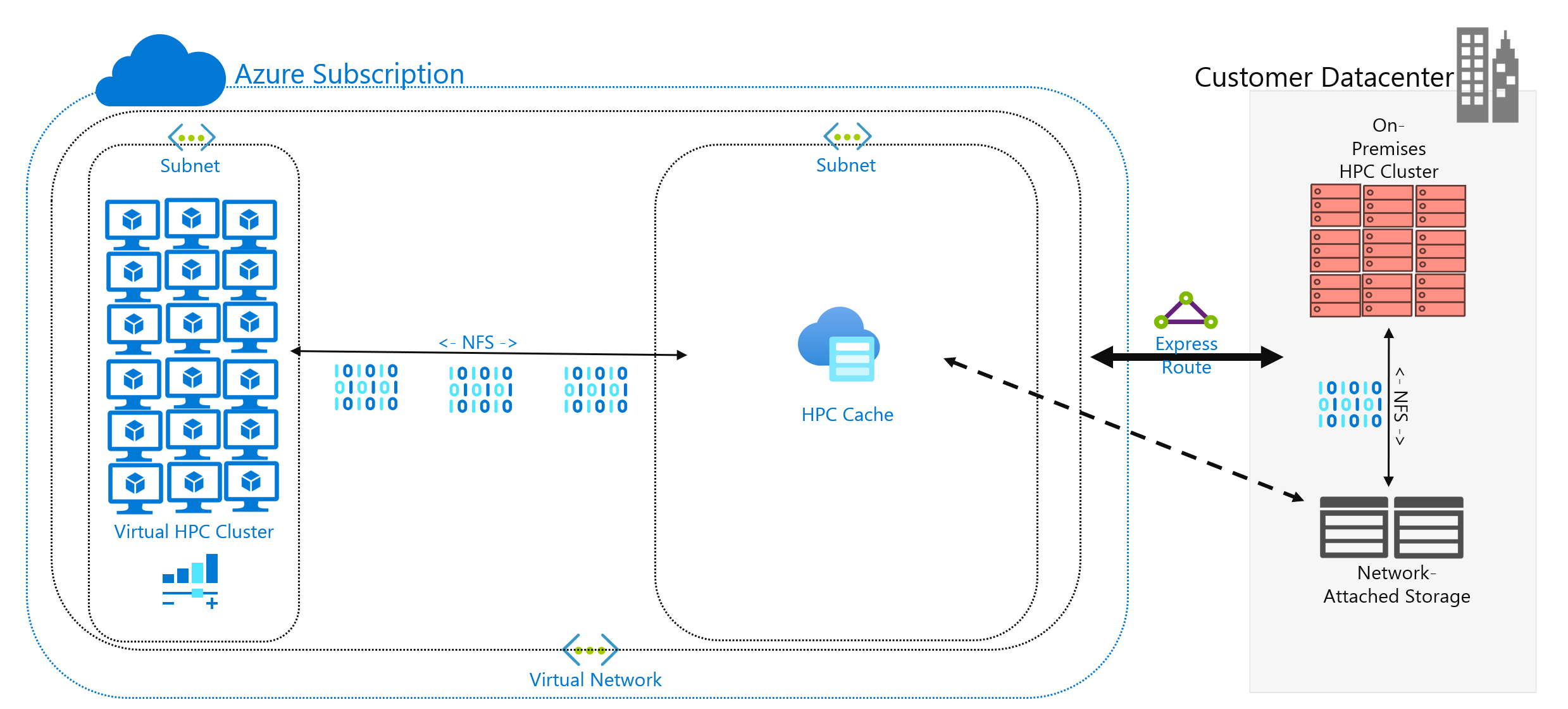
Rozhodli jste se spustit úlohu PROSTŘEDÍ HPC v Azure, která je aktuálně spuštěná ve vašem datacentru. Vaše výpočetní prostředí přistupuje k datům na vašem serveru NAS, který obsluhuje operace NFSv3 pro vaši úlohu. Běží tam už roky, ale možná vaše prostředí NAS dosahuje konce cyklu. Místo toho, abyste ho nahradili, zvažujete dlouhodobou migraci do cloudu.
Po provedení tohoto rozhodnutí, ale před úplným nasazením cloudu úlohy PROSTŘEDÍ HPC určíte strategii Azure a nastavíte základní účet, předplatné nebo nastavení zabezpečení. Teď je to těžké: přesouvání úloh PROSTŘEDÍ HPC!
Sestavení clusteru HPC a jeho roviny správy se nachází mimo rozsah tohoto modulu. Předpokládáme, že jste určili, které typy a množství virtuálních počítačů chcete v clusteru spustit.
Prozatím také předpokládáme, že vaším cílem je spustit úlohu tak, jak je. To znamená, že nechcete upravovat logiku ani metody přístupu aktuálně nasazené místně. Implikací je, že váš kód očekává, že data budou v adresářových cestách v místních systémech souborů členů clusteru.
Prvním cílem je porozumět požadovaným datům a jejich zdroji. Vaše data můžou být v jednom adresáři v jednom prostředí NAS nebo můžou být rozložená do různých prostředí.
Dalším cílem je určit, kolik dat je potřeba ke spuštění úlohy. Jsou zdrojová data několik gigabajtů, nebo jsou to stovky terabajtů?
Nakonec musíte určit, jak se data zobrazují ve výpočetních prostředcích Azure. Obsluhuje se místně na každém počítači clusteru HPC nebo ho sdílí cloudové řešení NAS?
Důležité informace o vzdáleném přístupu k datům
Máte úlohu genomiky, kterou chcete spustit v Azure. Vaše data se generují místně genovými sekvencery a odesílají se do místního prostředí NAS. Místní výzkumní pracovníci využívají data pro různá použití. Výzkumní pracovníci také můžou chtít využívat výsledky úloh PROSTŘEDÍ HPC, které chcete spustit v Azure. Některé z nich ale používají k tomu místní pracovní stanice. Předpokládejme také, že se pravidelně generují čerstvá genomická data. Takže máte omezený interval pro spuštění aktuální úlohy, než se data musí nahradit nebo aktualizovat.
Výzvou je prezentovat data výpočetním prostředkům Azure nákladově efektivním a včasným způsobem, ale stále zachovat místní přístup k výpočetním prostředkům.
Tady jsou některé hlavní otázky, které byste se měli zeptat, když se pokoušíte spouštět úlohy PROSTŘEDÍ HPC v Azure:
- Můžeme přesunout zdrojová data do Azure, aniž bychom museli uchovávat kopii místně?
- Můžeme ukládat data výsledků v úložišti Azure, aniž bychom museli uchovávat kopii místně?
- Potřebují místní uživatelé souběžný přístup ke zdrojovým nebo výsledkům dat?
- Pokud ano, můžou pracovat s daty v Azure nebo potřebují, aby se data ukládaly místně?
Pokud je potřeba data uchovávat místně, kolik dat se musí zkopírovat do Azure pro úlohu? Jak dlouho po zpracování dat potřebujete zpracovat novou sadu dat? Poběží vaše úloha v daném časovém rámci?
Musíte také zvážit síťové připojení k Azure. Máte k Azure přístup jenom k internetu? Toto omezení může být v pořádku v závislosti na velikosti dat, která se mají zkopírovat nebo přenést, a dobu mezi aktualizacemi. Možná máte velké množství dat, která se mají pokaždé zkopírovat. Možná budete potřebovat připojení wan (Wide Area Network) k Azure, které používá Azure ExpressRoute, což by poskytovalo větší šířku pásma pro kopírování a přenos dat.
Pokud už máte připojení ExpressRoute k Azure, tady je další důležité informace: jaká část připojení je k dispozici pro vaši operaci kopírování dat? Pokud je propojení silně nasycené, možná budete muset zvážit denní dobu přenosu dat. Nebo můžete chtít nakonfigurovat větší připojení ExpressRoute tak, aby vyhovovalo velkým přenosům dat.
Pokud přesunete data do Azure, možná budete muset zvážit, jak je zabezpečit. Můžete mít například místní prostředí systému souborů NFS, které používá adresářovou službu, která pomáhá rozšířit oprávnění uživatelům. Pokud plánujete toto zabezpečení zkopírovat do Azure, musíte se rozhodnout, jestli potřebujete adresářovou službu jako součást buildu Azure. Pokud je ale vaše úloha omezená na cluster PROSTŘEDÍ HPC a výsledky se přenesou zpět do místního prostředí, můžete tyto požadavky vynechat.
Dále se podíváme na metody přístupu k datům: ukládání do mezipaměti, kopírování a synchronizace.
Ukládání do mezipaměti vs. kopírování vs. synchronizace
Probereme obecné přístupy, které můžete použít k přidání dat do Azure. Fokus této diskuze o přenosu dat je aktivní data, nikoli archivace a zálohování dat.
Předpokládejme, že data přenášená v naší diskuzi jsou pracovní sadou úloh PROSTŘEDÍ HPC. V prostředí HPC pro životní vědy můžou data zahrnovat zdrojová data, jako jsou nezpracovaná genomická data, binární soubory používané ke zpracování dat nebo doplňující data, jako jsou referenční genomy. Musí být zpracována okamžitě po příjezdu nebo není dlouhá. Data musí být také uložena na médiu, které má odpovídající profil výkonu pro vstupně-výstupní operace za sekundu, latenci, propustnost a náklady. Naproti tomu archivní a zálohovaná data se nejčastěji přenášejí do nejnákladnějšího řešení úložiště, které není určené pro vysoce výkonný přístup.
Hlavní metody přenosu aktivních dat jsou ukládání do mezipaměti, kopírování a synchronizace. Pojďme si probrat výhody a nevýhody jednotlivých přístupů, počínaje kopírováním.
Kopírování dat je nejběžnějším přístupem k přesouvání dat. Data se kopírují různými způsoby v závislosti na používaném nástroji.
Zvažte tyto faktory:
- Velikost souborů.
- Počet souborů.
- Množství dostupné propustnosti pro přenos dat.
- Doba, po kterou musíte provést převod.
Základní nástroj pro kopírování, jako cp je vše, co potřebujete, pokud přenášíte několik souborů s rozumnou velikostí do vzdáleného cíle. Pravděpodobně budete chtít místo toho, scp cp abyste přenášeli data přes sítě, které nejsou zabezpečené: scp poskytuje šifrování přes připojení SSH (Secure Shell).
Existuje mnoho přístupů k optimalizaci operací kopírování v závislosti na tom, kde chcete kopírovat data. Pokud kopírujete soubory přímo do každého počítače prostředí HPC, můžete například naplánovat jednotlivé operace kopírování na každém uzlu.
Jednou z důležitých aspektů při kopírování dat mezi odkazy WAN je množství zkopírovaných souborů a složek. Pokud kopírujete mnoho malých souborů, chcete zkombinovat použití kopírování s archivem, jako tar je odebrání režijních nákladů na metadata z propojení WAN. Zkopírujte soubor .tar do Azure a zkopírujte data do počítačů.
Dalším problémem při kopírování je riziko přerušení. Pokud se například pokoušíte zkopírovat velký soubor a dochází k chybám přenosu, použití cp nefunguje, protože nemůže restartovat kopii tam, kde skončila.
Poslední obavou při kopírování dat je to, že vaše kopie může být zastaralá. Můžete například zkopírovat datovou sadu do Azure. Do té doby mohl místní uživatel aktualizovat jeden nebo více zdrojových souborů. Potřebujete určit proces, který zajistí, že používáte správná data.
Synchronizace dat je forma kopírování, ale je sofistikovanější. Nástroje, jako je rsync přidání možnosti synchronizace dat mezi zdrojem a cílem, kromě kopírování ze zdroje. rsync zajišťuje, že soubory jsou aktuální na základě data velikosti a změny souboru. Synchronizace umožňuje minimalizovat možnost použití zastaralých souborů.
rsync má schopnost obnovení. Pokud například kopírujete velký soubor a máte problémy s přenosem, můžete pokračovat z místa, rsync kde skončil.
rsync je zdarma a snadno se implementuje. Má možnosti nad rámec těch, které zde popisujeme. Umožňuje vytvořit synchronizovaný systém souborů v Azure na základě místních dat.
rsync má také omezení, která bychom měli zmínit. Nejprve je nástroj s jedním vláknem. Může běžet vždy jenom jednu operaci a nemůže paralelizovat přístup k datům. Nástroj cp kopírování je také s jedním vláknem. Tyto nástroje nejsou optimalizované pro rozsáhlé operace kopírování a synchronizace, které zahrnují velké objemy dat a krátké časové období. K synchronizaci dat musíte také spustit nástroj. Spuštění nástroje zvyšuje složitost vašeho prostředí, protože potřebujete zajistit, aby byl spuštěný podle vašich požadavků na časový rámec. Můžete chtít naplánovat skript, který obsahuje rsyncnapříklad. Tento přístup vyžaduje, abyste přidali protokolování skriptu pro případ, že dojde k problémům. Také to znamená, že potřebujete sledovat problémy. Úroveň složitosti může rychle růst.
Pokud používáte komerční řešení NAS, můžete si koupit nástroje pro synchronizaci na úrovni serveru, které jsou sofistikovanější a nabízejí výkon s více vlákny. Jakmile jsou tyto nástroje povolené a nakonfigurované, vždy fungují a synchronizují data mezi jedním nebo více zdroji a cíli.
Kopírování a synchronizace přenáší úplné kopie zdrojových dat. Úplný přenos souborů může být v pořádku pro menší datové sady nebo velikosti souborů. Pokud se zdrojová data skládají z mnoha velkých souborů, může do ní dojít k významným zpožděním. Čím více dat přenášíte, tím déle přenos trvá. Synchronizace zajišťuje, že do cloudu přidáváte jenom nové soubory. Ale tyto soubory je stále potřeba přenášet v plném rozsahu. V některých případech nemusí vaše úloha PROSTŘEDÍ HPC vyžadovat celou sadu souborů. Může vyžadovat přístup jenom k určitým oblastem souborů.
Ukládání dat do mezipaměti je třetí přístup k přidávání dat do Azure. Ukládání do mezipaměti odkazuje na načítání a prezentaci dat souborů prostřednictvím mezipaměti. Mezipaměť může být umístěna na jednotlivých místních klientech nebo může být distribuovanou mezipamětí, která obsluhuje všechny počítače HPC. Mezipaměti se obvykle používají k minimalizaci latence, takže umístění mezipaměti na hranici latence je optimálním přístupem k poskytování dat. Žádosti o data můžete například ukládat do mezipaměti napříč připojením WAN tak, že umístíte distribuovanou mezipaměť do výpočetních prostředků Azure, která je připojená k místnímu úložišti přes propojení WAN.
V tomto modulu odkazujeme konkrétně na ukládání souborů do mezipaměti, kde samotná mezipaměť ukládá požadavky z počítačů. Načte data z prostředí back-endového úložiště (jako je prostředí NAS systému souborů NFS) a tato data zobrazí klientům.
Výkon ukládání do mezipaměti je dvojí. Za prvé, mezipaměti nenačítají celé soubory. Mezipaměť načte požadovanou podmnožinu nebo rozsah bajtů souborů místo celých souborů. Načítání je založené na požadavcích klientů na tyto bajtové rozsahy. Tento přístup k načtení minimalizuje sankce za výkon při načítání celého velkého souboru v případě, že potřebujete jenom malou část souboru.
Za druhé, mezipaměti optimalizují opakovaný přístup k často požadovaným datům. Jakmile je rozsah bajtů v mezipaměti, budou pozdější požadavky na tato data rychlé. Jediným pomalým načtením je první načtení. Při spouštění velkého počtu klientů a vláken PROSTŘEDÍ HPC, které přistupují k běžné sadě souborů, si můžete uvědomit významné výhody.
Ukládání do mezipaměti nabízí další výhodu pro hybridní scénáře. Data jsou uložená v Azure (v mezipaměti) pouze přechodně. A ukládá se jenom během provozu úlohy PROSTŘEDÍ HPC. Můžete tak snížit logistickou režii spojenou s konkrétnějším přesunem dat do Azure. Můžete izolovat obavy týkající se ochrany osobních údajů a zabezpečení dat do mezipaměti a samotných počítačů HPC.
A konečně některá řešení ukládání do mezipaměti nabízejí to, co se nazývá kontrola atributů. Stejně jako synchronizace mezipaměť pravidelně kontroluje atributy souboru ve zdroji a načítá rozsahy bajtů, když je úprava souboru větší ve zdroji. Tato architektura zajišťuje, aby vaše prostředí PROSTŘEDÍ HPC vždy fungovalo s nejnovějšími daty.