Práce s Microsoft Fabric Lakehouses
Teď, když rozumíte základním funkcím Microsoft Fabric Lakehouse, pojďme se podívat, jak s jednou pracovat.
Vytvoření a prozkoumání jezera
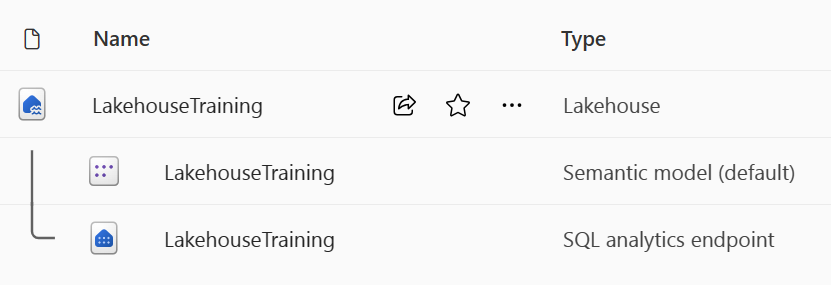
Při vytváření nového jezera máte ve svém pracovním prostoru automaticky vytvořené tři různé datové položky.
- Jezero obsahuje klávesové zkratky, složky, soubory a tabulky.
- Sémantický model (výchozí) poskytuje vývojářům sestav Power BI snadný zdroj dat.
- Koncový bod analýzy SQL umožňuje přístup jen pro čtení k dotazování dat pomocí SQL.
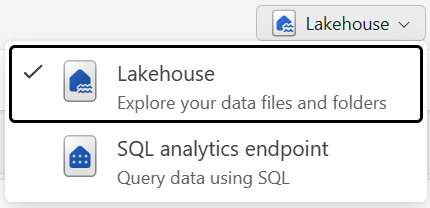
S daty v jezeře můžete pracovat ve dvou režimech:
- Lakehouse umožňuje přidávat tabulky, soubory a složky v jezeře a pracovat s nimi.
- Koncový bod SQL Analytics umožňuje použít SQL k dotazování tabulek v lakehouse a správě relačního sémantického modelu.
Příjem dat do jezera
Ingestování dat do jezera je prvním krokem procesu ETL. K přenesení dat do jezera použijte některou z následujících metod.
- Nahrání: Nahrajte místní soubory.
- Toky dat Gen2: Import a transformace dat pomocí Power Query
- Poznámkové bloky: Použití Apache Sparku k ingestování, transformaci a načítání dat
- Kanály služby Data Factory: Použijte aktivitu kopírování dat.
Tato data je pak možné načíst přímo do souborů nebo tabulek. Při ingestování dat zvažte způsob načítání dat a určete, jestli byste před zpracováním nebo použitím pracovních tabulek měli načíst všechna nezpracovaná data jako soubory.
Definice úloh Sparku je také možné použít k odesílání dávkových a streamovaných úloh do clusterů Spark. Nahráním binárních souborů z výstupu kompilace různých jazyků (například .jar z Javy) můžete na data hostovaná v jezeře použít odlišnou logiku transformace. Kromě binárního souboru můžete chování úlohy dále přizpůsobit tak, že nahrajete další knihovny a argumenty příkazového řádku.
Poznámka:
Další informace najdete v dokumentaci k vytvoření definice úlohy Apache Spark.
Přístup k datům pomocí klávesových zkratek
Dalším způsobem, jak získat přístup k datům a používat je v prostředcích infrastruktury, je použití klávesových zkratek. Klávesové zkratky umožňují integrovat data do jezera a přitom je uchovávat v externím úložišti.
Klávesové zkratky jsou užitečné, když potřebujete zdrojová data, která jsou v jiném účtu úložiště, nebo dokonce v jiném poskytovateli cloudu. V rámci lakehouse můžete vytvořit zástupce, které odkazují na různé účty úložiště a další položky infrastruktury, jako jsou datové sklady, databáze KQL a další lakehouse.
Oprávnění a přihlašovací údaje ke zdrojovým datům spravuje OneLake. Při přístupu k datům prostřednictvím zástupce jiného umístění OneLake se identita volajícího uživatele použije k autorizaci přístupu k datům v cílové cestě zástupce. Aby mohl uživatel číst data, musí mít v cílovém umístění oprávnění.
Klávesové zkratky je možné vytvořit v databázích lakehouse i KQL a zobrazit se jako složka v jezeře. Díky tomu může Spark, SQL, inteligence v reálném čase a Analysis Services využívat klávesové zkratky při dotazování dat.
Poznámka:
Další informace o tom, jak používat klávesové zkratky, najdete v dokumentaci ke zkratkám OneLake v dokumentaci k Microsoft Fabric.