Typy strojového učení
Existuje několik typů strojového učení a v závislosti na tom, co se pokoušíte předpovědět, musíte použít odpovídající typ. Rozdělení běžných typů strojového učení je znázorněno v následujícím diagramu.
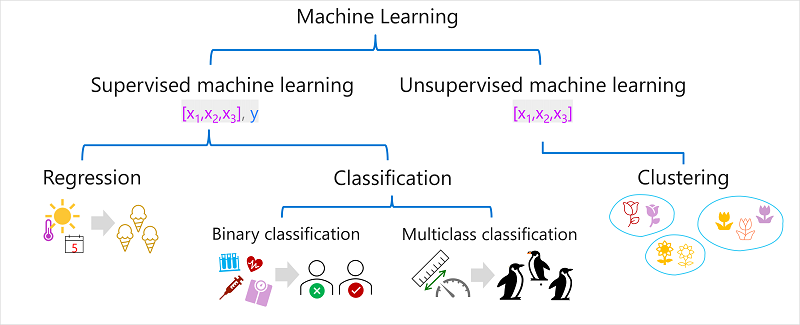
Strojové učení pod dohledem
Strojové učení pod dohledem je obecný termín pro algoritmy strojového učení, ve kterých trénovací data obsahují hodnoty funkcí i známé hodnoty popisků . Strojové učení pod dohledem se používá k trénování modelů určením vztahu mezi funkcemi a popisky v minulých pozorováních, takže neznámé popisky je možné předpovědět pro funkce v budoucích případech.
Regrese
Regrese je forma strojového učení pod dohledem, ve které je popisek predikovaný modelem číselnou hodnotou. Příklad:
- Počet zmrzlin prodaných v daný den na základě teploty, srážek a rychlosti větru.
- Prodejní cena nemovitosti na základě jeho velikosti na čtvereční stopy, počet ložnic, které obsahuje, a socioekonomické metriky pro svou polohu.
- Palivová účinnost (v kmech na gallon) auta na základě jeho velikosti motoru, hmotnosti, šířky, výšky a délky.
Klasifikace
Klasifikace je forma strojového učení pod dohledem, ve které popisek představuje kategorizaci nebo třídu. Existují dva běžné scénáře klasifikace.
Binární klasifikace
V binární klasifikaci popisek určuje, zda pozorovaná položka je (nebo není) instancí konkrétní třídy. Nebo můžete použít jiný způsob, jak binární klasifikační modely predikují jeden ze dvou vzájemně se vylučujících výsledků. Příklad:
- Zda pacient je ohrožen cukrovkou na základě klinických metrik, jako je hmotnost, věk, hladina glukózy v krvi atd.
- Zda bude bankovní zákazník splácet půjčku na základě příjmů, historie úvěru, věku a dalších faktorů.
- Jestli zákazník se seznamem adresátů bude reagovat na marketingovou nabídku pozitivně na základě demografických atributů a minulých nákupů.
Ve všech těchtopříkladch /
Klasifikace s více třídami
Vícetřídová klasifikace rozšiřuje binární klasifikaci tak, aby předpověděla popisek, který představuje jednu z více možných tříd. Příklad:
- Druh tučňáka (Adelie, Gentoo nebo Chinstrap) na základě jeho fyzických měření.
- Žánr filmu (komedie, horor, romantika, dobrodružství nebo sci-fi) na základě jeho přetypování, režiséra a rozpočtu.
Vevětšiněchch Například tučňák nemůže být Jak Gentoo , tak Adelie. Existují však také některé algoritmy, které můžete použít k trénování víceznakových klasifikačních modelů, ve kterých může existovat více než jeden platný popisek pro jedno pozorování. Film by mohl být například zařazen do kategorií jako sci-fi i komie.
Strojové učení bez dohledu
Strojové učení bez supervize zahrnuje trénovací modely využívající data, která se skládají jenom z hodnot funkcí bez jakýchkoli známých popisků. Algoritmy strojového učení bez supervize určují vztahy mezi funkcemi pozorování v trénovacích datech.
Clustering
Nejběžnější formou strojového učení bez supervize je clustering. Algoritmus clusteringu identifikuje podobnosti mezi pozorováními na základě jejich vlastností a seskupuje je do samostatných clusterů. Příklad:
- Seskupte podobné květiny podle jejich velikosti, počtu listů a počtu okvětních okvětních lístků.
- Identifikujte skupiny podobných zákazníků na základě demografických atributů a nákupního chování.
Clustering se některým způsobem podobá klasifikaci s více třídami; v tom, že kategorizuje pozorování do samostatných skupin. Rozdíl je v tom, že při použití klasifikace už znáte třídy, do kterých patří pozorování v trénovacích datech; algoritmus tedy funguje tak, že určí vztah mezi vlastnostmi a známým popiskem klasifikace. V clusteringu neexistuje žádný dříve známý popisek clusteru a algoritmus seskupuje pozorování dat čistě na základě podobnosti funkcí.
V některých případech se clustering používá k určení sady tříd, které existují před trénováním klasifikačního modelu. Pomocí clusteringu můžete například segmentovat zákazníky do skupin a pak tyto skupiny analyzovat, abyste identifikovali a kategorizovali různé třídy zákazníků (vysoká hodnota – nízký objem, časté malé nákupčí atd.). Pak můžete pomocí kategorizací označovat pozorování ve výsledcích clusteringu a pomocí označených dat vytrénovat klasifikační model, který predikuje, do jaké kategorie zákazníka může nový zákazník patřit.