Co jsou jazykové modely?
Generování aplikací umělé inteligence využívá jazykové modely, což je specializovaný typ modelu strojového učení, který můžete použít k provádění úloh zpracování přirozeného jazyka (NLP), mezi které patří:
- Určení mínění nebo jiné klasifikace textu přirozeného jazyka
- Shrnutí textu
- Porovnání více zdrojů textu pro sémantickou podobnost.
- Generování nového přirozeného jazyka
I když matematické principy těchto jazykových modelů můžou být složité, základní znalost architektury použité k jejich implementaci vám může pomoct pochopit, jak fungují.
Transformátorové modely
Modely strojového učení pro zpracování přirozeného jazyka se v průběhu mnoha let vyvinuly. Dnešní špičkové rozsáhlé jazykové modely jsou založené na architektuře transformátoru , která staví na a rozšiřuje některé techniky, které byly úspěšné při modelování slovníků , aby podporovaly úlohy NLP – a zejména generování jazyka. Transformátorové modely jsou trénovány s velkými objemy textu, což jim umožňuje znázornit sémantické vztahy mezi slovy a pomocí těchto relací určit pravděpodobné sekvence textu, které mají smysl. Transformátorové modely s dostatečně velkou slovní zásobou jsou schopné generovat odpovědi jazyka, které jsou obtížné odlišit od lidských odpovědí.
Architektura modelu Transformátor se skládá ze dvou součástí nebo bloků:
- Blok kodéru , který vytváří sémantické reprezentace trénovací slovník.
- Dekodérový blok, který generuje nové sekvence jazyka.
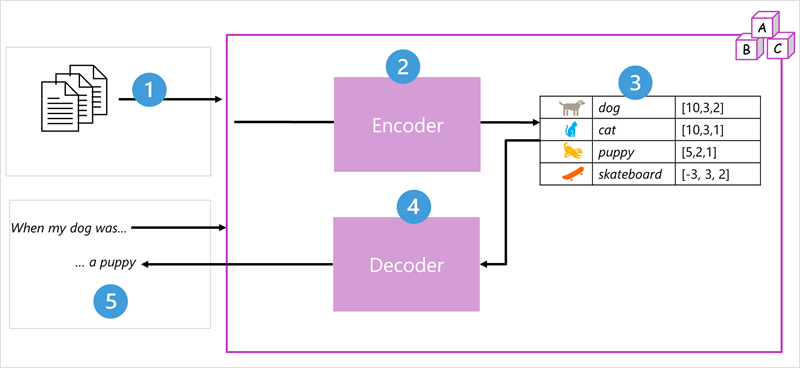
- Model se trénuje velkým objemem textu přirozeného jazyka, který je často zdrojem z internetu nebo jiných veřejných zdrojů textu.
- Sekvence textu jsou rozdělené na tokeny (například jednotlivá slova) a blok kodéru zpracovávají tyto sekvence tokenů pomocí techniky, která se označuje jako pozornost k určení vztahů mezi tokeny (například to, které tokeny ovlivňují přítomnost jiných tokenů v sekvenci, různé tokeny, které se běžně používají ve stejném kontextu atd.)
- Výstup z kodéru je kolekce vektorů (číselných polí s více hodnotami), ve kterých každý prvek vektoru představuje sémantický atribut tokenů. Tyto vektory se označují jako vložené.
- Blok dekodéru funguje na nové sekvenci textových tokenů a používá vkládání vygenerované kodérem k vygenerování odpovídajícího výstupu přirozeného jazyka.
- Například při zadání vstupní sekvence jako "Když byl můj pes", model může použít techniku pozornosti k analýze vstupních tokenů a sémantických atributů kódovaných ve vkládání, aby předpověděl odpovídající dokončení věty, například "štěňátko".
V praxi se konkrétní implementace architektury liší – například model Bidirectional Encoder Representations from Transformers (BERT) vyvinutý Společností Google pro podporu svého vyhledávacího webu používá pouze blok kodéru, zatímco model Generative Pretrained Transformer (GPT) vyvinutý openAI používá pouze blok dekodéru.
I když je úplné vysvětlení všech aspektů modelů transformátoru nad rámec tohoto modulu, vysvětlení některých klíčových prvků v transformátoru vám může pomoct získat představu o tom, jak podporují generativní AI.
Tokenizace
Prvním krokem při trénování modelu transformátoru je dekompilovat trénovací text do tokenů – jinými slovy, identifikovat každou jedinečnou textovou hodnotu. Z důvodu jednoduchosti si můžete představit jednotlivá slova v trénovacím textu jako token (i když ve skutečnosti se tokeny dají generovat pro částečná slova nebo kombinace slov a interpunkce).
Představte si například následující větu:
I heard a dog bark loudly at a cat
Pokud chcete tento text tokenizovat, můžete identifikovat jednotlivá slova a přiřadit jim ID tokenů. Příklad:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
Větu lze nyní reprezentovat tokeny: {1 2 3 4 5 6 7 3 8}. Podobně věta "Slyšel jsem kočku" by mohla být reprezentována jako {1 2 3 8}.
Při dalším trénování modelu se každý nový token v trénovacím textu přidá do slovníku s odpovídajícími ID tokenů:
- meow (9)
- skateboard (10)
- a tak dále...
S dostatečně velkou sadou trénovacího textu by se dala zkompilovat slovní zásoba mnoha tisíců tokenů.
Vkládání
I když může být vhodné reprezentovat tokeny jako jednoduchá ID – v podstatě vytváří index pro všechna slova ve slovníku, neříkají nám nic o významu slov ani vztahy mezi nimi. Abychom vytvořili slovní zásobu, která zapouzdřuje sémantické vztahy mezi tokeny, definujeme pro ně kontextové vektory označované jako vkládání. Vektory jsou číselné reprezentace informací s více hodnotami, například [10, 3, 1], ve kterých každý číselný prvek představuje konkrétní atribut informací. U jazykových tokenů představuje každý prvek vektoru tokenu určitý sémantický atribut tokenu. Konkrétní kategorie pro prvky vektorů v jazykovém modelu se určují během trénování na základě toho, jak se běžně používají slova společně nebo v podobných kontextech.
Vektory představují čáry v multidimenzionálním prostoru, popisující směr a vzdálenost podél více os (můžete zapůsobit na své matematické přátele voláním této amplitudy a velikosti). Může být užitečné uvažovat o prvcích vloženého vektoru tokenu jako představující kroky podél cesty v multidimenzionálním prostoru. Například vektor se třemi prvky představuje cestu v prostorovém prostoru, ve kterém hodnoty elementu označují jednotky posunuté vpřed/zpět, vlevo/vpravo a nahoru/dolů. Vektor celkově popisuje směr a vzdálenost cesty od původu do konce.
Prvky tokenů v prostoru pro vložení představují určitý sémantický atribut tokenu, takže sémantické podobné tokeny by měly mít za následek vektory, které mají podobnou orientaci – jinými slovy ukazují stejným směrem. K určení, zda dva vektory mají podobné směry (bez ohledu na vzdálenost), a proto představují sémanticky propojená slova. Jako jednoduchý příklad předpokládejme, že vkládání pro naše tokeny se skládá z vektorů se třemi prvky, například:
- 4 ("pes"): [10,3,2]
- 8 ("kočka"): [10,3,1]
- 9 ("štěňátko"): [5,2,1]
- 10 ("skateboard"): [-3,3,2]
Tyto vektory můžeme vykreslit ve trojrozměrném prostoru, například takto:
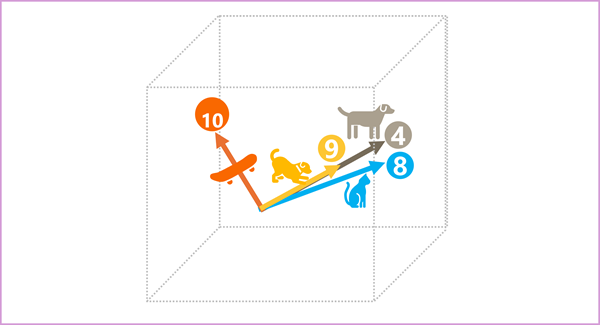
Vložené vektory pro "pes" a "štěňátko" popisují cestu po téměř identickém směru, což je také poměrně podobné směru pro "kočku". Vložený vektor pro "skateboard" však popisuje cestu velmi odlišným směrem.
Poznámka:
Předchozí příklad ukazuje jednoduchý ukázkový model, ve kterém má každé vložení pouze tři dimenze. Reálné jazykové modely mají mnohem více dimenzí.
Existuje několik způsobů, jak vypočítat vhodné vkládání pro danou sadu tokenů, včetně algoritmů jazykového modelování, jako je Word2Vec nebo blok kodéru v modelu transformátoru.
Pozornost
Bloky kodéru a dekodéru v modelu transformátoru obsahují více vrstev, které tvoří neurální síť modelu. Nemusíme zacházet do podrobností všech těchto vrstev, ale je užitečné zvážit jeden z typů vrstev, které se používají v obou blocích: vrstvy pozornosti . Pozornost je technika použitá k prozkoumání posloupnosti textových tokenů a pokusu o kvantifikaci síly vztahů mezi nimi. Zejména sebepozorování zahrnuje zvážení toho, jak ostatní tokeny kolem jednoho konkrétního tokenu ovlivňují význam tohoto tokenu.
V bloku kodéru se každý token pečlivě prozkoumá v kontextu a pro vložení vektoru se určí odpovídající kódování. Hodnoty vektoru jsou založeny na vztahu mezi tokenem a dalšími tokeny, se kterými se často vyskytuje. Tento kontextový přístup znamená, že stejné slovo může mít několik vkládání v závislosti na kontextu, ve kterém se používá – například "kůra stromu" znamená něco jiného než "Slyšel jsem psí kůru".
V bloku dekodéru se vrstvy pozornosti používají k predikci dalšího tokenu v posloupnosti. Pro každý vygenerovaný token má model vrstvu pozornosti, která bere v úvahu posloupnost tokenů až do tohoto bodu. Model se domnívá, které z tokenů jsou nejvýraznější při zvažování toho, co má být další token. Například vzhledem k sekvenci "Slyšel jsem psa", vrstva pozornosti může přiřadit větší váhu tokenům "slyšet" a "pes" při zvažování dalšího slova v sekvenci:
Slyšel jsem psa [štěkat]
Mějte na paměti, že vrstva pozornosti pracuje s číselnými vektorovými reprezentacemi tokenů, nikoli se skutečným textem. V dekodéru proces začíná posloupností vkládání tokenů představujících text, který se má dokončit. První věc, která se stane, je, že jiná vrstva pozičního kódování přidá do každého vkládání hodnotu, která označuje jeho pozici v posloupnosti:
- [1,5,6,2] (I)
- [2,9,3,1] (slyšet)
- [3,1,1,2] (a)
- [4,10,3,2] (pes)
Během trénování je cílem předpovědět vektor konečného tokenu v sekvenci na základě předchozích tokenů. Vrstva pozornosti přiřadí ke každému tokenu v posloupnosti dosud číselnou váhu . Tato hodnota používá k výpočtu vážených vektorů, které vytváří skóre pozornosti, které lze použít k výpočtu možného vektoru pro další token. V praxi technika označovaná jako vícesměrná pozornost používá různé prvky vkládání k výpočtu více skóre pozornosti. Neurální síť se pak použije k vyhodnocení všech možných tokenů k určení nejpravděpodobnějšího tokenu, se kterým chcete pokračovat v sekvenci. Proces pokračuje iterativním způsobem pro každý token v sekvenci, přičemž zatím se výstupní sekvence používá regresivně jako vstup pro další iteraci – v podstatě vytváří výstup po jednom tokenu najednou.
Následující animace ukazuje zjednodušenou reprezentaci toho, jak to funguje – ve skutečnosti jsou výpočty prováděné vrstvou pozornosti složitější; ale zásady lze zjednodušit, jak je znázorněno:

- Do vrstvy pozornosti se předá posloupnost vkládání tokenů. Každý token je reprezentován jako vektor číselných hodnot.
- Cílem dekodéru je předpovědět další token v sekvenci, což bude také vektor, který odpovídá vložení do slovníku modelu.
- Vrstva pozornosti vyhodnocuje zatím sekvenci a přiřazuje každému tokenu váhy, aby představovala jejich relativní vliv na další token.
- Váhy lze použít k výpočtu nového vektoru pro další token s skóre pozornosti. Pozornost více hlav používá různé prvky v vkládání k výpočtu více alternativních tokenů.
- Plně propojená neurální síť používá skóre v počítaných vektorech k predikci nejpravděpodobnějšího tokenu z celého slovníku.
- Zatím se k posloupnosti připojí predikovaný výstup, který se použije jako vstup pro další iteraci.
Během trénování je známa skutečná posloupnost tokenů – pouze maskujeme ty, které přicházejí později v posloupnosti, než je aktuálně považováno za pozici tokenu. Stejně jako v jakékoli neurální síti se predikovaná hodnota vektoru tokenu porovná se skutečnou hodnotou dalšího vektoru v sekvenci a ztráta se vypočítá. Váhy se pak postupně upraví, aby se snížila ztráta a zlepšila model. Při použití k odvozování (predikce nové posloupnosti tokenů) použije vytrénovaná vrstva pozornosti váhy, které predikují nejpravděpodobnější token ve slovníku modelu, který je zatím sémanticky zarovnaný sekvenci.
To vše znamená, že model transformátoru, jako je GPT-4 (model za ChatGPT a Bingem), je navržený tak, aby převzal textový vstup (označovaný jako výzva) a vygeneroval syntakticky správný výstup (označovaný jako dokončení). V důsledku toho "magie" modelu je, že má schopnost spojit souvislou větu dohromady. Tato schopnost neznamená žádné "znalosti" ani "inteligenci" na straně modelu; jen velká slovní zásoba a schopnost generovat smysluplné sekvence slov. Čím je ale velký jazykový model, jako je GPT-4, tak výkonný, je objem dat, se kterými byla trénována (veřejná a licencovaná data z internetu) a složitost sítě. To umožňuje modelu generovat dokončování založené na vztazích mezi slovy ve slovníku, na kterém byl model natrénován; často generuje výstup, který je nerozlišitelný od lidské odpovědi na stejnou výzvu.