Prozkoumání základních modelů v Azure Machine Učení
Pokud chcete vyladit základní model z katalogu modelů v Azure Machine Učení, můžete použít uživatelské rozhraní poskytované v sadě Studio, sadě Python SDK nebo Azure CLI.
Příprava dat a výpočetních prostředků
Než budete moct doladit základní model, abyste zlepšili výkon modelu, musíte připravit trénovací data a vytvořit výpočetní cluster GPU.
Tip
Když ve službě Azure Machine Učení vytvoříte výpočetní cluster GPU, vytvoří se pro vás virtuální počítač optimalizovaný pro GPU. Přečtěte si další informace o velikostech virtuálních počítačů GPU dostupných v Azure.
Trénovací data můžou být ve formátu JSON Lines (JSONL), CSV nebo TSV. Požadavky vašich dat se liší v závislosti na konkrétní úloze, pro kterou chcete model vyladit.
| Úloha | Požadavky na datovou sadu |
|---|---|
| Klasifikace textu | Dva sloupce: Sentence (řetězec) a Label (celé číslo/řetězec) |
| Klasifikace tokenů | Dva sloupce: Token (řetězec) a Tag (řetězec) |
| Odpovídání na dotazy | Pět sloupců: Question (řetězec), (řetězec), Answers Context (řetězec), Answers_start (int) a Answers_text (řetězec) |
| Souhrn | Dva sloupce: Document (řetězec) a Summary (řetězec) |
| Překlad | Dva sloupce: Source_language (řetězec) a Target_language (řetězec) |
Poznámka:
Vaše datová sada musí mít potřebné požadavky. Můžete ale použít různé názvy sloupců a namapovat sloupec na příslušný požadavek.
Až budete mít datovou sadu a výpočetní cluster připravený, můžete nakonfigurovat úlohu vyladění v Učení Azure Machine.
Volba základního modelu
Když přejdete do katalogu modelů v studio Azure Machine Learning, můžete prozkoumat všechny základní modely.
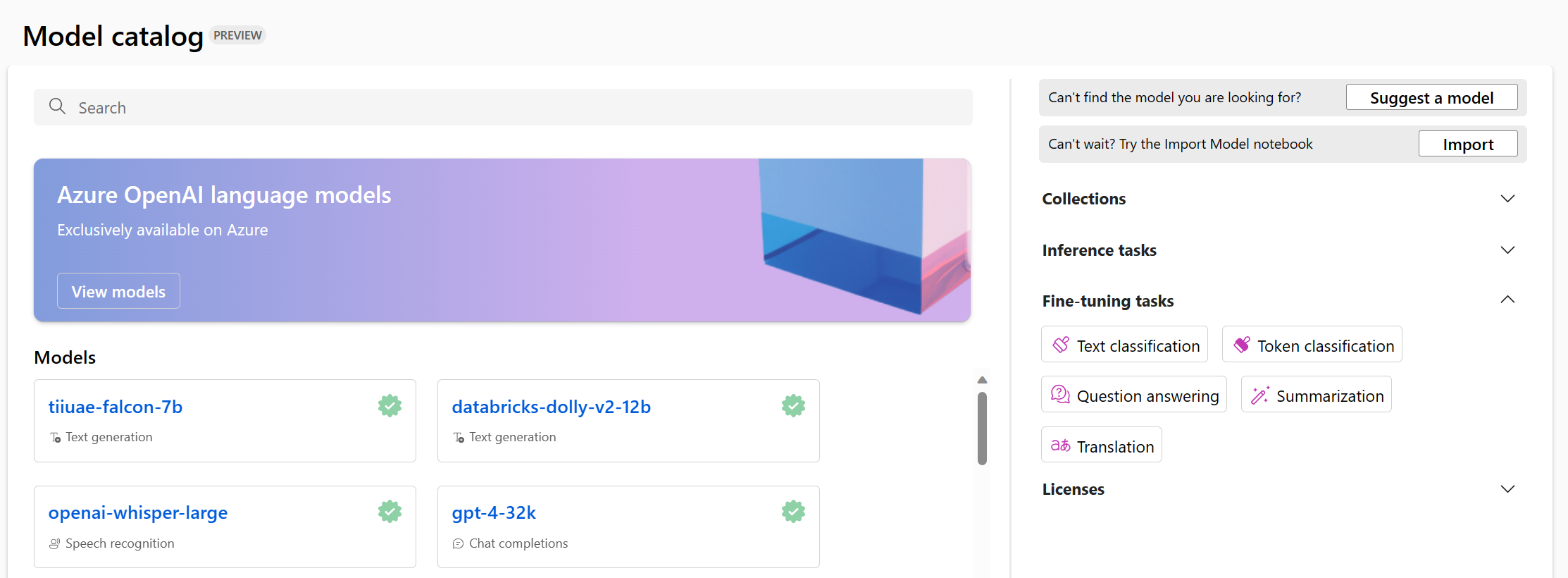
Dostupné modely můžete filtrovat na základě úlohy, pro kterou chcete model vyladit. Na každý úkol máte několik možností, ze kterých si můžete vybrat základní modely. Při rozhodování mezi základními modely pro úlohu můžete prozkoumat popis modelu a referenční kartu modelu.
Při rozhodování o základním modelu před vyladěním je potřeba vzít v úvahu některé aspekty:
- Možnosti modelu: Vyhodnoťte schopnosti základního modelu a jejich soulad s vaším úkolem. Například model, jako je BERT, je lepší pochopit krátké texty.
- Předtrénování dat: Zvažte datovou sadu použitou k předběžnému trénování základního modelu. Například GPT-2 je trénován na nefiltrovaný obsah z internetu, který může vést k předsudkům.
- Omezení a předsudky: Mějte na paměti všechna omezení nebo předsudky, které mohou být součástí základního modelu.
- Podpora jazyků: Prozkoumejte, které modely nabízejí konkrétní jazyková podpora nebo vícejazyčné funkce, které potřebujete pro váš případ použití.
Tip
I když studio Azure Machine Learning poskytuje popisy pro každý základní model v katalogu modelů, můžete také najít další informace o jednotlivých modelech prostřednictvím příslušné karty modelu. Na karty modelu se odkazuje v přehledu jednotlivých modelů a jsou hostované na webu Hugging Face.
Konfigurace jemně vyladěné úlohy
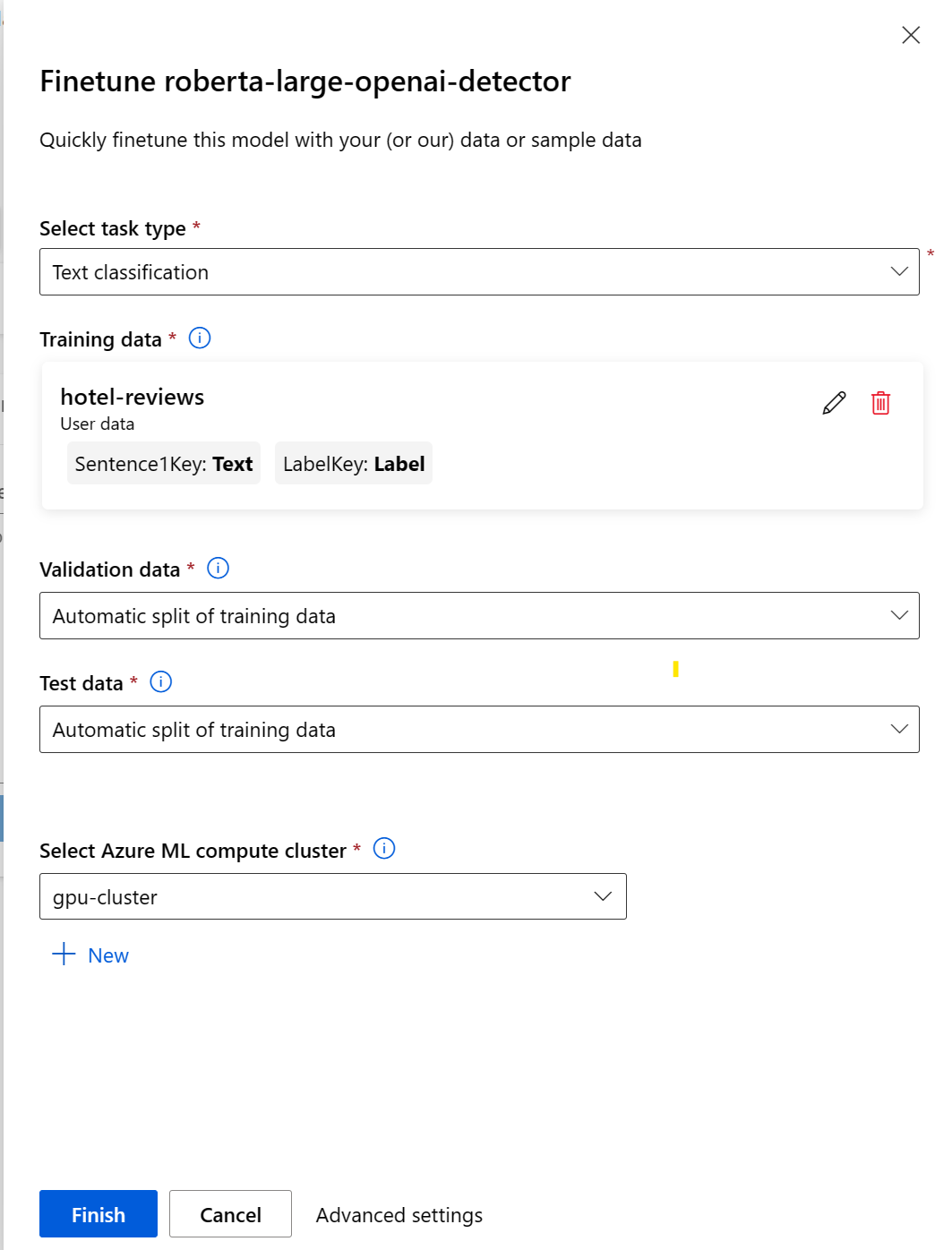
Pokud chcete nakonfigurovat úlohu vyladění pomocí studio Azure Machine Learning, musíte provést následující kroky:
- Zvolte základní model.
- Výběrem možnosti Finetune otevřete automaticky otevírané okno, které vám pomůže nakonfigurovat úlohu.
- Vyberte typ úkolu.
- Vyberte trénovací data a namapujte sloupce v trénovacích datech na požadavky na datovou sadu.
- Buď nechte Azure Machine Učení automaticky rozdělit trénovací data a vytvořit ověřovací a testovací datovou sadu, nebo poskytnout vlastní.
- Vyberte výpočetní cluster GPU spravovaný službou Azure Machine Učení.
- Výběrem možnosti Dokončit odešlete úlohu jemného ladění.
Tip
Volitelně můžete prozkoumat upřesňující nastavení a změnit nastavení, například název vyladěné úlohy a parametrů úkolu (například rychlost učení).
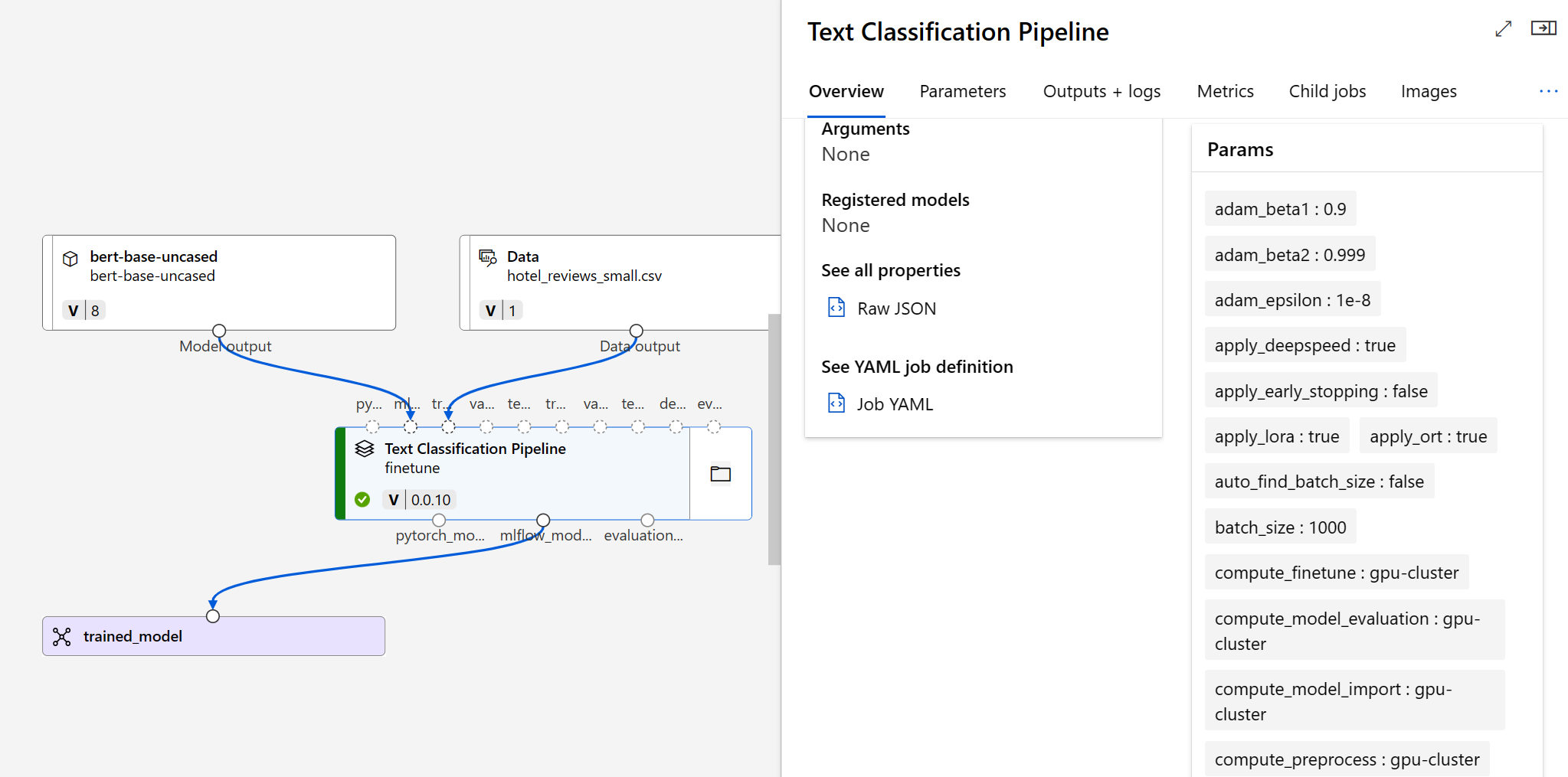
Po odeslání úlohy jemného ladění se vytvoří úloha kanálu pro trénování modelu. Můžete zkontrolovat všechny vstupy a shromáždit model z výstupů úlohy.