Návrh indexů
SQL Server má několik typů indexů, které podporují různé typy úloh. Na vysoké úrovni lze index považovat za strukturu na disku, která je přidružená k tabulce nebo zobrazení, která umožňuje SQL Serveru snadněji najít řádek nebo řádky přidružené k indexovacímu klíči (který se skládá z jednoho nebo více sloupců v tabulce nebo zobrazení) v porovnání s prohledáváním celé tabulky.
Clusterované indexy
Běžnou otázkou pracovního pohovoru DBA je položit kandidátovi rozdíl mezi clusterovaným a neclusterovaným indexem, protože indexy jsou základní technologií úložiště dat v SQL Serveru. Clusterovaný index je podkladová tabulka uložená v seřazených pořadí na základě hodnoty klíče. V dané tabulce může být pouze jeden clusterovaný index, protože řádky lze uložit v jednom pořadí. Tabulka bez clusterovaného indexu se nazývá halda a haldy se obvykle používají jenom jako pracovní tabulky. Důležitým principem návrhu výkonu je udržovat clusterovaný indexový klíč co nejužší. Při zvažování klíčových sloupců pro clusterovaný index byste měli zvážit sloupce, které jsou jedinečné nebo obsahují mnoho jedinečných hodnot. Další vlastností dobrého clusterovaného indexového klíče je záznam, ke kterým se přistupuje postupně, a často se používají k seřazení dat načtených z tabulky. Clusterovaný index ve sloupci použitém k řazení může zabránit nákladům na řazení při každém spuštění dotazu, protože data už budou uložená v požadovaném pořadí.
Poznámka:
Když říkáme, že tabulka je "uložená" v určitém pořadí, odkazujeme na logické pořadí, nikoli nutně fyzické pořadí na disku. Indexy mají ukazatele mezi stránkami a ukazatele pomáhají vytvořit logické pořadí. Při prohledávání indexu "v pořadí", SQL Server se řídí ukazateli ze stránky na stránku. Hned po vytvoření indexu je pravděpodobně uložena také ve fyzickém pořadí na disku, ale po zahájení úprav dat a nové stránky je potřeba přidat do indexu, ukazatele nám stále poskytnou správné logické pořadí, ale nové stránky budou pravděpodobně v pořadí fyzických disků.
Neclusterované indexy
Neclusterované indexy jsou samostatnou strukturou od řádků dat. Neclusterovaný index obsahuje hodnoty klíče definované pro index a ukazatel na řádek dat, který obsahuje hodnotu klíče. Na úroveň listu neclusterovaného indexu můžete přidat další neklíčový sloupec, který bude zahrnovat více sloupců pomocí funkce zahrnutých sloupců na SQL Serveru. V tabulce můžete vytvořit více neclusterovaných indexů.
Příklad, kdy potřebujete přidat index nebo přidat sloupce do existujícího neclusterovaného indexu, je vidět níže:

Plán dotazu označuje, že pro každý řádek načtený pomocí hledání indexu bude potřeba načíst další data z clusterovaného indexu (samotná tabulka). Existuje neclusterovaný index, ale obsahuje pouze sloupec produktu. Pokud přidáte ostatní sloupce v dotazu do neclusterovaného indexu, jak je znázorněno níže, uvidíte změnu plánu provádění, která eliminuje vyhledávání klíčů.

Index vytvořený výše je příkladem krytého indexu, kde kromě klíčového sloupce, který zahrnuje další sloupce pro pokrytí dotazu, a eliminuje potřebu přístupu k samotné tabulce.
Neclusterované i clusterované indexy je možné definovat jako jedinečné, což znamená, že neexistuje duplicita hodnot klíče. Jedinečné indexy se automaticky vytvoří při vytváření omezení PRIMÁRNÍ KLÍČ nebo UNIQUE v tabulce.
Tato část se zaměřuje na indexy b-strom v SQL Serveru – označují se také jako indexy úložiště řádků. Obecná struktura b-stromu je znázorněna níže:
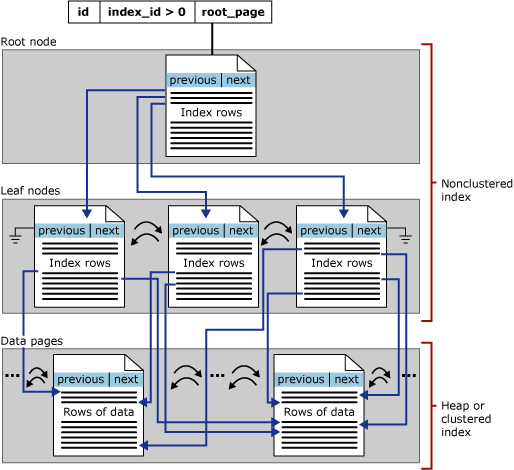
Každá stránka v indexu b-stromu je označovaná jako uzel indexu a horní uzel b-stromu se nazývá kořenový uzel. Dolní uzly v indexu se nazývají uzly typu list a kolekce uzlů typu list je úroveň listu.
Návrh indexu je směs umění a vědy. Úzký index s několika sloupci v klíči vyžaduje méně času k aktualizaci a má nižší režii na údržbu; ale nemusí být užitečné pro tolik dotazů jako širší index, který obsahuje více sloupců. Možná budete muset experimentovat s několika přístupy indexování na základě sloupců vybraných dotazy vaší aplikace. Optimalizátor dotazů obecně zvolí, co považuje za nejlepší existující index dotazu; To ale neznamená, že neexistuje lepší index, který by se dal sestavit.
Správné indexování databáze je složitá úloha. Při plánování indexů pro tabulku byste měli mít na paměti několik základních principů:
- Seznamte se s úlohami systému. Tabulka, která se používá hlavně pro operace vložení, bude těžit mnohem méně z extra indexů než tabulka použitá pro operace datového skladu, které jsou 90% aktivitou čtení.
- Seznamte se s nejčastějšími dotazy a optimalizujte indexy kolem těchto dotazů.
- Seznamte se s datovými typy sloupců použitých v dotazech. Indexy jsou ideální pro celočíselné datové typy nebo jedinečné nebo nenulové sloupce.
- Vytvořte neclusterované indexy u sloupců, které se často používají v predikátech a klauzulích join, a udržujte tyto indexy co nejužší, abyste se vyhnuli režijním nákladům.
- Pochopení velikosti a objemu dat – Prohledávání tabulek na malé tabulce bude poměrně levná operace a SQL Server se může rozhodnout provést prohledávání tabulky jednoduše, protože je snadné (triviální). Prohledávání tabulky ve velké tabulce by bylo nákladné.
Další možností SQL Serveru je vytvoření filtrovaných indexů. Filtrované indexy jsou nejvhodnější pro sloupce ve velkých tabulkách, kde velké procento řádků má stejnou hodnotu v daném sloupci. Praktickým příkladem by byla tabulka zaměstnanců, jak je znázorněno níže, která ukládala záznamy všech zaměstnanců, včetně těch, kteří odešli nebo vyřadili z důchodu.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
V této tabulce je sloupec s názvem CurrentFlag, který označuje, jestli je zaměstnanec aktuálně zaměstnaný. Tento příklad používá bitový datový typ označující pouze dvě hodnoty, jednu pro aktuálně použitou a nulu pro aktuálně použité. Filtrovaný index se sloupcem WHERE CurrentFlag = 1CurrentFlag by umožňoval efektivní dotazy aktuálních zaměstnanců.
Indexy můžete vytvořit také v zobrazeních, což může přinést významné zvýšení výkonu, když zobrazení obsahují prvky dotazu, jako jsou agregace nebo spojení tabulek.
Indexy Columnstore
Columnstore nabízí vylepšený výkon dotazů, které spouštějí velké agregační úlohy. Tento typ indexu byl původně zaměřen na datové sklady, ale v průběhu času se indexy columnstore používaly v mnoha dalších úlohách, aby pomohly vyřešit problémy s výkonem dotazů u velkých tabulek. Od SQL Serveru 2014 existují neclusterované i clusterované indexy columnstore. Podobně jako indexy b-tree je clusterovaný index columnstore samotnou tabulkou uloženou zvláštním způsobem a neclusterované indexy columnstore se ukládají nezávisle na tabulce. Clusterované indexy columnstore ze své podstaty zahrnují všechny sloupce v dané tabulce. Na rozdíl od clusterovaných indexů rowstore se však clusterované indexy columnstore neřadí.
Neclusterované indexy columnstore se obvykle používají ve dvou scénářích, první je, když sloupec v tabulce obsahuje datový typ, který není podporován v indexu columnstore. Většina datových typů je podporovaná, ale index columnstore nepodporuje XML, CLR, sql_variant, ntext, text a obrázek. Vzhledem k tomu, že clusterovaný columnstore vždy obsahuje všechny sloupce tabulky (protože je to tabulka), je jedinou možností neclustered. Druhý scénář je filtrovaný index – tento scénář se používá v architektuře označované jako hybridní transakční analytické zpracování (HTAP), kde se data načítají do podkladové tabulky a současně se sestavy spouštějí v tabulce. Díky filtrování indexu (obvykle podle pole data) tento návrh umožňuje dobrý výkon vkládání i generování sestav.
Indexy columnstore jsou v jejich mechanismu úložiště jedinečné, protože každý sloupec v indexu je uložen nezávisle. Nabízí výhodu se dvěma násobky. Dotaz, který používá index columnstore, potřebuje jenom zkontrolovat sloupce potřebné k uspokojení dotazu, snížit celkový počet provedených vstupně-výstupních operací a umožňuje větší kompresi, protože data ve stejném sloupci budou pravděpodobně podobná v přírodě.
Indexy columnstore fungují nejlépe s analytickými dotazy, které prohledávají velké objemy dat, jako jsou tabulky faktů v datovém skladu. Počínaje SQL Serverem 2016 můžete rozšířit index columnstore o jiný neclusterovaný index b-stromu, což může být užitečné, pokud některé dotazy dělají vyhledávání s hodnotami singleton.
Indexy columnstore také využívají režim dávkového spouštění, který odkazuje na zpracování sady řádků (obvykle přibližně 900) najednou oproti databázovému stroji zpracovávající tyto řádky současně. Místo toho, aby se každý záznam načítal nezávisle a zpracovával, vypočítá dotazovací modul výpočet v dané skupině 900 záznamů. Tento model zpracování výrazně snižuje počet instrukcí procesoru.
SELECT SUM(Sales) FROM SalesAmount;
Dávkový režim může zajistit výrazné zvýšení výkonu oproti tradičnímu zpracování řádků. SQL Server 2019 obsahuje také dávkový režim pro data úložiště řádků. I když dávkový režim pro úložiště řádků nemá stejnou úroveň výkonu čtení jako index columnstore, analytické dotazy můžou zaznamenat až 5krát vyšší výkon.
Další výhody indexů columnstore nabízejí úlohám datového skladu optimalizovanou cestu načítání pro hromadné operace vkládání 102 400 řádků nebo více. Zatímco 102 400 je minimální hodnota, která se má načíst přímo do columnstore, každá kolekce řádků označovaná jako skupina řádků může být přibližně 1 024 000 řádků. Když budete mít méně, ale plnější, skupiny řádků zefektivní dotazy SELECT, protože kvůli načtení požadovaných záznamů je potřeba zkontrolovat méně skupin řádků. Tato načtení probíhají v paměti a jsou přímo načtena do indexu. U menších svazků se data zapisují do struktury b-stromu označované jako rozdílové úložiště a asynchronně se načtou do indexu.
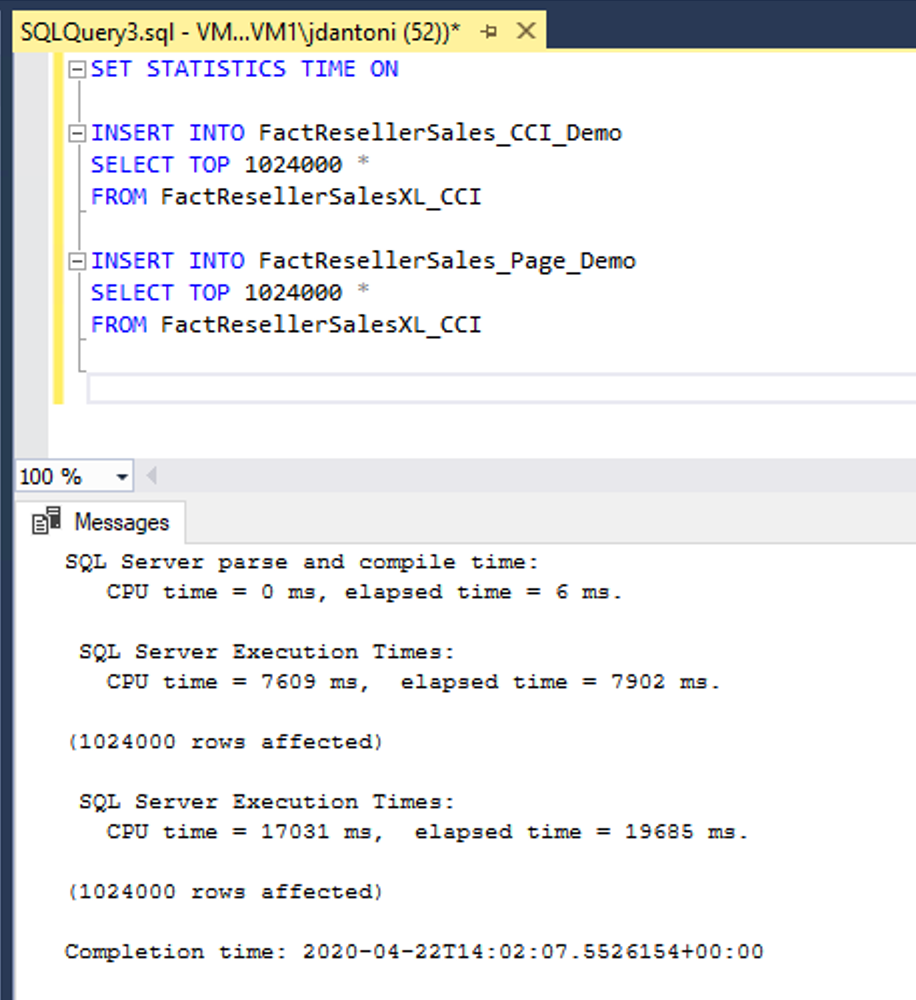
V tomto příkladu se stejná data načítají do dvou tabulek, FactResellerSales_CCI_Demo a FactResellerSales_Page_Demo. FactResellerSales_CCI_Demo má clusterovaný index columnstore a FactResellerSales_Page_Demo má skupinový index b-stromu se dvěma sloupci a je komprimovaný. Jak vidíte, každá tabulka načítá 1 024 000 řádků z tabulky FactResellerSalesXL_CCI . Kdy SET STATISTICS TIME je ON, SQL Server sleduje uplynulý čas provádění dotazu. Načtení dat do tabulky columnstore trvalo přibližně 8 sekund, kdy načítání do komprimované tabulky stránky trvalo téměř 20 sekund. V tomto příkladu se všechny řádky, které přejdou do indexu columnstore, načtou do jedné skupiny řádků.
Pokud do indexu columnstore načtete méně než 102 400 řádků dat v rámci jedné operace, načte se do struktury stromu b, která se označuje jako rozdílové úložiště. Databázový stroj přesune tato data do indexu columnstore pomocí asynchronního procesu označovaného jako mover řazené kolekce členů. Otevření rozdílových úložišť může ovlivnit výkon dotazů, protože čtení těchto záznamů je méně efektivní než čtení z columnstore. Index můžete také změnit COMPRESS_ALL_ROW_GROUPS tak, aby bylo možné vynutit přidání a komprimaci rozdílových úložišť do indexů columnstore.