Principy distribuce dat
Pochopení distribuce dat je nezbytné pro efektivní analýzu dat, vizualizaci a vytváření modelů.
Pokud datová sada obsahuje nerovnoměrnou distribuci, znamená to, že datové body nejsou rovnoměrně rozdělené a mají tendenci se přiklánět k pravému nebo levému rohu. To může vést k nepřesné predikci datových bodů z nedostatečně reprezentovaných skupin nebo optimalizaci na základě nevhodné metriky.
Důležitost distribuce dat
Níže jsou uvedené klíčové oblasti, kde pochopení distribuce dat může zvýšit přesnost modelů strojového učení.
| Krok | Popis |
|---|---|
| Průzkumná analýza dat (EDA) | Pochopení distribuce dat usnadňuje zkoumání nové datové sady a hledání vzorů. |
| Předběžné zpracování dat | Některé techniky předběžného zpracování, jako je normalizace nebo standardizace, se používají k tomu, aby byla data obvykle distribuovaná, což je běžný předpoklad v mnoha modelech. |
| Výběr modelu | Různé modely dělají různé předpoklady o distribuci dat. Některé modely například předpokládají, že se data obvykle distribuují a nemusí dobře fungovat, pokud je tento předpoklad porušen. |
| Zlepšení výkonu modelu | Transformace cílové proměnné, aby se snížila nerovnoměrná distribuce, může linearizovat cíl, což je užitečné pro mnoho modelů. To může snížit rozsah chyby a potenciálně zlepšit výkon modelu. |
| Relevance modelu | Jakmile je model nasazený do produkčního prostředí, je důležité, aby zůstal relevantní v kontextu nejnovějších dat. Pokud dojde ke nerovnoměrné distribuci dat, to znamená, že se distribuce dat v produkčním prostředí změní z toho, co se použilo během trénování, může model vyjít z kontextu. |
Pochopení distribuce dat může vylepšit proces vytváření modelu. Umožňuje vytvořit přesnější předpoklady tím, že ve vašich funkcích a cíli identifikuje průměr, rozpětí a rozsah náhodné proměnné.
Pojďme se podívat na některé z nejběžnějších typů distribuce dat, jako jsou normální, binomické a jednotné distribuce.
Normální rozdělení
Normální rozdělení je reprezentováno dvěma parametry: střední hodnotou a směrodatnou odchylkou. Střední hodnota označuje, kde je křivka zvonu zarovnaná na střed, a směrodatná odchylka označuje rozdělení.
Podívejme se na příklad normální distribuované funkce. Následující kód vygeneruje data pro var funkci pro demonstrační účely.
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Set the mean and standard deviation
mu, sigma = 0, 0.1
# Generate a normally distributed variable
var = np.random.normal(mu, sigma, 1000)
# Create a histogram of the variable using seaborn's histplot
sns.histplot(var, bins=30, kde=True)
# Add title and labels
plt.title('Histogram of Normally Distributed Variable')
plt.xlabel('Value')
plt.ylabel('Frequency')
# Show the plot
plt.show()
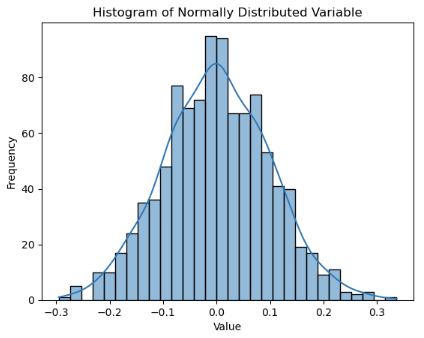
Všimněte si, že funkce je normálně distribuovaná var , kde se očekává, že střední hodnota a medián (50% percentil) budou větší nebo menší. U nerovnoměrných rozdělení má průměr tendenci se přiklonit k těžšímu ocasu.
Jedná se však o heuristické kontroly a skutečné stanovení se provádějí pomocí konkrétních statistických testů, jako je Shapiro-Wilk test nebo Test Kolmogorov-Smirnov pro normalitu.
Binomické rozdělení
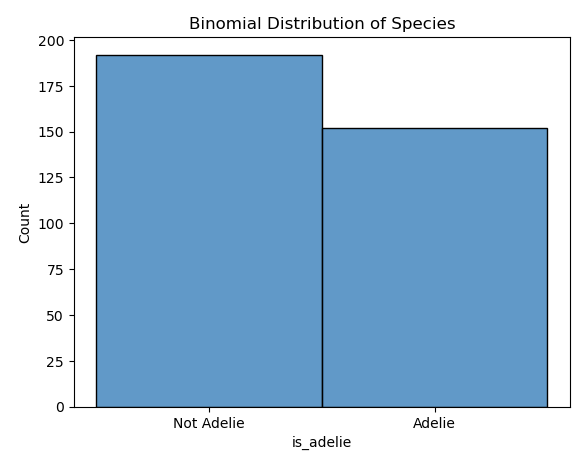
Předpokládejme, že chcete pochopit, jak dobře je určitá charakteristika pozorována ve skupině tučňáků.
Rozhodnete se prozkoumat datovou sadu 200 tučňáků, abyste zjistili, jestli jsou z druhu Adelie . Jedná se o binomický problém distribuce , protože existují dva možné výsledky (Adelie nebo ne Adelie), pevný počet pokusů (200 tučňáků) a každý pokus je nezávislý na ostatních.
Po analýze datové sady zjistíte, že 150 tučňáků je z druhu Adelie .
Když víte, že vaše data se řídí binomálním rozdělením, můžete vytvářet předpovědi o budoucích datových sadách nebo skupinách tučňáků. Pokud například studujete jinou skupinu 200 tučňáků, můžete očekávat, že přibližně 150 bude z druhu Adelie.
Následující kód Pythonu vykreslí histogram is_adelie binomické proměnné. Argument discrete=True zajišťuje sns.histplot , že intervaly jsou považovány za diskrétní intervaly. To znamená, že každý pruh v histogramu přesně odpovídá jedné kategorii nebo logické hodnotě, což usnadňuje interpretaci grafu.
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# Load the Penguins dataset from seaborn
penguins = sns.load_dataset('penguins')
# Create a binomial variable for 'species'
penguins['is_adelie'] = np.where(penguins['species'] == 'Adelie', 1, 0)
# Plot the distribution of 'is_adelie'
sns.histplot(data=penguins, x='is_adelie', bins=2, discrete=True)
plt.title('Binomial Distribution of Species')
plt.xticks([0, 1], ['Not Adelie', 'Adelie'])
plt.show()
Jednotné rozdělení
Rovnoměrné rozdělení, označované také jako obdélníkové rozdělení, je typ rozdělení pravděpodobnosti, ve kterém jsou všechny výsledky stejně pravděpodobné. Každý interval se stejnou délkou podpory rozdělení má stejnou pravděpodobnost.
import numpy as np
import matplotlib.pyplot as plt
# Generate a uniform distribution
uniform_data = np.random.uniform(-1, 1, 1000)
# Plot the distribution
plt.hist(uniform_data, bins=20, density=True)
plt.title('Uniform Distribution')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
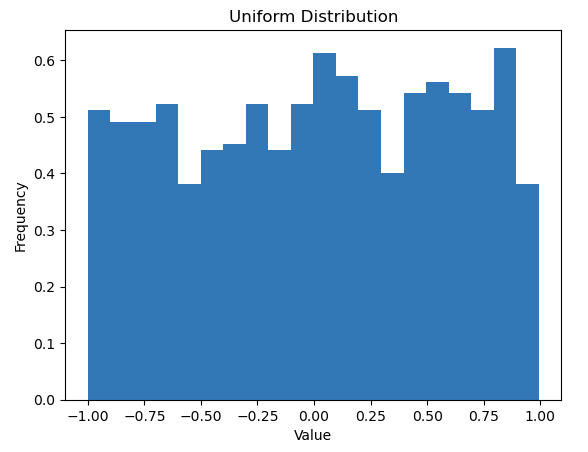
V tomto kódu np.random.uniform funkce generuje 1 000 náhodných čísel, která jsou rovnoměrně rozdělena mezi -1 a 1. Argument bins=30 určuje, že data by měla být rozdělena do 30 intervalů a density=True zajišťuje, aby histogram byl normalizován tak, aby vytvořil hustotu pravděpodobnosti. To znamená, že oblast pod histogramem se integruje do 1, což je užitečné při porovnávání rozdělení.
Poznámka:
Pokud kód spustíte několikrát, pravděpodobně dostanete jiné výsledky. Základní myšlenka náhodnosti spočívá v tom, že je nepředvídatelná a při každém vzorkování můžete získat různé výsledky.
Tento proces můžete řídit nastavením počáteční hodnoty pomocí np.random.seed. To je velmi užitečné pro testování a ladění ve fázi vytváření modelu, protože umožňuje reprodukovat stejné výsledky.