Vysvětlení možností PaaS pro nasazení SQL Serveru v Azure
Platforma jako služba (PaaS) poskytuje kompletní prostředí pro vývoj a nasazení v cloudu, které lze použít pro jednoduché cloudové aplikace i pro pokročilé podnikové aplikace.
Azure SQL Database a Azure SQL Managed Instance jsou součástí nabídky PaaS pro Azure SQL.
Azure SQL Database – součást řady produktů postavených na modulu SQL Serveru v cloudu. Poskytuje vývojářům velkou flexibilitu při vytváření nových aplikačních služeb a podrobných možností nasazení ve velkém měřítku. SQL Database nabízí řešení s nízkou údržbou, které může být skvělou volbou pro určité úlohy.
Azure SQL Managed Instance – Je nejvhodnější pro většinu scénářů migrace do cloudu, protože poskytuje plně spravované služby a možnosti.
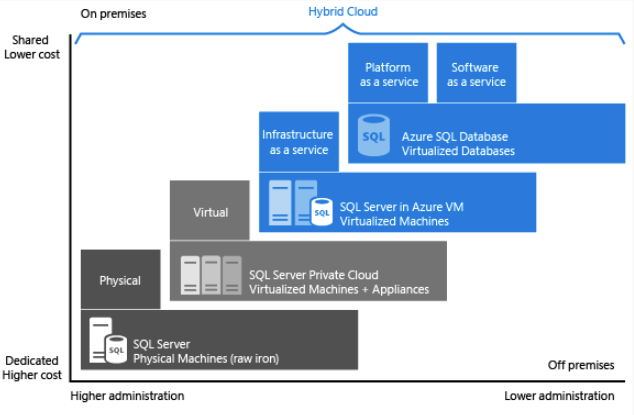
Jak je vidět na obrázku výše, každá nabídka poskytuje určitou úroveň správy, kterou máte v infrastruktuře, stupněm nákladové efektivity.
Modely nasazení
Azure SQL Database je k dispozici ve dvou různých modelech nasazení:
Jednoúčelová databáze – jedna databáze, která se účtuje a spravuje na úrovni databáze. Jednotlivé databáze spravujete jednotlivě z hlediska škálování a velikosti dat. Každá databáze nasazená v tomto modelu má vlastní vyhrazené prostředky, i když je nasazená na stejný logický server.
Elastické fondy – skupina databází, které se spravují společně a sdílejí společnou sadu prostředků. Elastické fondy poskytují nákladově efektivní řešení pro model aplikace softwaru jako služby, protože se prostředky sdílejí mezi všemi databázemi. Prostředky můžete nakonfigurovat na základě nákupního modelu založeného na jednotce DTU nebo nákupního modelu založeného na virtuálních jádrech.
Nákupní model
V Azure jsou všechny služby podporovány fyzickým hardwarem a můžete si vybrat ze dvou různých nákupních modelů:
Jednotka databázové transakce (DTU)
Jednotky DTU se počítají na základě vzorce, který kombinuje výpočetní prostředky, úložiště a vstupně-výstupní prostředky. Je to dobrá volba pro zákazníky, kteří chtějí jednoduché, předkonfigurované možnosti prostředků.
Nákupní model DTU se dodává v několika různých úrovních služeb, jako je Basic, Standard a Premium. Každá úroveň má různé možnosti, které poskytují širokou škálu možností při výběru této platformy.
Z hlediska výkonu se úroveň Basic používá pro méně náročné úlohy, zatímco Premium se používá pro náročné požadavky na úlohy.
Výpočetní prostředky a prostředky úložiště jsou závislé na úrovni DTU a poskytují celou řadu možností výkonu s pevným limitem úložiště, uchováváním záloh a náklady.
Poznámka:
Nákupní model DTU podporuje pouze Azure SQL Database.
Další informace o nákupním modelu DTU najdete v přehledu nákupního modelu založeného na DTU.
Virtuální jádro
Model virtuálních jader umožňuje zakoupit zadaný počet virtuálních jader na základě vašich zadaných úloh. Virtuální jádro je výchozí nákupní model při nákupu prostředků Azure SQL Database. Databáze virtuálních jader mají specifický vztah mezi počtem jader a velikostí paměti a úložištěm, které databáze poskytuje. Nákupní model virtuálních jader podporuje azure SQL Database a spravovanou instanci Azure SQL.
Databáze virtuálních jader můžete zakoupit i ve třech různých úrovních služeb:
Pro obecné účely – tato úroveň je určená pro úlohy pro obecné účely. Je zajištěná službou Azure Premium Storage. Bude mít vyšší latenci než Pro důležité obchodní informace. Poskytuje také následující úrovně výpočetních prostředků:
- Zřízeno – Výpočetní prostředky jsou předem přidělené. Fakturováno za hodinu na základě nakonfigurovaných virtuálních jader.
- Bezserverové – Výpočetní prostředky se automaticky škálují. Fakturováno za sekundu na základě použitých virtuálních jader.
Pro důležité obchodní informace – Tato úroveň je určená pro vysoce výkonné úlohy, které nabízejí nejnižší latenci obou úrovní služeb. Tato úroveň je podporována místními disky SSD místo úložiště objektů blob v Azure. Nabízí také nejvyšší odolnost proti selhání a také poskytuje integrovanou repliku databáze jen pro čtení, která se dá použít k úlohám generování sestav mimo zatížení.
Hyperscale – Databáze Hyperscale se můžou škálovat daleko nad rámec limitu 4 TB ostatních nabídek azure SQL Database a mají jedinečnou architekturu, která podporuje databáze až 100 TB.
Bezserverová architektura
Název "Bezserverový" může být trochu matoucí, protože azure SQL Database stále nasazujete na logický server, ke kterému se připojujete. Bezserverová úroveň Azure SQL Database je výpočetní úroveň, která automaticky vertikálně navyšuje nebo sníží kapacitu prostředků pro danou databázi na základě poptávky po úlohách. Pokud úloha už výpočetní prostředky nevyžaduje, databáze se "pozastaví" a během období, kdy je databáze neaktivní, se účtuje pouze úložiště. Při pokusu o připojení se databáze "obnoví" a zpřístupní se.
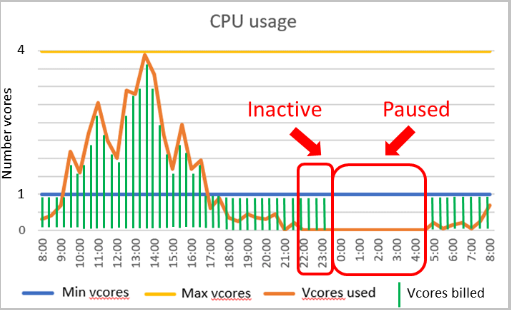
Nastavení pro řízení pozastavení se označuje jako zpoždění automatického pozastavení a má minimální hodnotu 60 minut a maximální hodnotu sedmi dnů. Pokud je databáze po danou dobu nečinná, pozastaví se.
Jakmile bude databáze po zadanou dobu neaktivní, pozastaví se až do následného pokusu o připojení. Konfigurace rozsahu automatického škálování výpočetních prostředků a zpoždění automatického pozastavení ovlivňuje výkon databáze a náklady na výpočetní prostředky.
Všechny aplikace používající bezserverovou architekturu by měly být nakonfigurované tak, aby zpracovávaly chyby připojení a zahrnovaly logiku opakování, protože připojení k pozastavené databázi vygeneruje chybu připojení.
Dalším rozdílem mezi bezserverovým a normálním modelem virtuálních jader služby Azure SQL Database je, že bez serveru můžete zadat minimální a maximální počet virtuálních jader. Omezení paměti a vstupně-výstupních operací jsou úměrná zadanému rozsahu.
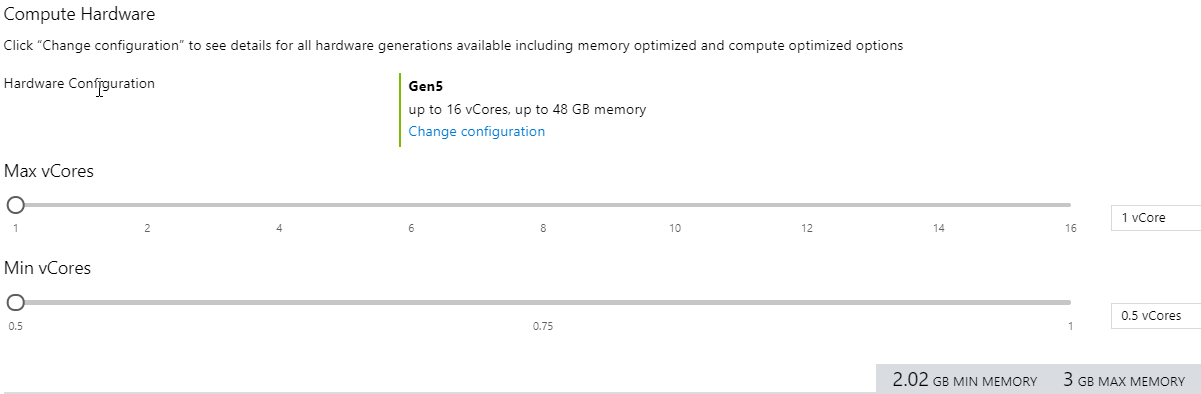
Na obrázku výše vidíte obrazovku konfigurace bezserverové databáze na webu Azure Portal. Máte možnost vybrat minimálně jako polovinu virtuálních jader a maximum až na 16 virtuálních jader.
Bezserverová služba není plně kompatibilní se všemi funkcemi ve službě Azure SQL Database, protože některé z nich vyžadují, aby se procesy na pozadí spouštěly vždy, například:
- Geografická replikace
- Dlouhodobé uchovávání záloh
- Databáze úloh v elastických úlohách
- Synchronizační databáze v Synchronizace dat SQL (Synchronizace dat je služba, která replikuje data mezi skupinou databází).
Poznámka:
Bezserverová služba SQL Database se v současné době podporuje pouze na úrovni Pro obecné účely v nákupním modelu virtuálních jader.
Zálohování
Jednou z nejdůležitějších funkcí nabídky Platformy jako služby je zálohování. V takovém případě se zálohy provádějí automaticky bez zásahu od vás. Zálohy se ukládají v geograficky redundantním úložišti objektů blob Azure a ve výchozím nastavení se uchovávají mezi 7 a 35 dny na základě úrovně služby databáze. Základní databáze a databáze virtuálních jader ve výchozím nastavení mají sedm dnů uchovávání a u databází virtuálních jader může tuto hodnotu upravit správce. Dobu uchovávání je možné prodloužit konfigurací dlouhodobého uchovávání (LTR), která vám umožní uchovávat zálohy po dobu až 10 let.
Abyste zajistili redundanci, můžete také použít geograficky redundantní úložiště objektů blob přístupné pro čtení. Toto úložiště by replikovalo zálohy databáze do sekundární oblasti podle vašich preferencí. V případě potřeby byste také mohli číst z této sekundární oblasti. Ruční zálohování databází se nepodporuje a platforma zamítne jakékoli žádosti o to.
Zálohy databáze se provádějí podle daného plánu:
- Plný – jednou týdně
- Rozdílový – každých 12 hodin
- Protokol – každých 5 až 10 minut v závislosti na aktivitě transakčního protokolu
Tento plán zálohování by měl splňovat potřeby většiny cílů bodu obnovení a času (RPO/RTO), ale každý zákazník by měl vyhodnotit, jestli splňuje vaše obchodní požadavky.
Pro obnovení databáze je k dispozici několik možností. Vzhledem k povaze platformy jako služby nemůžete databázi ručně obnovit pomocí konvenčních metod, jako je například vydání příkazu RESTORE DATABASET-SQL .
Bez ohledu na to, která metoda obnovení je implementována, není možné obnovit existující databázi. Pokud je potřeba obnovit databázi, musí být stávající databáze před zahájením procesu obnovení vyřazena nebo přejmenována. Mějte také na paměti, že v závislosti na úrovni služby platformy nejsou časy obnovení zaručené a můžou kolísat. Doporučujeme otestovat proces obnovení, abyste získali metriku směrného plánu, jak dlouho by mohlo obnovení trvat.
Dostupné možnosti obnovení:
Obnovení pomocí webu Azure Portal – Pomocí webu Azure Portal máte možnost obnovit databázi na stejný server Azure SQL Database nebo můžete pomocí obnovení vytvořit novou databázi na novém serveru v libovolné oblasti Azure.
Obnovení pomocí skriptovacího jazyka – K obnovení databáze je možné použít PowerShell i Azure CLI.
Poznámka:
Zálohování pouze kopírování do úložiště objektů blob v Azure je k dispozici pro službu SQL Managed Instance. SQL Database tuto funkci nepodporuje.
Další informace o automatizovaných zálohách najdete v tématu Automatizované zálohy – Azure SQL Database a Azure SQL Managed Instance.
Aktivní geografická replikace
Geografická replikace je funkce provozní kontinuity, která asynchronně replikuje databázi až do čtyř sekundárních replik. Vzhledem k tomu, že transakce jsou potvrzeny primární (a jeho repliky ve stejné oblasti), transakce se odesílají do sekundárních souborů, které se mají přehrát. Vzhledem k tomu, že se tato komunikace provádí asynchronně, volající aplikace nemusí čekat, až sekundární replika potvrdí transakci před sql Serverem, který vrací řízení volajícímu.
Sekundární databáze jsou čitelné a lze je použít k přesměrování zátěže jen pro čtení, čímž se uvolní prostředky pro transakční úlohy na primárním serveru nebo umístění dat blíže ke koncovým uživatelům. Sekundární databáze mohou být navíc ve stejné oblasti jako primární nebo v jiné oblasti Azure.
S geografickou replikací můžete zahájit převzetí služeb při selhání buď ručně uživatelem, nebo z aplikace. Pokud dojde k převzetí služeb při selhání, budete pravděpodobně muset aktualizovat aplikaci připojovací řetězec tak, aby odrážela nový koncový bod toho, co je teď primární databází.
Skupiny převzetí služeb při selhání
Skupiny převzetí služeb při selhání jsou postavené na technologii používané v geografické replikaci, ale poskytují jeden koncový bod pro připojení. Hlavním důvodem použití skupin převzetí služeb při selhání je, že technologie poskytuje koncové body, které je možné využít ke směrování provozu do příslušné repliky. Aplikace se pak může po převzetí služeb při selhání připojit bez připojovací řetězec změn.