Prozkoumání výkonu a zabezpečení
Ekosystém Azure nabízí několik možností výkonu a zabezpečení pro instanci SQL Serveru na virtuálním počítači Azure. Každá možnost nabízí několik možností, například různé typy disků, které splňují požadavky na kapacitu a výkon vaší úlohy.
Aspekty úložišť
SQL Server vyžaduje dobrý výkon úložiště pro zajištění robustního výkonu aplikace bez ohledu na to, jestli se jedná o místní instanci nebo nainstalovanou na virtuálním počítači Azure. Azure poskytuje širokou škálu řešení úložiště, která vyhovují potřebám vaší úlohy. Azure sice nabízí různé typy úložiště (objekt blob, soubor, fronta, tabulka) ve většině případů, kdy úlohy SQL Serveru budou používat spravované disky Azure. Výjimkou je, že instanci clusteru s podporou převzetí služeb při selhání je možné sestavit v úložišti souborů a zálohy budou používat úložiště objektů blob. Disky spravované v Azure fungují jako zařízení úložiště na úrovni bloků, které se prezentuje virtuálnímu počítači Azure. Spravované disky nabízejí řadu výhod, včetně 99,999% dostupnosti, škálovatelného nasazení (v případě selhání můžete mít až 50 000 disků virtuálních počítačů na předplatné a oblast) a integraci se skupinami dostupnosti a zónami.
Všechny disky spravované v Azure nabízejí dva typy šifrování. Šifrování na straně serveru poskytuje služba úložiště a funguje jako neaktivní uložená data šifrování poskytovaná službou úložiště. Azure Disk Encryption používá nástroj BitLocker ve Windows a DM-Crypt v Linuxu k zajištění šifrování operačního systému a datového disku uvnitř virtuálního počítače. Obě technologie se integrují se službou Azure Key Vault a umožňují používat vlastní šifrovací klíč.
Každý virtuální počítač bude mít přidružené alespoň dva disky:
Disk operačního systému – Každý virtuální počítač bude vyžadovat disk operačního systému, který obsahuje spouštěcí svazek. Tento disk by byl jednotkou C: v případě virtuálního počítače s platformou Windows nebo /dev/sda1 v Linuxu. Operační systém se automaticky nainstaluje na disk operačního systému.
Dočasný disk – Každý virtuální počítač bude obsahovat jeden disk používaný pro dočasné úložiště. Toto úložiště je určené k použití pro data, která nemusí být odolná, například stránkovací soubory nebo prohození souborů. Vzhledem k tomu, že je disk dočasný, neměli byste ho používat k ukládání důležitých informací, jako jsou soubory protokolů databáze nebo transakcí, protože během údržby nebo restartování virtuálního počítače dojde ke ztrátě. Tato jednotka se připojí jako D:\ ve Windows a /dev/sdb1 v Linuxu.
Kromě toho můžete a měli byste do virtuálních počítačů Azure s SQL Serverem přidat další datové disky.
- Datové disky – Datový disk se používá na webu Azure Portal, ale v praxi se jedná pouze o další spravované disky přidané do virtuálního počítače. Tyto disky je možné ve fondu využít ke zvýšení dostupné vstupně-výstupních operací za sekundu a kapacity úložiště pomocí Prostory úložiště ve Windows nebo správě logických svazků v Linuxu.
Každý disk může být navíc jedním z několika typů:
| Funkce | Disk úrovně Ultra | SSD úrovně Premium | SSD úrovně Standard | HDD úrovně Standard |
|---|---|---|---|---|
| Typ disku | SSD | SSD | SSD | HDD |
| Nejlepší pro | Úlohy náročné na vstupně-výstupní operace | Úloha citlivá na výkon | Zjednodušené úlohy | Zálohování, nekritické úlohy |
| Maximální velikost disku | 65 536 GiB | 32 767 GiB | 32 767 GiB | 32 767 GiB |
| Max. propustnost | 2 000 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Maximální IOPS | 160 000 | 20,000 | 6 000 | 2 000 |
Osvědčené postupy pro SQL Server v Azure doporučují použití disků Premium ve fondu pro zvýšení vstupně-výstupních operací za sekundu a kapacitu úložiště. Datové soubory by měly být uložené ve vlastním fondu s ukládáním do mezipaměti na discích Azure.
Soubory transakčních protokolů nebudou těžit z ukládání do mezipaměti, takže by tyto soubory měly jít do vlastního fondu bez ukládání do mezipaměti. TempDB může volitelně přejít do vlastního fondu nebo použít dočasný disk virtuálního počítače, který nabízí nízkou latenci, protože je fyzicky připojený k fyzickému serveru, na kterém jsou virtuální počítače spuštěné. Správně nakonfigurované ssd úrovně Premium uvidí latenci v milisekundách s jednou číslicí. U důležitých úloh, které vyžadují latenci nižší, byste měli zvážit ssd úrovně Ultra.
Bezpečnostní aspekty
Azure splňuje několik oborových předpisů a standardů, které umožňují vytvořit kompatibilní řešení s SQL Serverem běžícím na virtuálním počítači.
Microsoft Defender pro SQL
Microsoft Defender for SQL poskytuje funkce zabezpečení služby Azure Security Center, jako jsou posouzení ohrožení zabezpečení a výstrahy zabezpečení.
Azure Defender pro SQL je možné použít k identifikaci a zmírnění potenciálních ohrožení zabezpečení v instanci a databázi SQL Serveru. Funkce posouzení ohrožení zabezpečení může detekovat potenciální rizika v prostředí SQL Serveru a pomoct s jejich nápravou. Poskytuje také přehled o stavu zabezpečení a o krocích, které je možné provést při řešení problémů se zabezpečením.
Azure Security Center
Azure Security Center je jednotný systém správy zabezpečení, který vyhodnocuje a nabízí příležitosti ke zlepšení několika aspektů zabezpečení vašeho datového prostředí. Azure Security Center poskytuje komplexní přehled o stavu zabezpečení všech hybridních cloudových prostředků.
Důležité informace o výkonu
Většina stávajících místních funkcí výkonu SQL Serveru je dostupná také na virtuálních počítačích Azure. Mezi nabízené možnosti patří komprese dat, která může zlepšit výkon úloh náročných na vstupně-výstupní operace a zároveň snížit velikost databáze. Podobně dělení tabulek a indexů může zlepšit výkon dotazů velkých tabulek a zároveň zlepšit výkon a škálovatelnost.
Dělení tabulky
Dělení tabulek přináší mnoho výhod, ale tato strategie se často považuje pouze v případě, že se tabulka stane dostatečně velká, aby se začaly ohrozit výkon dotazů. Identifikace tabulek, které jsou kandidáty na dělení tabulek, je dobrým postupem, který by mohl vést k menšímu přerušení a zásahům. Při filtrování dat pomocí sloupce oddílu se přistupuje pouze k podmnožině dat, nikoli k celé tabulce. Podobně operace údržby v dělené tabulce snižují dobu údržby, například komprimací konkrétních dat v určitém oddílu nebo opětovným sestavením konkrétních oddílů indexu.
Při definování oddílu tabulky se vyžadují čtyři hlavní kroky:
- Vytvoří se skupiny souborů, které definují soubory, které jsou součástí vytváření oddílů.
- Vytvoření funkce oddílu, která definuje pravidla oddílů na základě zadaného sloupce.
- Vytvoření schématu oddílů, které definuje skupinu souborů každého oddílu.
- Tabulka, která se má rozdělit.
Následující příklad ukazuje, jak vytvořit funkci oddílu pro 1. ledna 2021 až 1. prosince 2021 a distribuovat oddíly mezi různé skupiny souborů.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Komprese dat
SQL Server nabízí různé možnosti pro komprimaci dat. I když SQL Server stále ukládá komprimovaná data na 8 kB stránkách, při komprimaci dat může být na dané stránce uloženo více řádků dat, což umožňuje dotazu číst méně stránek. Čtení menšího počtu stránek má dvojí výhodu: snižuje množství fyzických vstupně-výstupních operací a umožňuje ukládání více řádků do fondu vyrovnávací paměti, což umožňuje efektivnější využití paměti. Pokud je to vhodné, doporučujeme povolit kompresi databázových stránek.
Nevýhodou komprese je, že vyžaduje malou režii procesoru, ale ve většině případů vstupně-výstupní operace úložiště výrazně převáží nad jakýmkoli dalším využitím procesoru.
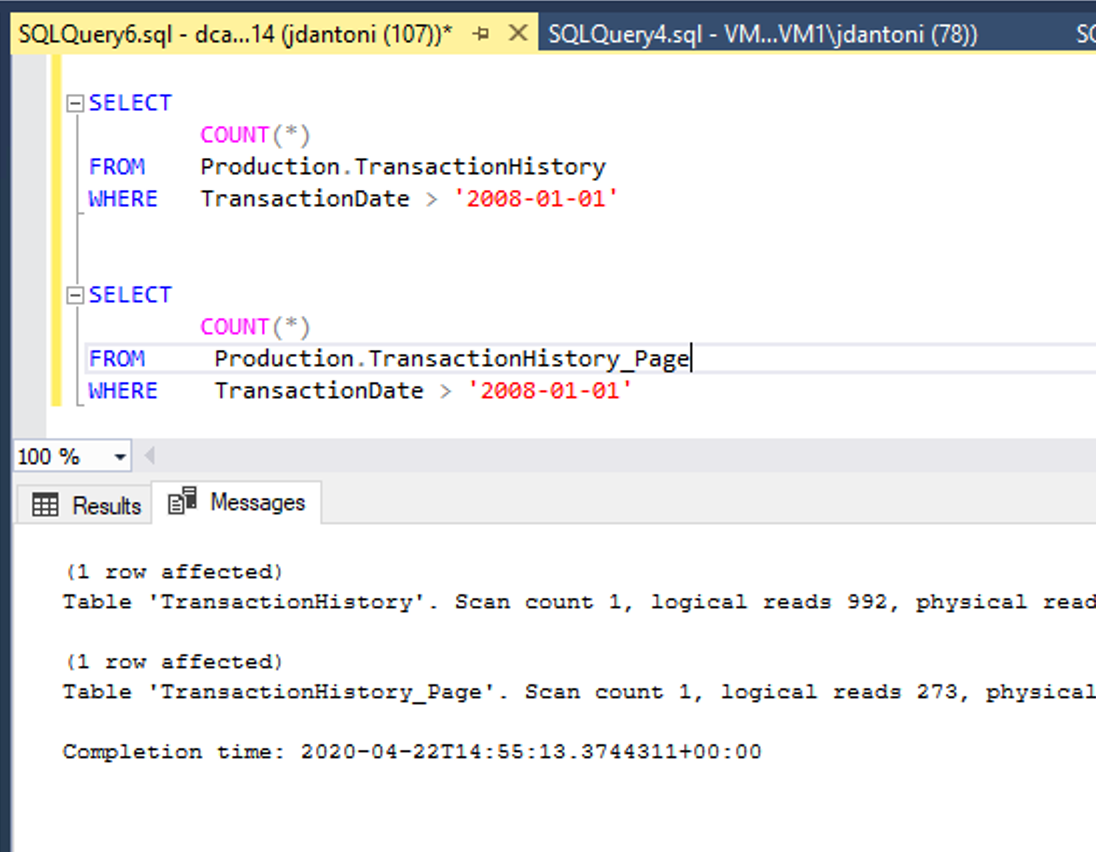
Výše uvedený obrázek ukazuje tuto výhodu výkonu. Tyto tabulky mají stejné základní indexy; Jediným rozdílem je, že clusterované a neclusterované indexy v tabulce Production.TransactionHistory_Pagejsou komprimované. Dotaz na komprimovaný objekt stránky provádí 72% méně logických čtení než dotaz, který používá nekomprimované objekty.
Komprese se implementuje v SQL Serveru na úrovni objektu. Každý index nebo tabulka je možné komprimovat jednotlivě a máte možnost komprimovat oddíly v rámci dělené tabulky nebo indexu. Pomocí uložené procedury sp_estimate_data_compression_savings systému můžete vyhodnotit, kolik místa ušetříte. Před SQL Serverem 2019 tento postup nepodporuje indexy columnstore ani archivní kompresi columnstore.
Komprese řádků – Komprese řádků je poměrně základní a nemá velkou režii, ale nenabízí stejné množství komprese (měřené procentuálním snížením úložného prostoru), které může komprese stránky nabídnout. Komprese řádků v podstatě ukládá každou hodnotu v každém sloupci na řádku v minimálním prostoru potřebném k uložení této hodnoty. Používá formát úložiště s proměnnou délkou pro číselné datové typy, jako je celé číslo, plovoucí desetinné číslo a desetinné číslo, a ukládá řetězce znaků s pevnou délkou pomocí formátu proměnné délky.
Komprese stránky – Komprese stránky je nadmnožinou komprese řádků, protože všechny stránky budou zpočátku komprimovány řádky před použitím komprese stránky. Potom se na data použije kombinace technik označovaných jako předpona a komprese slovníku. Komprese předpony eliminuje redundantní data v jednom sloupci a ukládá ukazatele zpět do záhlaví stránky. Po dokončení tohoto kroku komprese slovníku vyhledá opakované hodnoty na stránce a nahradí je ukazateli a dále snižuje úložiště. Čím větší redundance v datech, tím větší je úspora místa při komprimaci dat.
Archivní komprese columnstore – objekty Columnstore jsou vždy komprimované, lze je však dále komprimovat pomocí archivační komprese, která používá algoritmus komprese Microsoft XPRESS na data. Tento typ komprese se nejlépe používá pro data, která se často čtou, ale musí být zachována z regulačních nebo obchodních důvodů. I když jsou tato data dále komprimována, náklady na procesor dekomprese mají tendenci převažovat nad všemi nárůsty výkonu při snížení vstupně-výstupních operací.
Další možnosti
Níže je seznam dalších funkcí a akcí SQL Serveru, které je potřeba zvážit pro produkční úlohy:
- Povolení komprese záloh
- Povolení okamžité inicializace souborů pro datové soubory
- Omezení automatického zvětšování databáze
- Zakázání automatického zašikování nebo automatického zarážky pro databáze
- Přesun všech databází na datové disky, včetně systémových databází
- Přesunutí protokolu chyb SQL Serveru a adresářů trasovacích souborů na datové disky
- Nastavení maximálního limitu paměti SQL Serveru
- Povolení zámku stránek v paměti
- Povolení optimalizace pro adhocové úlohy pro velká prostředí OLTP
- Povolte úložiště dotazů.
- Naplánování úloh agenta SQL Serveru pro spouštění úloh DBCC CHECKDB, změna uspořádání indexu, opětovné sestavení indexu a aktualizace úloh statistiky
- Monitorování a správa stavu a velikosti souborů transakčních protokolů
Další informace o osvědčenýchpostupechch