Vysvětlení konceptů hlubokého učení
Ve vašem mozku máte nervové buňky označované jako neurony, které jsou vzájemně propojeny pomocí nervových rozšíření, které procházejí elektrochemickými signály přes síť.

Při stimulaci prvního neuronu v síti se zpracuje vstupní signál, a pokud překročí určitou prahovou hodnotu, neuron se aktivuje a předá signál neuronům, ke kterým je připojen. Tyto neurony mohou být aktivovány a předávat signál přes zbytek sítě. V průběhu času jsou spojení mezi neurony posílena častým použitím, když se naučíte efektivně reagovat. Pokud například zobrazíte obrázek tučňáka, vaše neuronová spojení vám umožní zpracovat informace na obrázku a vaše znalosti charakteristik tučňáka, aby ho identifikoval jako takový. Pokud se vám v průběhu času zobrazuje více obrázků různých zvířat, síť neuronů zapojených do identifikace zvířat na základě jejich charakteristiky roste silnější. Jinými slovy, získáte lepší identifikaci různých zvířat.
Hluboké učení emuluje tento biologický proces pomocí umělých neurálních sítí, které zpracovávají číselné vstupy místo elektrochemických podnětů.
Příchozí nervová spojení jsou nahrazena číselnými vstupy, které jsou obvykle identifikovány jako x. Pokud existuje více než jedna vstupní hodnota, x se považuje za vektor s prvky s názvem x1, x2 atd.
Přidružená ke každé hodnotě x je váha (w), která se používá k posílení nebo oslabit účinek hodnoty x pro simulaci učení. Navíc se přidá vstup zkreslení (b), který umožňuje jemně odstupňovanou kontrolu sítě. Během trénování se hodnoty w a b upraví tak, aby vyladily síť tak, aby se "učí" a vytvářely správné výstupy.
Neuron sám zapouzdřuje funkci, která vypočítá vážený součet x, w a b. Tato funkce je zase uzavřená do aktivační funkce , která omezuje výsledek (často na hodnotu mezi 0 a 1), aby bylo možné určit, zda neuron předává výstup do další vrstvy neuronů v síti.
Trénování modelu hlubokého učení
Modely hlubokého učení jsou neurální sítě, které se skládají z několika vrstev umělých neuronů. Každá vrstva představuje sadu funkcí, které se provádějí na hodnotách x s přidruženými váhami a bázami, a konečné výsledky vrstvy na výstupu popisku y, který model predikuje. V případě klasifikačního modelu (který předpovídá nejpravděpodobnější kategorii nebo třídu vstupních dat) je výstup vektor obsahující pravděpodobnost pro každou možnou třídu.
Následující diagram představuje model hloubkového učení, který predikuje třídu datové entity na základě čtyř funkcí (hodnot x). Výstupem modelu ( hodnot y ) je pravděpodobnost pro každý ze tří možných popisků tříd.
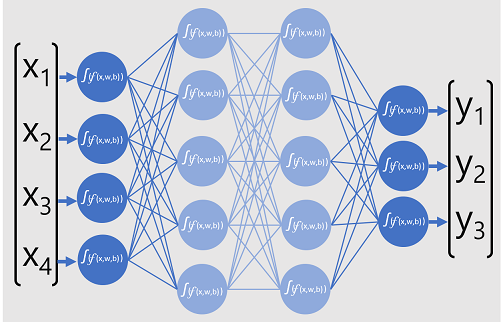
Pro trénování modelu architektura hlubokého učení podává několik dávek vstupních dat (pro které jsou známy skutečné hodnoty popisků), použije funkce ve všech síťových vrstvách a měří rozdíl mezi pravděpodobnostmi výstupu a skutečnými známými popisky tříd trénovacích dat. Agregovaný rozdíl mezi výstupy předpovědi a skutečnými popisky se označuje jako ztráta.
Když jsme vypočítali agregační ztrátu pro všechny dávky dat, architektura hlubokého učení pomocí optimalizátoru určuje, jak se mají váhy a předsudky v modelu upravit, aby se snížila celková ztráta. Tyto úpravy se pak znovu převedou na vrstvy v modelu neurální sítě a pak se data znovu předávají přes síť a přepočítávají se ztráty. Tento proces se několikrát opakuje (každá iterace se označuje jako epocha), dokud nedojde k minimalizaci ztráty a model se "naučil" správné váhy a předsudky, aby bylo možné přesně předpovědět.
Během každé epochy se váhy a předsudky upraví tak, aby se minimalizovala ztráta. Množství, podle kterého jsou upraveny , se řídí mírou učení, kterou zadáte optimalizátoru. Pokud je rychlost učení příliš nízká, proces trénování může trvat dlouhou dobu, než určí optimální hodnoty; pokud je ale příliš vysoká, optimalizátor nemusí nikdy najít optimální hodnoty.