Otevření poznámkového bloku Jupyter v clusteru HDInsight Spark
Po vytvoření clusteru HDInsight Spark můžete v Azure HDInsight spouštět interaktivní dotazy nebo úlohy Spark SQL na cluster Apache Sparku. Abyste to mohli udělat, musíte nejprve vytvořit poznámkový blok. Poznámkový blok je interaktivní editor, který umožňuje Datoví technici a Datoví vědci používat k interakci s daty celou řadu jazyků. Může to zahrnovat Python, SQL, Scala a další jazyky. HDInsight podporuje Pro interakci s daty Jupyter, Zeppelin a Livy. Úroveň interakce závisí na úloze, kterou spravujete.
Apache Spark ve službě HDInsight podporuje následující úlohy:
Interaktivní analýzu dat a BI
Poznámkový blok můžete použít k ingestování nestrukturovaných a částečně strukturovaných dat a pak v poznámkovém bloku definovat schéma. Pak můžete pomocí schématu vytvořit model v nástrojích, jako je Power BI, které podnikovým uživatelům umožní provádět analýzu dat na datech v poznámkovém bloku.
Spark Machine Learning
Poznámkový blok můžete použít k práci s knihovnou MLlib (knihovna strojového učení založená na Sparku) k vytváření aplikací strojového učení.
Vysílání datových proudů a analýza dat v reálném čase ve Sparku
Clustery Spark v HDInsight nabízí bohatou podporu pro vytváření řešení pro analýzu v reálném čase. Spark už má konektory pro příjem dat z mnoha zdrojů, jako je Kafka, Flume, X, ZeroMQ nebo TCP sockets, Spark v HDInsight přidává prvotřídní podporu příjmu dat ze služby Azure Event Hubs.
Vytvoření poznámkového bloku Jupyter
Pomocí následujícího postupu vytvořte poznámkový blok Jupyter na webu Azure Portal.
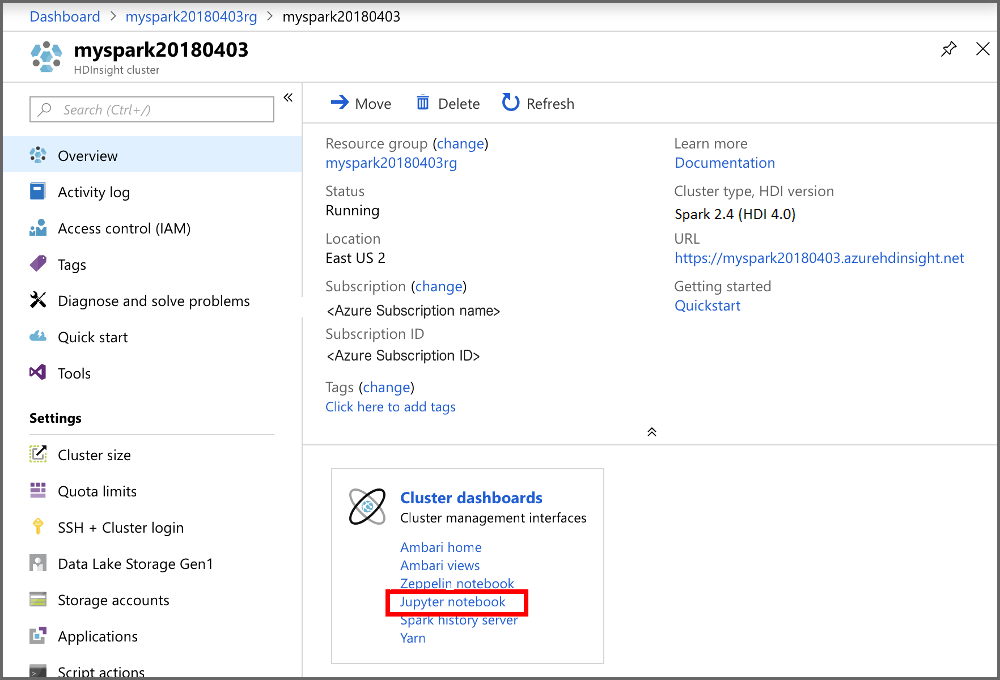
Na portálu v části Řídicí panely clusteru vyberte Poznámkový blok Jupyter. Pokud se zobrazí výzva, zadejte přihlašovací údaje clusteru pro cluster.
Vyberte Nový > PySpark a vytvořte poznámkový blok.
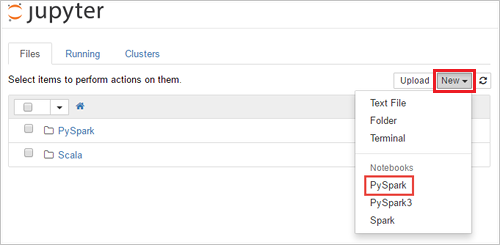
Vytvoří se nový poznámkový blok a otevře se s názvem Bez názvu (Bez názvu.pynb), který umožňuje začít vytvářet úlohy, které spouštějí dotazy.