Principy konceptů databáze Lake
V tradiční relační databázi se schéma databáze skládá z tabulek, zobrazení a dalších objektů. Tabulky v relační databázi definují entity, pro které jsou uložená data – například maloobchodní databáze může obsahovat tabulky pro produkty, zákazníky a objednávky. Každá entita se skládá ze sady atributů definovaných jako sloupce v tabulce a každý sloupec má název a datový typ. Data pro tabulky jsou uložena v databázi a jsou úzce svázána s definicí tabulky; který vynucuje datové typy, hodnotu null, jedinečnost klíče a referenční integritu mezi souvisejícími klíči. Všechny dotazy a manipulace s daty se musí provádět prostřednictvím databázového systému.
V datovém jezeře neexistuje žádné pevné schéma. Data jsou uložená v souborech, které můžou být strukturované, částečně strukturované nebo nestrukturované. Aplikace a datoví analytici mohou pracovat přímo se soubory v datovém jezeře pomocí nástrojů podle svého výběru; bez omezení relačního databázového systému.
Databáze lake poskytuje vrstvu relačních metadat přes jeden nebo více souborů v datovém jezeře. Můžete vytvořit databázi lake, která obsahuje definice pro tabulky, včetně názvů sloupců a datových typů a relací mezi sloupci primárního a cizího klíče. Tabulky odkazují na soubory v datovém jezeře, které umožňují použít relační sémantiku pro práci s daty a dotazování na ně pomocí SQL. Úložiště datových souborů je však oddělené od schématu databáze; povolení větší flexibility než systém relačních databází obvykle nabízí.
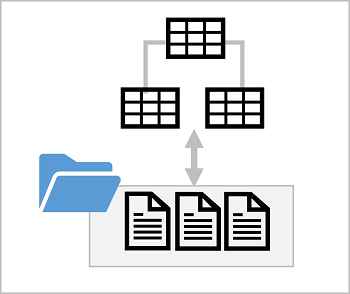
Schéma databáze Lake
V Azure Synapse Analytics můžete vytvořit databázi lake a definovat tabulky, které představují entity, pro které potřebujete ukládat data. Osvědčené principy modelování dat můžete použít k vytváření relací mezi tabulkami a použití vhodných konvencí vytváření názvů pro tabulky, sloupce a další databázové objekty.
Azure Synapse Analytics obsahuje grafické rozhraní pro návrh databáze, které můžete použít k modelování komplexního schématu databáze pomocí mnoha stejných osvědčených postupů pro návrh databáze, které byste použili u tradiční databáze.
Úložiště databáze Lake
Data pro tabulky v databázi lake jsou uložená v datovém jezeře jako soubory Parquet nebo CSV. Soubory je možné spravovat nezávisle na databázových tabulkách, což usnadňuje správu příjmu a manipulace s daty pomocí široké škály nástrojů a technologií pro zpracování dat.
Výpočetní prostředky databáze Lake
K dotazování a manipulaci s daty prostřednictvím definovaných tabulek můžete použít bezserverový fond SQL Azure Synapse ke spouštění dotazů SQL nebo fondu Azure Synapse Apache Spark pro práci s tabulkami pomocí rozhraní Spark SQL API.