Vlastní dovednost klasifikace textu
Vlastní klasifikace textu umožňuje namapovat úsek textu na různé uživatelem definované třídy. Můžete například vytrénovat model na synopzi na zadním krytu knih, abyste automaticky identifikovali žánr knih. Pak použijete tento identifikovaný žánr k obohacení vyhledávacího webu online obchodu o žánrovou omezující vlastnost.
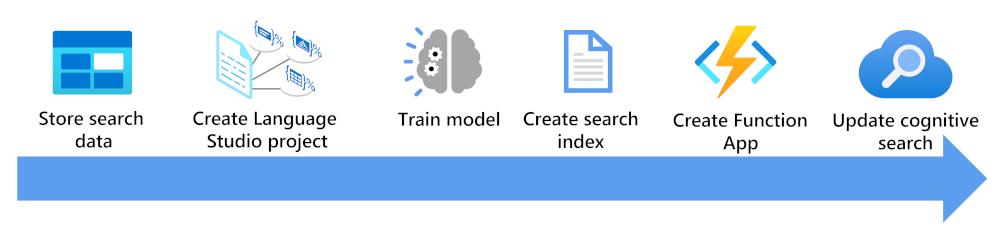
Tady uvidíte, co je potřeba zvážit, abyste mohli rozšířit index vyhledávání pomocí vlastního modelu klasifikace textu:
- Ukládejte dokumenty tak, aby k nim měli přístup jazykové studio a indexery Azure AI Search.
- Vytvořte vlastní projekt klasifikace textu.
- Trénování a testování modelu
- Vytvořte vyhledávací index založený na uložených dokumentech.
- Vytvořte aplikaci funkcí, která používá nasazený natrénovaný model.
- Aktualizujte řešení vyhledávání, index, indexer a vlastní sadu dovedností.
Ukládání dat
Ke službě Azure Blob Storage je možné přistupovat ze sady Language Studio i ze služeb Azure AI. Kontejner musí být přístupný, takže nejjednodušší možností je zvolit Kontejner, ale je také možné použít privátní kontejnery s určitou další konfigurací.
Spolu s daty potřebujete také způsob, jak přiřadit klasifikace pro každý dokument. Language Studio poskytuje grafický nástroj, pomocí kterého můžete každý dokument klasifikovat ručně.
Můžete si vybrat mezi dvěma různými typy projektů. Pokud se dokument mapuje na jednu třídu, použijte jeden projekt klasifikace popisků. Pokud chcete dokument namapovat na více než jednu třídu, použijte projekt klasifikace více popisků.
Pokud nechcete každý dokument klasifikovat ručně, můžete před vytvořením projektu Azure AI Language označovat všechny dokumenty. Tento proces zahrnuje vytvoření dokumentu JSON popisků v tomto formátu:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Do pole přidáte tolik tříd, kolik potřebujete classes . Přidáte položku pro každý dokument v documents poli, včetně tříd, které dokument odpovídá.
Vytvoření projektu Azure AI Language
Projekt Azure AI Language můžete vytvořit dvěma způsoby. Pokud začnete používat Language Studio bez prvního vytvoření služby jazyka na webu Azure Portal, language Studio vám nabídne, abyste si ji vytvořili za vás.
Nejflexibilnější způsob, jak vytvořit projekt jazyka Azure AI, je nejprve vytvořit službu jazyka pomocí webu Azure Portal. Pokud zvolíte tuto možnost, získáte možnost přidat vlastní funkce.
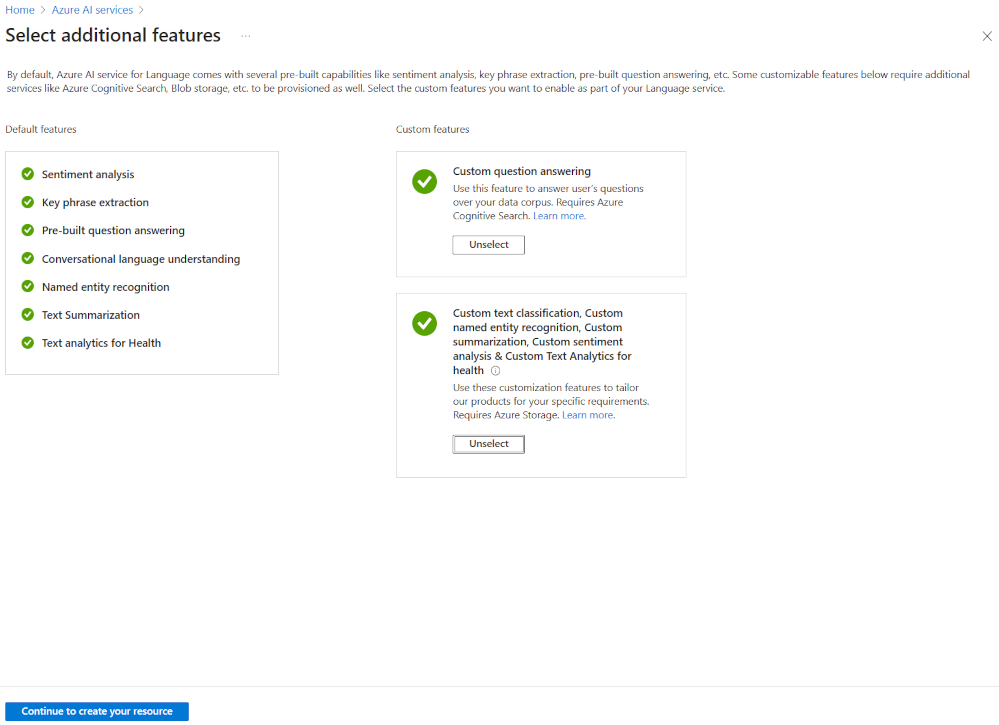
Při vytváření vlastní klasifikace textu vyberte tuto vlastní funkci při vytváření služby jazyka. Pomocí této metody také propojete službu jazyka s účtem úložiště.
Po nasazení prostředku můžete přejít přímo do sady Language Studio z podokna přehledu služby jazyka. Pak můžete vytvořit nový vlastní projekt klasifikace textu.
Poznámka:
Pokud jste vytvořili svoji jazykovou službu ze sady Language Studio, možná budete muset postupovat podle těchto kroků. Nastavte role pro prostředek Azure Language a účet úložiště pro připojení kontejneru úložiště k vašemu vlastnímu projektu klasifikace textu.
Trénování klasifikačního modelu
Stejně jako u všech modelů AI potřebujete identifikovat data, která můžete použít k trénování. Model potřebuje vidět příklady mapování dat na třídu a několik příkladů, které může použít k otestování modelu. Můžete se rozhodnout, že model automaticky rozdělí trénovací data. Ve výchozím nastavení použije 80 % dokumentů k trénování modelu a 20 % pro testování. Pokud máte nějaké konkrétní dokumenty, se kterými chcete model otestovat, můžete dokumenty označovat pro testování.

V sadě Language Studio vyberte v projektu popisky dat. Uvidíte všechny svoje dokumenty. Vyberte každý dokument, který chcete přidat do testovací sady, a pak vyberte Testování výkonu modelu. Uložte aktualizované popisky a vytvořte novou trénovací úlohu.
Vytvoření indexu vyhledávání
Neexistuje nic specifického, co byste museli udělat, abyste vytvořili vyhledávací index, který bude rozšířen vlastním modelem klasifikace textu. Postupujte podle kroků v tématu Vytvoření řešení Azure AI Search. Po vytvoření aplikace funkcí budete aktualizovat index, indexer a vlastní dovednosti.
Vytvoření aplikace funkcí Azure
Pro svou aplikaci funkcí můžete zvolit jazyk a technologie, které chcete použít. Aplikace musí být schopná předat JSON do koncového bodu vlastní klasifikace textu, například:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Pak z modelu zpracujte odpověď JSON, například:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
Funkce pak vrátí strukturovanou zprávu JSON zpět do vlastní sady dovedností ve službě AI Search, například:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Aplikace funkcí potřebuje vědět pět věcí:
- Text, který se má klasifikovat.
- Koncový bod nasazeného modelu vlastní klasifikace textu
- Primární klíč pro projekt vlastní klasifikace textu.
- Název projektu.
- Název nasazení.
Text, který se má klasifikovat, se předává z vlastní sady dovedností ve službě AI Search do funkce jako vstup. Zbývající čtyři položky najdete v sadě Language Studio.

Koncový bod a název nasazení se nachází v podokně nasazení modelu.

Název projektu a primární klíč jsou v podokně nastavení projektu.
Aktualizace řešení Azure AI Search
Na webu Azure Portal jsou tři změny, které je potřeba udělat, abyste mohli rozšířit index vyhledávání:
- Abyste mohli do indexu uložit rozšiřování vlastní klasifikace textu, musíte do indexu přidat pole.
- K volání aplikace funkcí s textem ke klasifikaci musíte přidat vlastní sadu dovedností.
- Potřebujete namapovat odpověď ze sady dovedností do indexu.
Přidání pole do existujícího indexu
Na webu Azure Portal přejděte k prostředku AI Search, vyberte index a v tomto formátu přidáte JSON:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Tento JSON přidá do indexu složené pole pro uložení třídy do category pole, které je prohledávatelné. confidenceScore Druhé pole ukládá procento spolehlivosti do dvojitého pole.
Úprava vlastní sady dovedností
Na webu Azure Portal vyberte sadu dovedností a přidejte JSON v tomto formátu:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Tato WebApiSill definice dovednosti určuje, že jazyk a obsah dokumentu se předávají jako vstupy do aplikace funkcí. Aplikace vrátí text JSON s názvem class.
Mapování výstupu z aplikace funkcí na index
Poslední změnou je mapování výstupu na index. Na webu Azure Portal vyberte indexer a upravte JSON, aby měl nové mapování výstupu:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
Indexer teď ví, že výstup z aplikace document/class funkcí by se měl uložit do classifiedtext pole. Vzhledem k tomu, že je definováno jako složené pole, aplikace funkcí musí vrátit pole JSON obsahující category pole a confidenceScore pole.
Teď můžete prohledat vlastní klasifikovaný text v rozšířeném indexu vyhledávání.