Cvičení – vytvoření a trénování neurální sítě
V této lekci použijete Keras k vytvoření a trénování neuronové sítě, která analyzuje mínění v textu. K trénování neuronové sítě potřebujete data, se kterými se bude trénovat. Místo stažení externí datové sady použijete datovou sadu klasifikace mínění v recenzích filmů na IMDb, která je součástí Kerasu. Datová sada IMDb obsahuje 50 000 recenzí filmů, které byly jednotlivě opatřeny skórem jako pozitivní (1) nebo negativní (0). Datová sada je rozdělená na 25 000 recenzí pro trénování a 25 000 recenzí pro testování. Mínění vyjádřené v těchto recenzích je základem, pro který bude vaše neuronová síť analyzovat předložený text a udělovat mu skóre z hlediska mínění.
Datová sada IMDb je jednou z několika užitečných datových sad, které jsou součástí Kerasu. Úplný seznam předdefinovaných datových sad najdete na https://keras.io/datasets/.
Zadejte nebo vložte následující kód do první buňky v poznámkovém bloku a kliknutím na tlačítko Run (Spustit) nebo stisknutím kláves Shift+Enter ho spusťte a přidejte pod něj novou buňku:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Tento kód načte datovou sadu IMDb, která je součástí Kerasu, a vytvoří slovník mapující slova ve všech 50 000 recenzích na celá čísla, která udávají relativní četnost výskytu slov. Každému slovu se přiřadí jedinečné celé číslo. Nejčastějšímu slovu se přiřadí číslo 1, druhému nejčastějšímu slovu se přiřadí číslo 2 a tak dále.
load_datataké vrátí pár řazené kolekce členů obsahující recenze filmů (v tomto příkladux_trainax_test) a čísla 1 a 0, která tyto recenze klasifikují jako pozitivní a negativní (y_trainay_test).Zkontrolujte, jestli vidíte zprávu „Using TensorFlow back-end“, která udává, že Keras používá TensorFlow jako back-end.
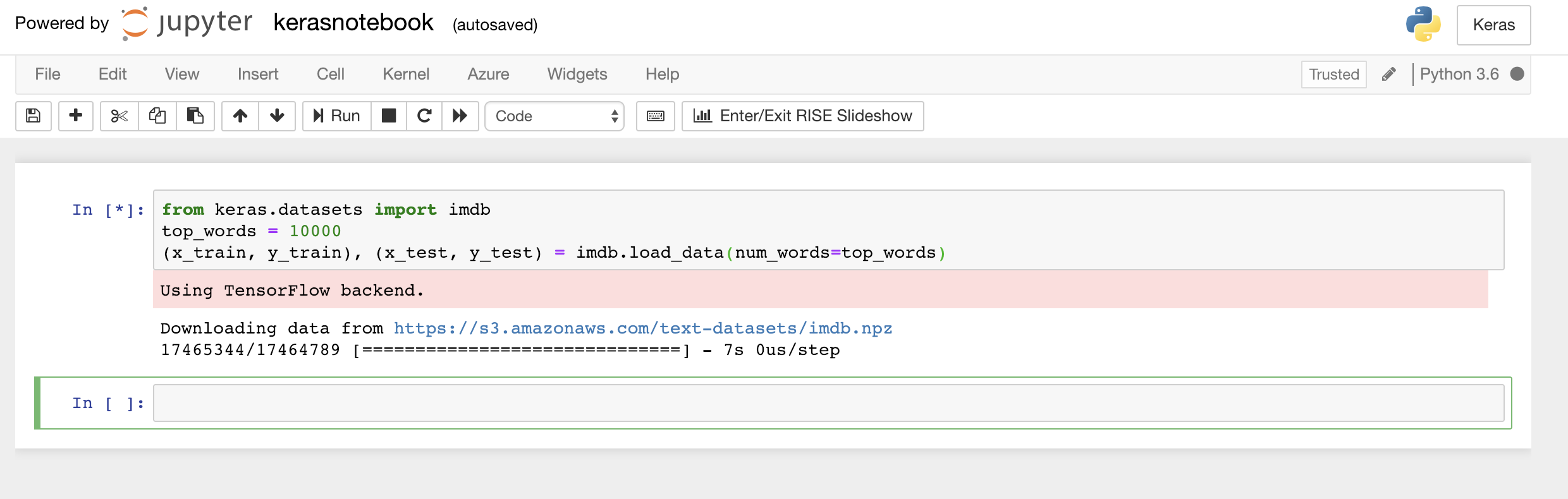
Načtení datové sady IMDb
Pokud byste chtěli, aby Keras jako back-end použil Microsoft Cognitive Toolkit, označovaný také jako CNTK, mohli byste to udělat přidáním několika řádků kódu na začátek poznámkového bloku. Příklad najdete v tématu CNTK a Keras v poznámkových blocích Azure.
Co přesně tedy funkce
load_datanačetla? Proměnná s názvemx_trainje seznam 25 000 seznamů, z nichž každý představuje jednu filmovou recenzi. (x_testje také seznam 25 000 seznamů představujících 25 000 recenzí.x_trainpoužije se pro trénování, zatímcox_testse použije k testování.) Vnitřní seznamy – ty, které představují recenze filmů – ale neobsahují slova; obsahují celá čísla. Takhle je to popsané v dokumentaci Kerasu:
Důvodem, proč vnitřní seznamy obsahují čísla místo textu, je to, že neuronovou síť netrénujete pomocí textu, ale pomocí čísel. Konkrétně ji trénujete pomocí tenzorů. V tomto případě je každá recenze jednorozměrný tenzor (představte si jednorozměrné pole) obsahující celá čísla, která identifikují slova obsažená v recenzi. Abychom si to předvedli, zadejte následující příkaz Pythonu do prázdné buňky a spusťte ho, abyste viděli celá čísla reprezentující první recenzi v trénovací sadě:
x_train[0]
Celá čísla tvořící první recenzi v trénovací sadě IMDb
První číslo v seznamu – 1 – vůbec nepředstavuje slovo. Označuje začátek recenze a je stejné pro každou recenzi v datové sadě. Čísla 0 až 2 jsou také rezervovaná. Od ostatních čísel odečtete číslo 3, abyste namapovali celé číslo v recenzi na odpovídající číslo ve slovníku. Druhé číslo,14, tak odkazuje na slovo, které odpovídá číslu 11 ve slovníku, třetí číslo představuje slovo, které má ve slovníku přiřazené číslo 19, a tak dále.
Zajímá vás, jak slovník vypadá? Spusťte tento příkaz v nové buňce poznámkového bloku:
imdb.get_word_index()Zobrazí se jenom podmnožina položek slovníku, ale celkem slovník obsahuje více než 88 000 slov a celých čísel, která jim odpovídají. Výstup, který uvidíte, se pravděpodobně nebude shodovat s výstupem na snímku obrazovky, protože slovník se znovu generuje při každém volání funkce
load_data.
Slovník mapující slova na celá čísla
Jak jste viděli, každá recenze v datové sadě je kódovaná jako kolekce celých čísel místo slov. Je možné zpětným kódováním recenze zobrazit původní text, který ji tvořil? Zadejte do nové buňky následující příkazy a jejich spuštěním zobrazte první recenzi v
x_trainv textovém formátu:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))Ve výstupu označuje ">" začátek recenze, zatímco "?" označuje slova, která nejsou mezi nejběžnějšími 10 000 slovy v datové sadě. Tato „neznámá“ slova jsou v seznamu celých čísel představujících recenzi reprezentována čísly 2. Pamatujete na parametr
num_words, který jste předali funkciload_data? Tady vstupuje do hry. Nezmenší velikost slovníku, ale omezí rozsah celých čísel používaný ke kódování recenzí.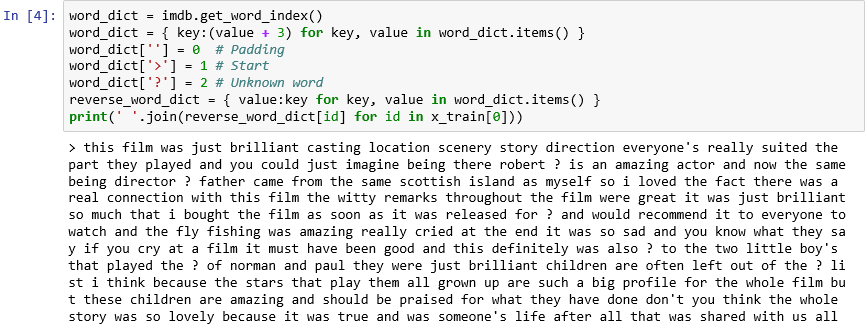
První recenze v textovém formátu
Recenze jsou „čisté“ v tom smyslu, že písmena se převedla na malá písmena a odebraly se znaky interpunkce. Nejsou ale připravené k trénování neuronové sítě pro analýzu mínění v textu. Při trénování neuronové sítě s pomocí kolekce tenzorů musí mít všechny tenzory stejnou délku. Teď mají seznamy představující recenze v
x_trainax_testrůzné délky.Keras naštěstí zahrnuje funkci, která vezme seznam seznamů jako vstup a vnitřní seznamy převede na zadanou délku tím, že je v případě potřeby zkrátí nebo je prodlouží pomocí čísel 0. Zadejte do poznámkového bloku následující kód a jeho spuštěním vynuťte, aby všechny seznamy představující recenze filmů v
x_trainax_testměly délku 500 celých čísel:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Když teď máte trénovací a testovací data připravená, je čas vytvořit model. Spuštěním následujícího kódu v poznámkovém bloku vytvořte neuronovou síť, která provede analýzu mínění:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Zkontrolujte, jestli výstup vypadá takto:
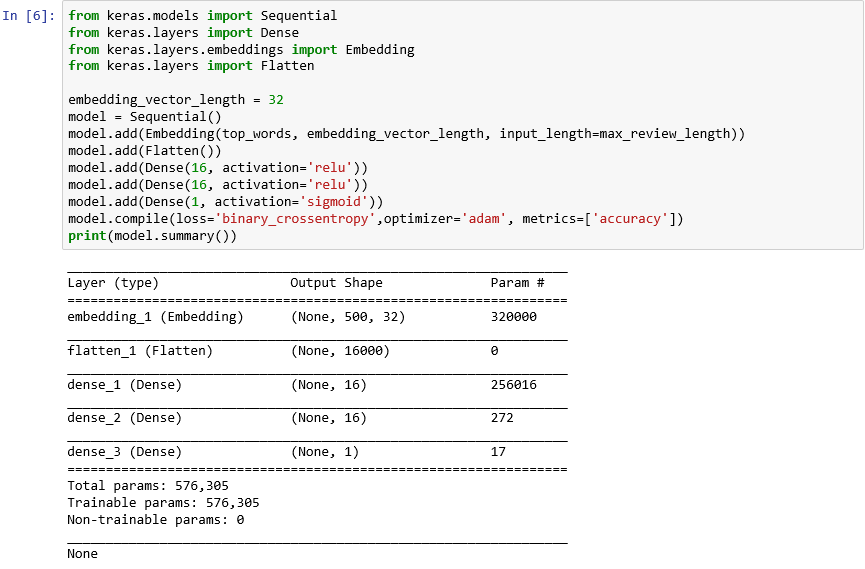
Vytvoření neuronové sítě pomocí Kerasu
Tento kód je základem toho, jak vytvoříte neuronovou síť pomocí Kerasu. Nejdřív vytvoří instanci objektu
Sequentialpředstavujícího „sekvenční“ model – ten se skládá ze sady vrstev, v níž výstup z jedné vrstvy poskytuje vstup do další.Následujících několik příkazů do modelu přidá vrstvy. První je vrstva vkládání, která je zásadní pro neuronové sítě, které zpracovávají slova. Vrstva vkládání v podstatě mapuje mnohorozměrná pole obsahující indexy celých čísel a slov na pole čísel s plovoucí desetinnou čárkou obsahující méně dimenzí. Umožňuje také, aby se se slovy s podobným významem zacházelo stejně. Úplné zpracování vkládání slov je nad rámec tohoto cvičení, ale další informace najdete v článku o tom, proč je potřeba začít používat vrstvy vkládání. Pokud dáváte přednost odbornějšímu vysvětlení, přečtěte si článek o účinném odhadování reprezentací slov ve vektorovém prostoru. Volání Flatten po přidání vrstvy vkládání přetvoří výstup pro vstup do další vrstvy.
Další tři vrstvy přidané do modelu jsou husté vrstvy, označované také jako plně propojené vrstvy. Jedná se o tradiční vrstvy, které jsou v neuronových sítích běžné. Každá vrstva obsahuje n uzlů nebo neuronů a každý neuron přijímá vstupy z každého neuronu v předchozí vrstvě, a proto termín "plně propojený". Jedná se o tyto vrstvy, které umožňují neuronové síti "učit se" ze vstupních dat iterativním odhadem výstupu, kontrolou výsledků a vyladěním připojení, aby se zlepšily výsledky. První dvě husté vrstvy v této síti obsahují každá 16 neuronů. Toto číslo je zvolené náhodně. Je možné, že přesnost modelu zlepšíte experimentováním s různými velikostmi. Poslední hustá vrstva obsahuje jenom jeden neuron, protože konečným cílem sítě je předvídat jeden výstup – konkrétně skóre mínění od 0,0 do 1,0.
Výsledkem je neuronové síť vyobrazená níže. Síť obsahuje vstupní vrstvu, výstupní vrstvu a dvě skryté vrstvy (husté vrstvy obsahující 16 neuronů). Pro porovnání uveďme, že některé dnešní sofistikovanější neuronové sítě mají více než 100 vrstev. Jedním z příkladů je síť ResNet-152 od Microsoft Research, jejíž přesnost při identifikaci objektů na fotografiích někdy překračuje přesnost lidskou. ResNet-152 byste mohli vytvořit pomocí Kerasu, ale potřebovali byste cluster počítačů vybavených GPU k jejímu trénování úplně od začátku.
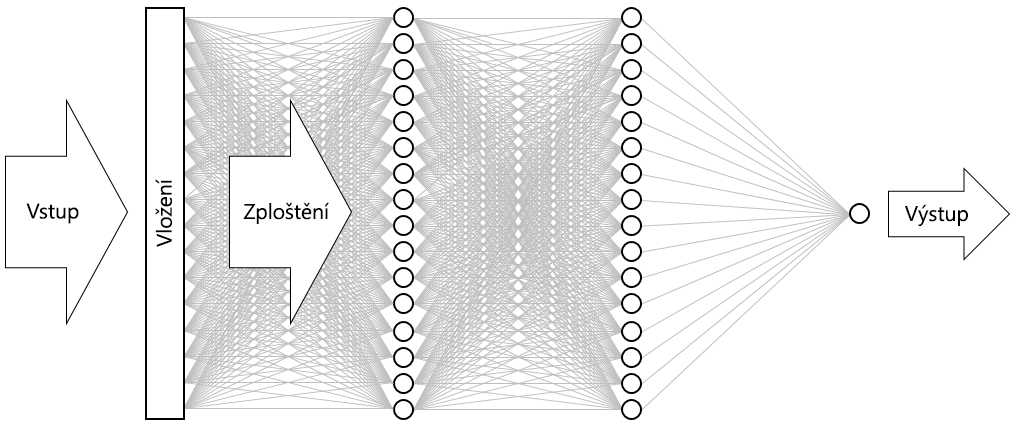
Vizualizace neuronové sítě
Volání funkce compile „zkompiluje“ model zadáním důležitých parametrů, třeba kterou optimalizaci použít a jakou metriku použít k posuzování přesnosti modelu v každém kroku trénování. Trénování nezačne, dokud nezavoláte funkci
fitmodelu, takže se volánícompileobvykle provede rychle.Teď volejte funkci fit k trénování neuronové sítě:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)Trénování by mělo trvat asi 6 minut neboli o trochu déle než 1 minutu na epochu.
epochs=5říká Kerasu, aby provedl 5 průchodů modelem vpřed a zpět. S každým průchodem se model učí z trénovacích dat a pomocí testovacích dat měří („ověřuje“), jak dobře se naučil. Pak provede úpravy a vrátí se zpět k dalšímu průchodu neboli epoše. Odráží se to ve výstupu funkcefit, která zobrazuje přesnost trénování (acc) a přesnost ověřování (val_acc) pro každou epochu.batch_size=128říká Kerasu, aby k trénování k sítě použil najednou 128 trénovacích vzorků. Větší velikosti dávek zkracují dobu trénování (v každé epoše je potřeba menší počet průchodů ke spotřebování všech trénovacích dat), ale menší velikosti dávek někdy zvyšují přesnost. Po dokončení tohoto cvičení se můžete vrátit a přetrénovat model s velikostí dávky 32, abyste zjistili, jaký (nebo jestli vůbec) to má vliv na přesnost modelu. Doba trénování se tím zhruba zdvojnásobí.
Trénování modelu
Tento model je nezvyklý v tom, že se dobře vytrénuje pomocí jen pár epoch. Přesnost trénování se rychle zvětšuje na téměř 100 %, zatímco přesnost ověření se zvětšuje na epochu nebo dvě a pak se zploštělí. Obecně nechcete model trénovat déle, než je vyžadováno pro stabilizaci těchto přesností. Rizikem je přeurčení, které vede k tomu, že si model dobře vede s testovacími daty, ale ne tak dobře s reálnými daty. Jednou ze známek toho, že došlo k přeurčení modelu, je rostoucí nesrovnalost mezi přesností trénování a přesností ověřování. Skvělý úvod k přeurčení najdete v tématu Přeurčení ve službě Machine Learning: Co je a jak se tomu vyhnout.
Pokud chcete zobrazit změny v přesnosti trénování a přesnosti ověřování jako průběh trénování, spusťte v nové buňce poznámkového bloku tyto příkazy:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()Data o přesnosti pocházejí z objektu
historyvráceného funkcífitmodelu. Na základě grafu, který vidíte, doporučili byste zvýšení, snížení nebo ponechání stejného počtu epoch trénování?Dalším způsobem, jak zkontrolovat přeurčení, je porovnat ztrátu trénování se ztrátou ověřování v průběhu trénování. Problémy optimalizace jako tento se snaží minimalizovat funkci ztráty. Další informace najdete tady. Ztráta trénování mnohem větší než ztráta ověřování v dané epoše může být známkou přeurčení. V předchozím kroku jste pomocí vlastností
accaval_accvlastnostihistoryobjektuhistorygrafiky znázornili přesnost trénování a ověřování. Stejná vlastnost obsahuje také hodnoty nazvanélossaval_losspředstavující ztrátu trénování a ověřování. Pokud byste tyto hodnoty chtěli graficky znázornit v grafu, jako je ten níže, jak byste k tomu upravili výše uvedený kód?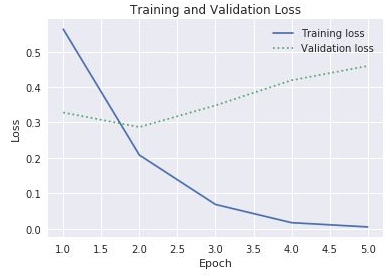
Ztráta trénování a ověřování
Vzhledem k tomu, že se mezera mezi ztrátou trénování a ověřování začíná v třetí epoše zvyšovat, co byste řekli, pokud by někdo navrhl, abyste zvýšili počet epoch na 10 nebo 20?
Dokončete postup voláním metody
evaluatemodelu, abyste zjistili, jak přesně dokáže model vyčíslit mínění vyjádřené v textu na základě testovacích dat vx_test(recenze) ay_test(čísla 0 a 1 nebo „popisky“ určující, které recenze jsou pozitivní a které negativní):scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))Jaká je vypočítaná přesnost modelu?
Pravděpodobně jste dosáhli přesnosti v rozsahu 85 až 90 %. To je přijatelné vzhledem k tomu, že jste model vytvořili úplně od začátku (na rozdíl od použití předem vytrénované neuronové sítě) a doba trénování byla krátká i bez GPU. Je možné dosáhnout přesností 95 % nebo vyšší s alternativními architekturami neuronové sítě, zejména s rekurentními neuronovými sítěmi (RNN), které využívají vrstvy dlouhé krátkodobé paměti (LSTM). Keras usnadňuje vytváření takových sítí, ale doba trénování se může exponenciálně zvýšit. Model, který jste vytvořili, dosahuje přiměřené rovnováhy mezi přesností a dobou trénování. Pokud se ale chcete o vytváření sítí RNN pomocí Kerasu dozvědět víc, přečtěte si článek Understanding LSTM and its Quick Implementation in Keras for Sentiment Analysis (Porozumění architektuře LSTM a její rychlá implementace v Kerasu pro analýzu mínění).