Strojové učení pro počítačové zpracování obrazu
Schopnost používat filtry k použití efektů na obrázky je užitečná při úlohách zpracování obrázků, jako je například použití softwaru pro úpravy obrázků. Cílem počítačového zpracování obrazu je však často extrahovat význam nebo alespoň užitečné přehledy z obrázků; které vyžaduje vytvoření modelů strojového učení, které jsou natrénované tak, aby rozpoznávaly funkce na základě velkých objemů existujících imagí.
Tip
V této lekci se předpokládá, že znáte základní principy strojového učení a že máte koncepční znalosti hlubokého učení s neurálními sítěmi. Pokud s strojovém učení začínáte, zvažte dokončení modulu Základy strojového učení v Microsoft Learn.
Konvoluční neurální sítě (CNN)
Jednou z nejběžnějších architektur modelů strojového učení pro počítačové zpracování obrazu je konvoluční neurální síť (CNN), která je typem architektury hlubokého učení. Sítě CNN používají filtry k extrakci map číselných funkcí z obrázků a následnému podávání hodnot funkcí do modelu hlubokého učení k vygenerování předpovědi popisků. Například ve scénáři klasifikace obrázků představuje popisek hlavní předmět obrázku (jinými slovy, co je to obrázek?). Model CNN můžete vytrénovat obrázky různých druhů ovoce (jako je jablko, banán a pomeranč), aby popisek, který je předpovězen, byl typem ovoce na daném obrázku.
Během trénování sítě CNN se jádra filtru zpočátku definují pomocí náhodně generovaných hodnot hmotnosti. Jakmile proces trénování postupuje, vyhodnocují se předpovědi modelů proti známým hodnotám popisků a váhy filtru se upraví, aby se zlepšila přesnost. Vytrénovaný model klasifikace obrázků ovoce nakonec používá váhy filtru, které nejlépe extrahují funkce, které pomáhají identifikovat různé druhy ovoce.
Následující diagram znázorňuje, jak funguje síť CNN pro model klasifikace obrázků:
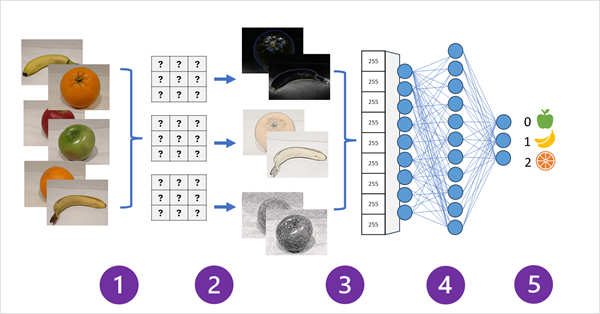
- Obrázky se známými štítky (například 0: jablko, 1: banán nebo 2: oranžová) se zasílají do sítě pro trénování modelu.
- Jedna nebo více vrstev filtrů se používá k extrakci funkcí z jednotlivých imagí, jak se předává přes síť. Jádra filtru začínají náhodně přiřazenými váhami a generují pole číselných hodnot označovaných jako mapy funkcí.
- Mapy funkcí jsou zploštěné do jednorozměrného pole hodnot prvků.
- Hodnoty funkcí se předávají do plně propojené neurální sítě.
- Výstupní vrstva neurální sítě používá softmax nebo podobnou funkci k vytvoření výsledku, který obsahuje hodnotu pravděpodobnosti pro každou možnou třídu, například [0,2, 0,5, 0,3].
Během trénování se pravděpodobnosti výstupu porovnávají se skutečným popiskem třídy – například obrázek banánu (třída 1) by měl mít hodnotu [0,0, 1,0, 0,0]. Rozdíl mezi predikovanými a skutečnými skóre třídy se používá k výpočtu ztráty v modelu a váhy v plně připojené neurální síti a jádry filtru ve vrstvách extrakce funkcí jsou upraveny tak, aby se snížila ztráta.
Proces trénování se opakuje v několika epochách , dokud se nenaučí optimální sada hmotností. Pak se váhy uloží a model se dá použít k předpovídání popisků pro nové obrázky, pro které je popisek neznámý.
Poznámka:
Architektury CNN obvykle obsahují několik konvolučních vrstev filtru a další vrstvy, které snižují velikost map funkcí, omezují extrahované hodnoty a jinak manipulují s hodnotami funkcí. Tyto vrstvy byly vynechány v tomto zjednodušeném příkladu, aby se zaměřily na klíčový koncept, což je to, že filtry slouží k extrakci číselných funkcí z obrázků, které se pak používají v neurální síti k předpovídání popisků obrázků.
Transformátory a multimodální modely
Sítě CNN jsou jádrem řešení pro počítačové zpracování obrazu už mnoho let. I když se běžně používají k řešení problémů s klasifikací obrázků, jak je popsáno výše, jsou také základem složitějších modelů počítačového zpracování obrazu. Modely detekce objektů například kombinují vrstvy extrakce funkcí CNN s identifikací oblastí, které jsou zajímavé na obrázcích, a vyhlašují více tříd objektů na stejném obrázku.
Transformátory
Většina pokroků v počítačovém zpracování obrazu v posledních desetiletích byla založena na vylepšeních modelů založených na CNN. V jiné disciplíně umělé inteligence – zpracování přirozeného jazyka (NLP), jiném typu architektury neurální sítě označované jako transformátor však umožnil vývoj sofistikovaných modelů pro jazyk. Transformátory fungují tak, že zpracovávají obrovské objemy dat a kódovací jazykové tokeny (představující jednotlivá slova nebo fráze) jako vektorové vkládání (pole číselných hodnot). Vložení si můžete představit jako reprezentaci sady dimenzí, které představují určitý sémantický atribut tokenu. Vložené objekty se vytvářejí tak, aby tokeny, které se běžně používají ve stejném kontextu, byly blíže dimenzionálním způsobem než nesouvisející slova.
Jako jednoduchý příklad ukazuje následující diagram některá slova kódovaná jako trojrozměrné vektory a vynesená do 3D prostoru:
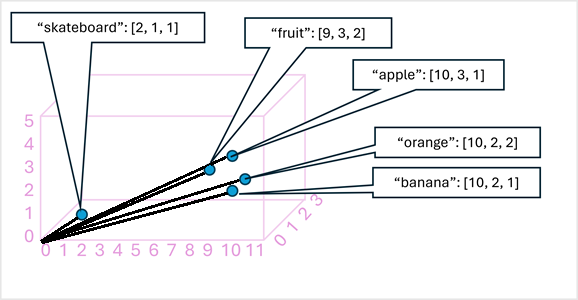
Tokeny, které jsou sémanticky podobné, jsou kódovány v podobných pozicích a vytvářejí sémantický jazykový model, který umožňuje vytvářet sofistikovaná řešení NLP pro analýzu textu, překlad, generování jazyka a další úlohy.
Poznámka:
Použili jsme pouze tři dimenze, protože je to snadné vizualizovat. Kodéry v transformátorových sítích ve skutečnosti vytvářejí vektory s mnoha dalšími dimenzemi a definují složité sémantické vztahy mezi tokeny na základě lineárních algebraických výpočtů. Matematika je složitá, stejně jako architektura transformátorového modelu. Naším cílem je poskytnout koncepční přehled o tom , jak kódování vytvoří model, který zapouzdřuje vztahy mezi entitami.
Multimodální modely
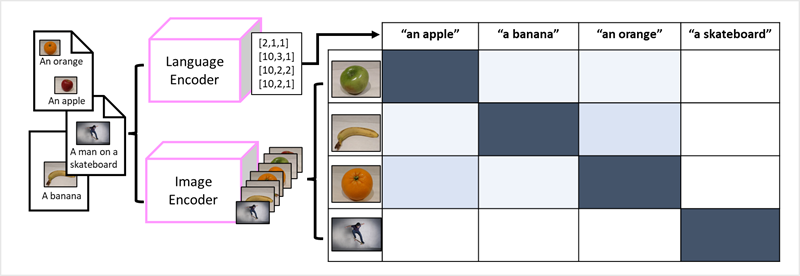
Úspěch transformátorů jako způsob vytváření jazykových modelů vedl výzkumné pracovníky umělé inteligence k tomu, aby zvážili, jestli by stejný přístup byl efektivní pro data obrázků. Výsledkem je vývoj multimodálních modelů, ve kterých je model trénován pomocí velkého objemu titulkovaných obrázků bez pevných popisků. Kodér obrázků extrahuje funkce z obrázků na základě hodnot pixelů a kombinuje je s vloženými texty vytvořenými kodérem jazyka. Celkový model zapouzdřuje vztahy mezi vkládáními tokenů přirozeného jazyka a funkcemi obrázků, jak je znázorněno tady:
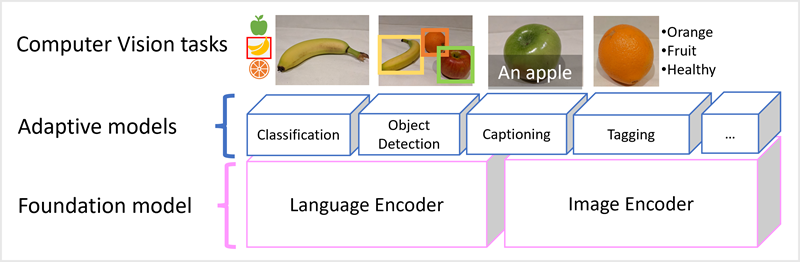
Model Microsoft Florence je jen takový model. Trénovaný s obrovskými objemy obrázků s titulky z internetu, zahrnuje kodér jazyka i kodér obrázků. Florencie je příkladem základního modelu. Jinými slovy, předem natrénovaný obecný model, na kterém můžete vytvořit několik adaptivních modelů pro specializované úlohy. Florencii můžete například použít jako základní model pro adaptivní modely, které provádějí:
- Klasifikace obrázků: Identifikace kategorie, do které obrázek patří.
- Rozpoznávání objektů: Vyhledání jednotlivých objektů v obrázku
- Titulky: Generování odpovídajících popisů obrázků
- Označování: Kompilace seznamu relevantních textových značek pro obrázek.
Multimodální modely, jako je Florencie, jsou obecně na špičkové úrovni počítačového zpracování obrazu a umělé inteligence a očekává se, že budou řídit pokroky v typech řešení, které umělá inteligence umožňuje.