Koncept – Nasazení aplikace
Před nasazením aplikace do Kubernetes si projdeme nasazení Kubernetes a probereme jejich omezení v našem scénáři.
Co jsou Kubernetes Deployments?
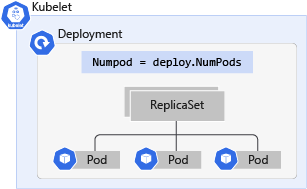
Nasazení Kubernetes představuje rozvoj podů. Nasazení zabalí pody do inteligentního objektu, který jim umožňuje škálování. Aplikaci můžete snadno duplikovat a škálovat, aby zvládla větší zatížení, aniž by bylo nutné konfigurovat složitá síťová pravidla.
Nasazení umožňují aktualizovat aplikace bez výpadků pouze změnou značky image. Aktualizace nasazení vypne online aplikace jedna po druhé a nahradí je nejnovější verzí místo vymazání všech aplikací a vytváření nových, což znamená, že nasazení může aktualizovat pody uvnitř ní bez viditelného dopadu na dostupnost.
I když existuje mnoho výhod použití Deploymentů ve srovnání s pody, nejsou schopny dostatečně řešit naši situaci.
Tento scénář zahrnuje aplikaci řízenou událostmi, která v různých časech přijímá velký počet událostí. Bez objektu KEDA Scaler nebo HPA byste museli ručně upravit počet replik pro zpracování množství událostí a zmenšit nasazení, když se zatížení vrátí do normálu.
Ukázkový manifest nasazení
Tady je ukázkový fragment kódu manifestu nasazení:
apiVersion: apps/v1
kind: Deployment
metadata:
name: contoso-microservice
spec:
replicas: 10 # Tells K8S the number of pods needed to process the Redis list items
selector: # Define the wrapping strategy
matchLabels: # Match all pods with the defined labels
app: contoso-microservice # Labels follow the `name: value` template
template: # Template of the pod inside the deployment
metadata:
labels:
app: contoso-microservice
spec:
containers:
- image: mcr.microsoft.com/mslearn/samples/redis-client:latest
name: contoso-microservice
V ukázkovém manifestu je replicas nastavená na 10, což je nejvyšší číslo, které můžeme nastavit pro nezbytné repliky dostupné ke zpracování maximálního počtu událostí. To ale způsobí, že aplikace bude spotřebovávat příliš mnoho prostředků během mimovrcholných časů, což může způsobit nedostatek prostředků pro jiné Deploymenty v rámci clusteru.
Jedním z řešení je použití samostatné HPA k monitorování využití procesoru podů, což je lepší možnost než manuální škálování zdrojů v obou směrech. HPA se ale nezaměří na počet událostí přijatých do seznamu Redis.
Nejlepším řešením je použít KEDA a škálovač Redis k dotazování na seznam a určit, jestli je k zpracování událostí potřeba více nebo méně podů.