Škálování pomocí KEDA
Automatické škálování řízené událostmi Kubernetes
Automatické škálování řízené událostmi Kubernetes (KEDA) je jednoúčelová a jednoduchá komponenta, která zjednodušuje automatické škálování aplikací. KeDA můžete přidat do libovolného clusteru Kubernetes a použít ho společně se standardními komponentami Kubernetes, jako je horizontální automatické škálování podů (HPA) nebo automatické škálování clusteru, a rozšířit tak jejich funkce. Pomocí NÁSTROJE KEDA můžete cílit na konkrétní aplikace, které chcete využít škálování řízené událostmi a umožnit ostatním aplikacím používat různé metody škálování. KEDA je flexibilní a bezpečná možnost spouštění společně s libovolným počtem aplikací nebo architektur Kubernetes.
Klíčové funkce a funkce
- Vytváření udržitelných a nákladově efektivních aplikací s využitím možností škálování na nulu
- Škálování aplikačních úloh tak, aby splňovaly poptávku pomocí škálovačů KEDA
- Automatické škálování aplikací pomocí
ScaledObjects - Automatické škálování úloh pomocí
ScaledJobs - Použití zabezpečení na úrovni produkčního prostředí oddělením automatického škálování a ověřování od úloh
- Použití vlastních externích škálovacích nástrojů pro použití přizpůsobených konfigurací automatického škálování
Architektura
KEDA poskytuje dvě hlavní komponenty:
-
Operátor KEDA: Umožňuje koncovým uživatelům škálovat úlohy od nuly do N instancí s podporou nasazení Kubernetes, úloh, stavových sad nebo jakéhokoli prostředku zákazníka, který definuje
/scalepodsourc. - Server metrik: Zveřejňuje externí metriky pro HPA, jako jsou zprávy v tématu Kafka nebo události ve službě Azure Event Hubs, aby bylo možno řídit akce automatického škálování. Kvůli upstreamům omezení musí být server metrik KEDA jediným nainstalovaným adaptérem metrik v clusteru.
Následující diagram znázorňuje integraci KEDA s platformou HPA Kubernetes, externími zdroji událostí a serverem rozhraní Kubernetes API, aby poskytoval funkce automatického škálování:
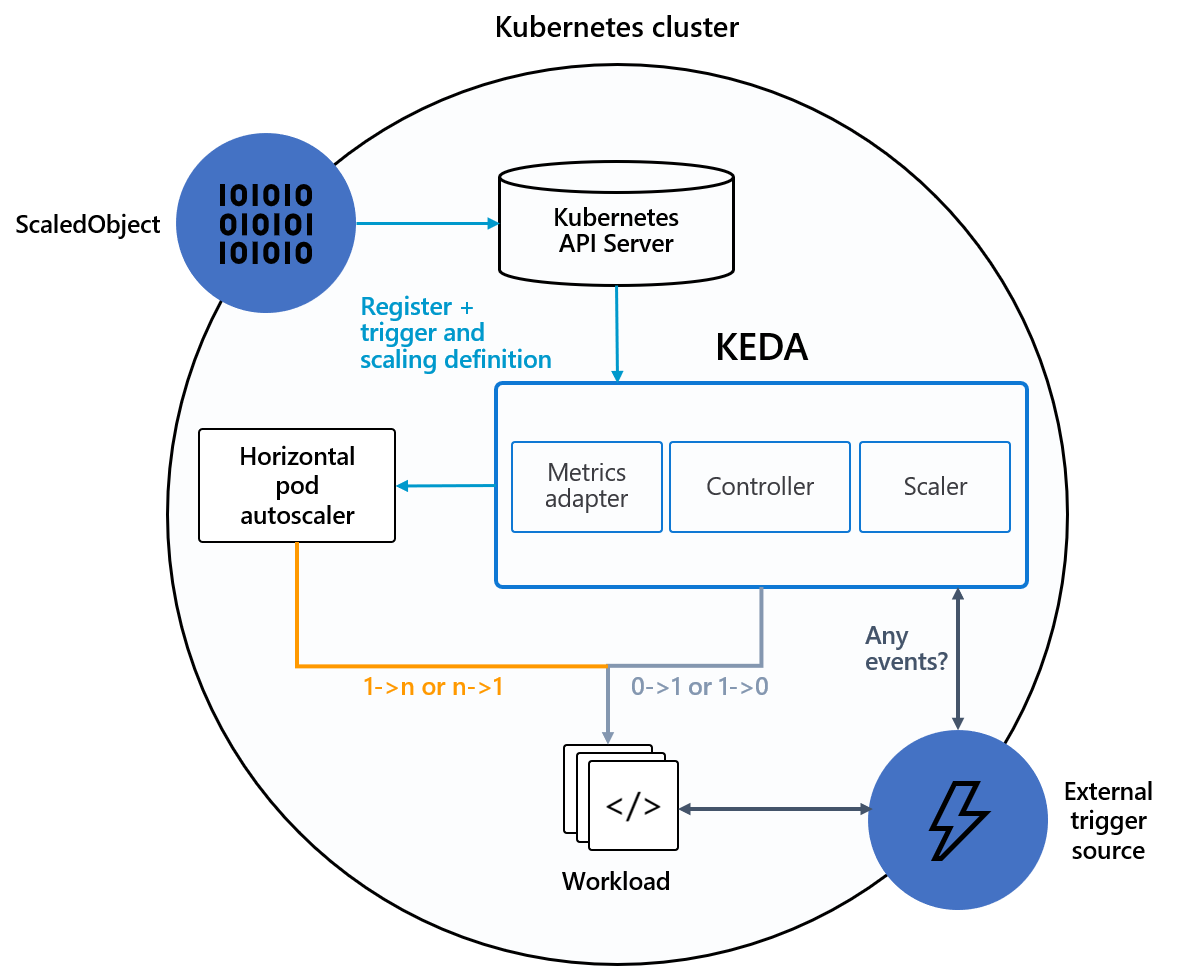
Tip
Další informace najdete v oficiální dokumentaci KEDA.
Zdroje událostí a škálovací moduly
Škálovací nástroje KEDA můžou zjistit, jestli se má nasazení aktivovat nebo deaktivovat, a můžou ho řadit vlastní metriky pro konkrétní zdroj událostí. Nasazení a stavové sady představují nejběžnější způsob škálování úloh pomocí KEDA. Můžete také škálovat vlastní prostředky, které implementují /scale podsourc. Můžete definovat nasazení Kubernetes nebo StatefulSet, které chcete keda škálovat na základě triggeru škálování. KEDA tyto služby monitoruje a automaticky je škáluje na základě událostí, ke kterým dochází.
KEDA na pozadí monitoruje zdroj událostí a odesílá tato data do Kubernetes a HPA, aby se urychlil škálování prostředků. Každá replika prostředku aktivně načítá položky ze zdroje událostí. Pomocí KEDA a Deployments/StatefulSetsmůžete škálovat na základě událostí a současně zachovat bohaté sémantiky připojení a zpracování se zdrojem událostí (například zpracování v pořadí, opakování, deadletter nebo kontrolní bod).
Specifikace škálovaného objektu
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Specifikace škálované úlohy
Jako alternativu ke škálování kódu řízeného událostmi jako nasazení můžete také spustit a škálovat kód jako úlohu Kubernetes. Primárním důvodem, proč tuto možnost zvážit, je, pokud potřebujete zpracovat dlouhotrvající spuštění. Místo zpracování více událostí v rámci nasazení každá zjištěná událost plánuje svou vlastní úlohu Kubernetes. Tento přístup umožňuje zpracovávat každou událost izolovaně a škálovat počet souběžných spuštění na základě počtu událostí ve frontě.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}