CREATE EXTERNAL TABLE (Transact-SQL)
Vytvoří externí tabulku.
Tento článek obsahuje syntaxi, argumenty, poznámky, oprávnění a příklady pro vámi zvolený produkt SQL.
Další informace o konvencích syntaxe najdete v tématu Transact-SQL konvence syntaxe.
Výběr produktu
V následujícím řádku vyberte název produktu, který vás zajímá, a zobrazí se jenom informace o daném produktu.
* SQL Server *
Azure Synapse
analýzy
Přehled: SQL Server
Tento příkaz vytvoří externí tabulku pro PolyBase pro přístup k datům uloženým v clusteru Hadoop nebo externí tabulce PolyBase služby Azure Blob Storage, která odkazuje na data uložená v clusteru Hadoop nebo ve službě Azure Blob Storage.
platí pro: SQL Server 2016 (nebo novější)
Pro dotazy PolyBase použijte externí tabulku s externím zdrojem dat. Externí zdroje dat slouží k navázání připojení a podpoře těchto primárních případů použití:
- Virtualizace dat a načítání dat pomocí PolyBase
- Operace hromadného načítání s využitím SQL Serveru nebo služby SQL Database pomocí
BULK INSERTneboOPENROWSET
Viz také CREATE EXTERNAL DATA SOURCE a DROP EXTERNAL TABLE.
Syntax
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Název tabulky, který se má vytvořit, je jedna až třídílná. V případě externí tabulky sql ukládá pouze metadata tabulky spolu se základními statistikami o souboru nebo složce, na které odkazuje Hadoop nebo Azure Blob Storage. Na SQL Serveru se nepřesouvají ani neukládají žádná skutečná data.
Důležitý
Pokud ovladač externího zdroje dat podporuje název třídílné části, důrazně doporučujeme zadat název třídílné části.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE podporuje možnost konfigurovat název sloupce, datový typ, hodnotu nullability a kolaci. U externích tabulek nemůžete použít VÝCHOZÍ OMEZENÍ.
Definice sloupců, včetně datových typů a počtu sloupců, musí odpovídat datům v externích souborech. Pokud dojde k neshodě, řádky souboru budou při dotazování na skutečná data odmítnuty.
LOCATION = 'folder_or_filepath'
Určuje složku nebo cestu k souboru a název souboru pro skutečná data v Hadoopu nebo Azure Blob Storage. Kromě toho se podporuje úložiště objektů kompatibilní s S3 počínaje SQL Serverem 2022 (16.x). Umístění začíná z kořenové složky. Kořenová složka je umístění dat zadané v externím zdroji dat.
Příkaz CREATE EXTERNAL TABLE v SQL Serveru vytvoří cestu a složku, pokud ještě neexistuje. Příkaz INSERT INTO pak můžete použít k exportu dat z místní tabulky SQL Serveru do externího zdroje dat. Další informace naleznete v tématu Dotazy PolyBase.
Pokud zadáte umístění jako složku, dotaz PolyBase, který vybere z externí tabulky, načte soubory ze složky a všech jejích podsložek. Stejně jako Hadoop nevrací PolyBase skryté složky. Také nevrací soubory, pro které název souboru začíná podtržením (_) nebo tečkou (.).
V následujícím příkladu obrázku, pokud LOCATION='/webdata/', dotaz PolyBase vrátí řádky z mydata.txt a mydata2.txt. Nevrátí mydata3.txt, protože se jedná o soubor ve skryté podsložce. A nevrátí _hidden.txt, protože se jedná o skrytý soubor.
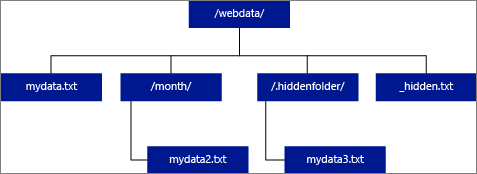
Pokud chcete změnit výchozí hodnotu a jen číst z kořenové složky, nastavte atribut <polybase.recursive.traversal> na false v konfiguračním souboru core-site.xml. Tento soubor se nachází v <SqlBinRoot>\PolyBase\Hadoop\Conf pod kořenem bin SQL Serveru. Například C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Určuje název externího zdroje dat, který obsahuje umístění externích dat. Toto umístění je systém souborů Hadoop (HDFS), kontejner služby Azure Blob Storage nebo Azure Data Lake Store. Chcete-li vytvořit externí zdroj dat, použijte VYTVOŘIT EXTERNÍ ZDROJ DAT.
FILE_FORMAT = external_file_format_name
Určuje název objektu formátu externího souboru, který ukládá typ souboru a metodu komprese externích dat. Chcete-li vytvořit formát externího souboru, použijte CREATE EXTERNAL FILE FORMAT.
Formáty externích souborů lze opakovaně používat více podobnými externími soubory.
Možnosti odmítnutí
Tuto možnost lze použít pouze u externích zdrojů dat, kde TYPE = HADOOP.
Můžete zadat parametry zamítnutí, které určují, jak Bude PolyBase zpracovávat špinavé záznamy, které načte z externího zdroje dat. Datový záznam se považuje za nezašpiněný, pokud se jedná o skutečné datové typy nebo počet sloupců, které neodpovídají definicím sloupců externí tabulky.
Pokud nezadáte nebo změníte hodnoty zamítnutí, PolyBase použije výchozí hodnoty. Tyto informace o parametrech zamítnutí jsou uloženy jako další metadata při vytváření externí tabulky s příkazem CREATE EXTERNAL TABLE. Když budoucí příkaz SELECT nebo příkaz SELECT INTO SELECT vybere data z externí tabulky, PolyBase použije možnosti odmítnutí k určení počtu nebo procenta řádků, které lze odmítnout dříve, než skutečný dotaz selže. Dotaz vrátí (částečné) výsledky, dokud nedojde k překročení prahové hodnoty zamítnutí. Poté selže s příslušnou chybovou zprávou.
REJECT_TYPE = hodnota | procento
Vysvětluje, zda je možnost REJECT_VALUE určena jako hodnota literálu nebo procento.
hodnoty
REJECT_VALUE je hodnota literálu, nikoli procento. Dotaz selže, když počet odmítnutých řádků překročí reject_value.
Pokud například REJECT_VALUE = 5 a REJECT_TYPE = value, dotaz SELECT selže po odmítnutí pěti řádků.
procento
REJECT_VALUE je procento, nikoli hodnota literálu. Dotaz selže, když procento neúspěšných řádků překročí reject_value. Procento neúspěšných řádků se počítá v intervalech.
REJECT_VALUE = reject_value
Určuje hodnotu nebo procento řádků, které lze odmítnout před selháním dotazu.
Pro REJECT_TYPE = hodnota musí být reject_value celé číslo od 0 do 2 147 483 647.
Pro REJECT_TYPE = procento musí být reject_value plovoucí mezi 0 a 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Tento atribut se vyžaduje, když zadáte REJECT_TYPE = procento. Určuje počet řádků, které se mají pokusit načíst, než PolyBase přepočítá procento odmítnutých řádků.
Parametr reject_sample_value musí být celé číslo od 0 do 2 147 483 647.
Pokud například REJECT_SAMPLE_VALUE = 1000, PolyBase vypočítá procento neúspěšných řádků po pokusu o import 1 000 řádků z externího datového souboru. Pokud je procento neúspěšných řádků menší než reject_value, PolyBase se pokusí načíst dalších 1 000 řádků. Po pokusu o import všech dalších 1 000 řádků pokračuje v přepočtu procenta neúspěšných řádků.
Poznámka
Vzhledem k tomu, že PolyBase vypočítá procento neúspěšných řádků v intervalech, skutečné procento neúspěšných řádků může překročit reject_value.
Příklad:
Tento příklad ukazuje, jak tři možnosti ODMÍTNUTÍ vzájemně spolupracují. Pokud například REJECT_TYPE = procento, REJECT_VALUE = 30 a REJECT_SAMPLE_VALUE = 100, může dojít k následujícímu scénáři:
- PolyBase se pokusí načíst prvních 100 řádků; 25 neúspěšných a 75 úspěšných.
- Procento neúspěšných řádků se vypočítá jako 25%, což je menší než hodnota odmítnutí 30%. Výsledkem je, že PolyBase bude pokračovat v načítání dat z externího zdroje dat.
- PolyBase se pokusí načíst dalších 100 řádků; tentokrát proběhne úspěšně 25 řádků a nezdaří se 75 řádků.
- Procento neúspěšných řádků se přepočítá jako 50%. Procento neúspěšných řádků překročilo hodnotu 30% odmítnutí.
- Dotaz PolyBase selže s 50% odmítnutými řádky po pokusu o vrácení prvních 200 řádků. Všimněte si, že před zjištěním prahové hodnoty odmítnutí dotazu PolyBase byly vráceny odpovídající řádky.
REJECTED_ROW_LOCATION = umístění adresáře
platí pro: SQL Server 2019 CU6 a novější verze, Azure Synapse Analytics.
Určuje adresář v rámci externího zdroje dat, že odmítnuté řádky a odpovídající chybový soubor by měly být zapsány.
Pokud zadaná cesta neexistuje, PolyBase ji za vás vytvoří. Vytvoří se podřízený adresář s názvem "_rejectedrows". Znak _zajistí, že adresář bude uchycený pro jiné zpracování dat, pokud není explicitně pojmenovaný v parametru location. V tomto adresáři existuje složka vytvořená na základě času odeslání v YearMonthDay -HourMinuteSecond formátu (např. 20230330-173205). V této složce jsou zapsány dva typy souborů, _reason soubor a datový soubor. Tuto možnost lze použít pouze s externími zdroji dat, kde TYPE = HADOOP a pro externí tabulky pomocí ODDĚLOVAČETEXT FORMAT_TYPE. Další informace naleznete v tématu CREATE EXTERNAL DATA SOURCE a CREATE EXTERNAL FILE FORMAT.
Soubory důvodů a datové soubory oba mají id dotazu přidružené k příkazu CTAS. Vzhledem k tomu, že data a důvod jsou v samostatných souborech, odpovídající soubory mají odpovídající příponu.
Dovolení
Vyžaduje tato uživatelská oprávnění:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (platí jenom pro externí zdroje dat Hadoop a Azure Storage).
- CONTROL DATABASE (platí jenom pro externí zdroje dat Hadoop a Azure Storage)
Všimněte si, že vzdálené přihlášení zadané v POVĚŘENÍ OBORU DATABÁZE použité v příkazu CREATE EXTERNAL TABLE musí mít oprávnění ke čtení pro cestu, tabulku nebo kolekci externího zdroje dat zadaného v parametru LOCATION. Pokud plánujete použít tuto EXTERNÍ TABULKU k exportu dat do externího zdroje dat Hadoop nebo Azure Storage, musí zadané přihlášení mít oprávnění k zápisu do cesty zadané v umístění. Všimněte si, že sql Server 2022 (16.x) v současné době nepodporuje Hadoop.
Pro Azure Blob Storage nakonfigurujte při konfiguraci přístupových klíčů a sdíleného přístupového podpisu (SAS) na webu Azure Portal účty úložiště Azure Blob Storage nebo ADLS Gen2, nakonfigurujte Povolená oprávnění tak, aby udělila alespoň oprávnění ke čtení a oprávnění k zápisu.
Oprávnění k seznamu může být také vyžadováno při hledání napříč složkami. Jako povolené typy prostředků musíte také vybrat
Důležitý
Oprávnění ALTER ANY EXTERNAL DATA SOURCE uděluje každému objektu objektu externího zdroje dat možnost vytvářet a upravovat všechny objekty externího zdroje dat, a proto také umožňuje přístup ke všem přihlašovacím údajům v databázi s vymezeným oborem databáze. Toto oprávnění musí být považováno za vysoce privilegované, a proto musí být uděleno pouze důvěryhodným objektům zabezpečení v systému.
Zpracování chyb
Při provádění příkazu CREATE EXTERNAL TABLE se PolyBase pokusí připojit k externímu zdroji dat. Pokud se pokus o připojení nezdaří, příkaz selže a externí tabulka se nevytvořila. Selhání příkazu může trvat minutu nebo déle, protože PolyBase připojení opakuje, než dotaz nakonec selže.
Poznámky
Ve scénářích ad hoc dotazů, například SELECT FROM EXTERNAL TABLE, polyBase ukládá řádky načtené z externího zdroje dat do dočasné tabulky. Po dokončení dotazu PolyBase odebere a odstraní dočasnou tabulku. V tabulkách SQL se neukládají žádná trvalá data.
Naproti tomu ve scénáři importu, například SELECT INTO FROM EXTERNAL TABLE, PolyBase ukládá řádky načtené z externího zdroje dat jako trvalá data v tabulce SQL. Nová tabulka se vytvoří během provádění dotazu, když PolyBase načte externí data.
PolyBase může do Hadoopu nasdílet některé výpočty dotazů, aby se zlepšil výkon dotazů. Tato akce se nazývá predikát pushdown. Chcete-li jej povolit, zadejte možnost umístění Správce prostředků Hadoop v VYTVOŘIT EXTERNÍ ZDROJ DAT.
Můžete vytvořit mnoho externích tabulek, které odkazují na stejné nebo různé externí zdroje dat.
Omezení a omezení
Vzhledem k tomu, že data pro externí tabulku nejsou pod přímým řízením správy SQL Serveru, je možné je kdykoli změnit nebo odebrat externím procesem. Výsledkem je, že výsledky dotazů vůči externí tabulce nemusí být deterministické. Stejný dotaz může při každém spuštění v externí tabulce vrátit různé výsledky. Podobně může dotaz selhat, pokud se externí data přesunou nebo odeberou.
Můžete vytvořit několik externích tabulek, které odkazují na různé externí zdroje dat. Pokud současně spouštíte dotazy na různé zdroje dat Hadoop, musí každý zdroj Hadoopu používat stejné nastavení konfigurace serveru hadoop. Nemůžete například současně spustit dotaz na cluster Cloudera Hadoop a cluster Hortonworks Hadoop, protože používají různá nastavení konfigurace. Informace o nastavení konfigurace a podporovaných kombinacích najdete v tématu Konfigurace připojení PolyBase.
Pokud externí tabulka používá DELIMITEDTEXT, CSV, PARQUETnebo DELTA jako datové typy, externí tabulky podporují statistiky pouze pro jeden sloupec na CREATE STATISTICS příkaz.
V externích tabulkách jsou povoleny pouze tyto příkazy DDL (Data Definition Language):
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Konstrukty a operace nejsou podporovány:
- Výchozí omezení pro sloupce externí tabulky
- Operace jazyka DML (Data Manipulat Language) odstranění, vložení a aktualizace
Omezení dotazů
PolyBase může při spouštění 32 souběžných dotazů PolyBase využívat maximálně 33 tisíc souborů na složku. Toto maximální číslo zahrnuje soubory i podsložky v každé složce HDFS. Pokud je stupeň souběžnosti menší než 32, může uživatel spouštět dotazy PolyBase na složky v HDFS, které obsahují více než 33k souborů. Doporučujeme zachovat krátké cesty k externím souborům a používat maximálně 30 tisíc souborů na složku HDFS. Pokud se odkazuje na příliš mnoho souborů, může dojít k výjimce prostředí Java Virtual Machine (JVM) mimo paměť.
Omezení šířky tabulky
PolyBase v SQL Serveru 2016 má limit šířky řádku 32 kB na základě maximální velikosti jednoho platného řádku podle definice tabulky. Pokud je součet schématu sloupce větší než 32 kB, PolyBase nemůže dotazovat data.
Omezení datových typů
V externích tabulkách PolyBase nelze použít následující datové typy:
geographygeometryhierarchyidimagetextnTextxml- Libovolný typ definovaný uživatelem
Omezení pro konkrétní zdroj dat
Věštírna
Synonyma Oracle nejsou podporována pro použití s PolyBase.
Externí tabulky kolekcí MongoDB, které obsahují pole
Pokud chcete vytvořit externí tabulky kolekcí MongoDB, které obsahují pole, měli byste použít rozšíření Data Virtualization pro Azure Data Studio k vytvoření příkazu CREATE EXTERNAL TABLE na základě schématu zjištěného ovladačem PolyBase ODBC pro MongoDB. Akce zploštění provádí ovladač automaticky. Případně můžete použít sp_data_source_table_columns také automaticky provede zplošťování prostřednictvím ovladače PolyBase ODBC pro ovladač MongoDB. Rozšíření Data Virtualization pro Azure Data Studio a sp_data_source_table_columns použít stejné interní uložené procedury k dotazování externího schématu.
Zamykání
Sdílený zámek objektu SCHEMARESOLUTION.
Bezpečnost
Datové soubory pro externí tabulku jsou uložené v Hadoopu nebo Azure Blob Storage. Tyto datové soubory se vytvářejí a spravují vlastními procesy. Zodpovídáte za správu zabezpečení externích dat.
Příklady
A. Vytvoření externí tabulky s daty ve formátu s oddělovači textu
Tento příklad ukazuje všechny kroky potřebné k vytvoření externí tabulky s daty formátovanými v souborech s oddělovači textu. Definuje externí zdroj dat mydatasource a formát externího souboru myfileformat. Na tyto objekty na úrovni databáze se pak odkazuje v příkazu CREATE EXTERNAL TABLE. Další informace naleznete v tématu CREATE EXTERNAL DATA SOURCE a CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Vytvoření externí tabulky s daty ve formátu RCFile
Tento příklad ukazuje všechny kroky potřebné k vytvoření externí tabulky s daty formátovanými jako RCFiles. Definuje externí zdroj dat mydatasource_rc a formát externího souboru myfileformat_rc. Na tyto objekty na úrovni databáze se pak odkazuje v příkazu CREATE EXTERNAL TABLE. Další informace naleznete v tématu CREATE EXTERNAL DATA SOURCE a CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Vytvoření externí tabulky s daty ve formátu ORC
Tento příklad ukazuje všechny kroky potřebné k vytvoření externí tabulky, která obsahuje data formátovaná jako soubory ORC. Definuje externí zdroj dat mydatasource_orc a formát externího souboru myfileformat_orc. Na tyto objekty na úrovni databáze se pak odkazuje v příkazu CREATE EXTERNAL TABLE. Další informace naleznete v tématu CREATE EXTERNAL DATA SOURCE a CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Dotazování dat Hadoopu
ClickStream je externí tabulka, která se připojuje k textovému souboru s oddělovači employee.tbl v clusteru Hadoop. Následující dotaz vypadá stejně jako dotaz na standardní tabulku. Tento dotaz ale načte data z Hadoopu a pak vypočítá výsledky.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Připojení dat Hadoopu k datům SQL
Tento dotaz vypadá stejně jako standardní join ve dvou tabulkách SQL. Rozdíl je v tom, že PolyBase načte data clickstream z Hadoopu a pak je spojí s tabulkou UrlDescription. Jedna tabulka je externí tabulka a druhá je standardní tabulka SQL.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Import dat z Hadoopu do tabulky SQL
Tento příklad vytvoří novou tabulku SQL ms_user, která trvale uloží výsledek spojení mezi standardní tabulkou SQL user a externí tabulkou ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Vytvoření externí tabulky pro SQL Server
Před vytvořením přihlašovacích údajů s vymezeným oborem databáze musí mít uživatelská databáze hlavní klíč pro ochranu přihlašovacích údajů. Další informace naleznete v tématu CREATE MASTER KEY a CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Vytvořte nový externí zdroj dat s názvem SQLServerInstancea externí tabulku s názvem sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
Já. Vytvoření externí tabulky pro Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Vytvoření externí tabulky pro Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Vytvoření externí tabulky pro MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Dotazování úložiště objektů kompatibilních s S3 prostřednictvím externí tabulky
platí pro: SQL Server 2022 (16.x) a novější
Následující příklad ukazuje použití T-SQL k dotazování souboru parquet uloženého v úložišti objektů kompatibilním s S3 prostřednictvím dotazování externí tabulky. Ukázka používá relativní cestu v rámci externího zdroje dat.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Další kroky
Další informace o souvisejících konceptech najdete v následujících článcích:
- VYTVOŘENÍ EXTERNÍHO ZDROJE DAT
- VYTVOŘIT FORMÁT EXTERNÍHO SOUBORU
-
sp_data_source_objects (Transact-SQL) - rozšíření Data Virtualization pro Azure Data Studio
* Azure SQL Database *
Azure Synapse
analýzy
Přehled: Azure SQL Database
Ve službě Azure SQL Database vytvoří externí tabulku pro elastické dotazy (ve verzi Preview).
Viz také VYTVOŘENÍ EXTERNÍHO ZDROJE DAT.
Syntax
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Název tabulky, který se má vytvořit, je jedna až třídílná. U externí tabulky ukládá SQL pouze metadata tabulky spolu se základními statistikami o souboru nebo složce, na kterou odkazuje azure SQL Database. Ve službě Azure SQL Database se nepřesouvají ani neukládají žádná skutečná data.
Důležitý
Pokud ovladač externího zdroje dat podporuje název třídílné části, důrazně doporučujeme zadat název třídílné části.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE podporuje možnost konfigurovat název sloupce, datový typ, hodnotu nullability a kolaci. U externích tabulek nemůžete použít VÝCHOZÍ OMEZENÍ.
Poznámka
Text, nText a XML nejsou podporované datové typy pro sloupce v externích tabulkách pro Azure SQL Database.
Definice sloupců, včetně datových typů a počtu sloupců, musí odpovídat datům v externích souborech. Pokud dojde k neshodě, řádky souboru budou při dotazování na skutečná data odmítnuty.
Možnosti horizontálně dělené externí tabulky
Určuje externí zdroj dat (zdroj dat mimo SQL Server) a metodu distribuce pro elastický dotaz.
DATA_SOURCE
Klauzule DATA_SOURCE definuje externí zdroj dat (mapování horizontálních oddílů), který se používá pro externí tabulku. Příklad najdete v tématu Vytvoření externích tabulek.
Důležitý
Azure SQL Database podporuje vytváření externích tabulek pro typy EXTERNÍCH ZDROJŮ DAT RDMS a SHARD_MAP_MANAGER. Azure SQL Database nepodporuje vytváření externích tabulek do služby Azure Blob Storage.
SCHEMA_NAME a OBJECT_NAME
Klauzule SCHEMA_NAME a OBJECT_NAME mapují definici externí tabulky na tabulku v jiném schématu. Pokud toto vynecháte, předpokládá se, že schéma vzdáleného objektu je "dbo" a jeho název je považován za stejný jako název externí tabulky, který je definován. To je užitečné, pokud je název vzdálené tabulky již převzat v databázi, ve které chcete vytvořit externí tabulku. Chcete například definovat externí tabulku, abyste získali agregované zobrazení zobrazení katalogu nebo zobrazení dynamické správy na datové vrstvě s horizontálním navýšením kapacity. Vzhledem k tomu, že zobrazení katalogu a zobrazení dynamické správy již existují místně, nemůžete použít jejich názvy pro definici externí tabulky. Místo toho použijte jiný název a v klauzulích SCHEMA_NAME nebo OBJECT_NAME použijte název zobrazení katalogu nebo název zobrazení dynamické správy. Příklad najdete v tématu Vytvoření externích tabulek.
DISTRIBUCE
Volitelný. Tento argument je vyžadován pouze pro databáze typu SHARD_MAP_MANAGER. Tento argument určuje, jestli se tabulka považuje za dělenou tabulku nebo replikovanou tabulku. U tabulek SHARDED (název sloupce) se data z různých tabulek nepřekrývají. REPLIKOVANÝ určuje, že tabulky mají stejná data v každém horizontálním oddílu. ROUND_ROBIN označuje, že k distribuci dat se používá metoda specifická pro aplikaci.
Klauzule DISTRIBUTION určuje distribuci dat použitou pro tuto tabulku. Procesor dotazů využívá informace uvedené v klauzuli DISTRIBUTION k vytvoření nejúčinnějších plánů dotazů.
- Horizontální dělení znamená, že data se horizontálně rozdělují mezi databáze. Klíč dělení pro distribuci dat je parametr
sharding_column_name. - REPLIKOVANÉ znamená, že v každé databázi jsou přítomny stejné kopie tabulky. Je vaší zodpovědností zajistit, aby repliky byly v databázích stejné.
- ROUND_ROBIN znamená, že tabulka je horizontálně rozdělená pomocí metody distribuce závislé na aplikaci.
Dovolení
Uživatelé s přístupem k externí tabulce automaticky získají přístup k podkladovým vzdáleným tabulkám v rámci přihlašovacích údajů zadaných v definici externího zdroje dat. Vyhněte se nežádoucímu zvýšení oprávnění prostřednictvím přihlašovacích údajů externího zdroje dat. Pro externí tabulku použijte funkci GRANT nebo REVOKE stejně, jako by šlo o běžnou tabulku. Po definování externího zdroje dat a externích tabulek teď můžete pro externí tabulky použít úplný T-SQL.
Zpracování chyb
Při provádění příkazu CREATE EXTERNAL TABLE, pokud pokus o připojení selže, příkaz selže a externí tabulka se nevytvoří. Může trvat minutu nebo déle, než se příkaz nezdaří, protože SQL Database opakuje připojení, než dotaz nakonec selže.
Poznámky
Ve scénářích ad hoc dotazů, jako je například SELECT FROM EXTERNAL TABLE, ukládá služba SQL Database řádky načtené z externího zdroje dat do dočasné tabulky. Po dokončení dotazu sql Database odebere a odstraní dočasnou tabulku. V tabulkách SQL se neukládají žádná trvalá data.
Naproti tomu ve scénáři importu, například SELECT INTO FROM EXTERNAL TABLE, ukládá sql Database řádky načtené z externího zdroje dat jako trvalá data v tabulce SQL. Nová tabulka se vytvoří během provádění dotazu, když SQL Database načte externí data.
Můžete vytvořit mnoho externích tabulek, které odkazují na stejné nebo různé externí zdroje dat.
Můžete vytvořit několik externích tabulek, které odkazují na různé externí zdroje dat.
Omezení
sémantiku izolace: Přístup k datům prostřednictvím externí tabulky neodpovídá sémantice izolace v RÁMCI SQL Serveru. To znamená, že dotazování externí tabulky neukládá žádné uzamčení ani izolaci snímků. Vrácení dat se proto může změnit, pokud se data v externím zdroji dat mění. Stejný dotaz může při každém spuštění v externí tabulce vrátit různé výsledky. Podobně může dotaz selhat, pokud se externí data přesunou nebo odeberou.
konstruktorů a operací, kterénepodporují:
- Výchozí omezení pro sloupce externí tabulky.
- Operace jazyka DML (Data Manipulat Language) odstranění, vložení a aktualizace
- dynamické maskování dat ve sloupcích externí tabulky.
- Kurzory nejsou podporovány pro externí tabulky ve službě Azure SQL Database.
Pouze literálové predikáty: Do externího zdroje dat lze odeslat pouze literální predikáty definované v dotazu. To je na rozdíl od propojených serverů a přístupu k tomu, kde se dají použít predikáty určené během provádění dotazů, to znamená, že pokud se používá ve spojení s vnořenou smyčkou v plánu dotazu. To často povede ke zkopírování celé externí tabulky místně a následnému spojení.
Pokud je v následujícím příkladu
External.Ordersexterní tabulka aCustomerje místní tabulka, dotaz zkopíruje celou externí tabulku místně, protože v době kompilace není potřeba predikát.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );žádná paralelismus: Použití externích tabulek brání použití paralelismu v plánu dotazu.
Spuštěno jako vzdálený dotaz: Externí tabulky se implementují jako vzdálený dotaz, takže odhadovaný počet vrácených řádků je obecně 1 000. Existují další pravidla založená na typu predikátu použitého k filtrování externí tabulky. Jedná se o odhady založené na pravidlech, nikoli odhady na základě skutečných dat v externí tabulce. Optimalizátor nemá přístup ke vzdálenému zdroji dat, aby získal přesnější odhad.
Nepodporuje se uprivátního koncového bodu: Dotazy externí tabulky nejsou podporovány, pokud je připojení ke vzdálené tabulce privátním koncovým bodem.
Omezení datových typů
V externích tabulkách PolyBase nelze použít následující datové typy:
geographygeometryhierarchyidimagetextnTextxml- Libovolný typ definovaný uživatelem
Zamykání
Sdílený zámek objektu SCHEMARESOLUTION.
Příklady
A. Vytvoření externí tabulky pro Azure SQL Database
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Vytvoření externí tabulky pro horizontálně dělený zdroj dat
Tento příklad přemapuje vzdálené zobrazení dynamické správy na externí tabulku pomocí SCHEMA_NAME a OBJECT_NAME klauzulí.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Další kroky
Další informace o externích tabulkách ve službě Azure SQL Database najdete v následujících článcích:
* Azure Synapse
Analýza *
Přehled: Azure Synapse Analytics
Externí tabulka slouží k:
- Vyhrazené fondy SQL můžou dotazovat, importovat a ukládat data z Hadoopu, Azure Blob Storage a Azure Data Lake Storage Gen1 a Gen2.
- Bezserverové fondy SQL můžou dotazovat, importovat a ukládat data ze služby Azure Blob Storage, Azure Data Lake Storage Gen1 a Gen2. Bezserverová služba nepodporuje
TYPE=Hadoop.
Viz také CREATE EXTERNAL DATA SOURCE a DROP EXTERNAL TABLE.
Další pokyny a příklady použití externích tabulek s Azure Synapse najdete v tématu Použití externích tabulek se službou Synapse SQL.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Název tabulky, který se má vytvořit, je jedna až třídílná. U externí tabulky platí, že pouze metadata tabulky spolu se základními statistikami o souboru nebo složce, na které se odkazuje ve službě Azure Data Lake, Hadoop nebo Azure Blob Storage. Při vytváření externích tabulek se nepřesouvají ani neukládají žádná skutečná data.
Důležitý
Pokud ovladač externího zdroje dat podporuje název třídílné části, důrazně doporučujeme zadat název třídílné části.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE podporuje možnost konfigurovat název sloupce, datový typ, hodnotu nullability a kolaci. U externích tabulek nemůžete použít VÝCHOZÍ OMEZENÍ.
Poznámka
Zastaralé datové typy text, ntext a XML nejsou podporované datové typy pro sloupce v externích tabulkách pro Synapse Analytics.
- Při čtení souborů s oddělovači musí definice sloupců, včetně datových typů a počtu sloupců, odpovídat datům v externích souborech. Pokud dojde k neshodě, řádky souboru budou při dotazování na skutečná data odmítnuty.
- Při čtení ze souborů Parquet můžete zadat pouze sloupce, které chcete číst, a přeskočit zbytek.
LOCATION = 'folder_or_filepath'
Určuje složku nebo cestu k souboru a název souboru pro skutečná data ve službě Azure Data Lake, Hadoop nebo Azure Blob Storage. Umístění začíná z kořenové složky. Kořenová složka je umístění dat zadané v externím zdroji dat. Příkaz CREATE EXTERNAL TABLE AS SELECT vytvoří cestu a složku, pokud neexistuje.
CREATE EXTERNAL TABLE cestu a složku nevytvoří.
Pokud zadáte umístění jako složku, dotaz PolyBase, který vybere z externí tabulky, načte soubory ze složky a všech jejích podsložek. Stejně jako Hadoop nevrací PolyBase skryté složky. Také nevrací soubory, pro které název souboru začíná podtržením (_) nebo tečkou (.).
V následujícím příkladu obrázku, pokud LOCATION='/webdata/', dotaz PolyBase vrátí řádky z mydata.txt a mydata2.txt. Nevrátí mydata3.txt, protože je v podsložce skryté složky. A nevrátí _hidden.txt, protože se jedná o skrytý soubor.
Na rozdíl od externích tabulek Hadoop nevrací nativní externí tabulky podsložky, pokud nezadáte /** na konci cesty. V tomto příkladu, pokud LOCATION='/webdata/', dotaz bezserverového fondu SQL, vrátí řádky z mydata.txt. Nevrátí mydata2.txt a mydata3.txt, protože jsou umístěné v podsložce. Tabulky Hadoop vrátí všechny soubory v jakékoli podsložce.
Jak Hadoop, tak nativní externí tabulky přeskočí soubory s názvy, které začínají podtržením (_) nebo tečkou (.).
DATA_SOURCE = external_data_source_name
Určuje název externího zdroje dat, který obsahuje umístění externích dat. Toto umístění je v Azure Data Lake. Chcete-li vytvořit externí zdroj dat, použijte VYTVOŘIT EXTERNÍ ZDROJ DAT.
FILE_FORMAT = external_file_format_name
Určuje název objektu formátu externího souboru, který ukládá typ souboru a metodu komprese externích dat. Chcete-li vytvořit formát externího souboru, použijte CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Určuje sadu možností, které popisují, jak číst podkladové soubory. V současné době je jedinou dostupnou možností {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}, která externí tabulce dává pokyn ignorovat aktualizace provedené v podkladových souborech, i když to může způsobit nekonzistentní operace čtení. Tuto možnost použijte pouze ve speciálních případech, kdy máte často připojené soubory. Tato možnost je k dispozici v bezserverovém fondu SQL pro formát CSV.
Možnosti ODMÍTNUTÍ
Možnosti zamítnutí jsou ve verzi Preview pro bezserverové fondy SQL ve službě Azure Synapse Analytics.
Tuto možnost lze použít pouze u externích zdrojů dat, kde TYPE = HADOOP.
Můžete zadat parametry zamítnutí, které určují, jak Bude PolyBase zpracovávat špinavé záznamy, které načte z externího zdroje dat. Datový záznam se považuje za nezašpiněný, pokud se jedná o skutečné datové typy nebo počet sloupců, které neodpovídají definicím sloupců externí tabulky.
Pokud nezadáte nebo změníte hodnoty zamítnutí, PolyBase použije výchozí hodnoty. Tyto informace o parametrech zamítnutí jsou uloženy jako další metadata při vytváření externí tabulky s příkazem CREATE EXTERNAL TABLE. Když budoucí příkaz SELECT nebo příkaz SELECT INTO SELECT vybere data z externí tabulky, PolyBase použije možnosti odmítnutí k určení počtu nebo procenta řádků, které lze odmítnout dříve, než skutečný dotaz selže. Dotaz vrátí (částečné) výsledky, dokud nedojde k překročení prahové hodnoty zamítnutí. Poté selže s příslušnou chybovou zprávou.
Možnost formátu PARSER_VERSION je podporována pouze v bezserverových fondech SQL.
REJECT_TYPE = hodnota | procento
Vysvětluje, zda je možnost REJECT_VALUE určena jako hodnota literálu nebo procento.
hodnoty
REJECT_VALUE je hodnota literálu, nikoli procento. Dotaz PolyBase selže, pokud počet odmítnutých řádků překročí reject_value.
Pokud například REJECT_VALUE = 5 a REJECT_TYPE = hodnota, dotaz PolyBase SELECT selže po odmítnutí pěti řádků.
procento
REJECT_VALUE je procento, nikoli hodnota literálu. Dotaz PolyBase selže, když procento neúspěšných řádků překročí reject_value. Procento neúspěšných řádků se počítá v intervalech.
REJECT_VALUE = reject_value
Určuje hodnotu nebo procento řádků, které lze odmítnout před selháním dotazu.
- Pro REJECT_TYPE = hodnota musí být reject_value celé číslo od 0 do 2 147 483 647.
- Pro REJECT_TYPE = procento musí být reject_value plovoucí mezi 0 a 100. Procento je platné pouze pro vyhrazené fondy SQL, kde
TYPE=HADOOP.
Dotaz selže, když počet odmítnutých řádků překročí reject_value. Pokud například REJECT_VALUE = 5 a REJECT_TYPE = hodnota, dotaz SELECT selže po odmítnutí pěti řádků.
REJECT_SAMPLE_VALUE = reject_sample_value
Tento atribut se vyžaduje, když zadáte REJECT_TYPE = procento. Určuje počet řádků, které se mají pokusit načíst, než PolyBase přepočítá procento odmítnutých řádků.
Parametr reject_sample_value musí být celé číslo od 0 do 2 147 483 647.
Pokud například REJECT_SAMPLE_VALUE = 1000, PolyBase vypočítá procento neúspěšných řádků po pokusu o import 1 000 řádků z externího datového souboru. Pokud je procento neúspěšných řádků menší než reject_value, PolyBase se pokusí načíst dalších 1 000 řádků. Po pokusu o import všech dalších 1 000 řádků pokračuje v přepočtu procenta neúspěšných řádků.
Poznámka
Vzhledem k tomu, že PolyBase vypočítá procento neúspěšných řádků v intervalech, skutečné procento neúspěšných řádků může překročit reject_value.
Příklad:
Tento příklad ukazuje, jak tři možnosti ODMÍTNUTÍ vzájemně spolupracují. Pokud například REJECT_TYPE = procento, REJECT_VALUE = 30 a REJECT_SAMPLE_VALUE = 100, může dojít k následujícímu scénáři:
- PolyBase se pokusí načíst prvních 100 řádků; 25 neúspěšných a 75 úspěšných.
- Procento neúspěšných řádků se vypočítá jako 25%, což je menší než hodnota odmítnutí 30%. Výsledkem je, že PolyBase bude pokračovat v načítání dat z externího zdroje dat.
- PolyBase se pokusí načíst dalších 100 řádků; tentokrát proběhne úspěšně 25 řádků a nezdaří se 75 řádků.
- Procento neúspěšných řádků se přepočítá jako 50%. Procento neúspěšných řádků překročilo hodnotu 30% odmítnutí.
- Dotaz PolyBase selže s 50% odmítnutými řádky po pokusu o vrácení prvních 200 řádků. Všimněte si, že před zjištěním prahové hodnoty odmítnutí dotazu PolyBase byly vráceny odpovídající řádky.
REJECTED_ROW_LOCATION = umístění adresáře
Určuje adresář v rámci externího zdroje dat, že odmítnuté řádky a odpovídající chybový soubor by měly být zapsány.
Pokud zadaná cesta neexistuje, vytvoří se. Vytvoří se podřízený adresář s názvem _rejectedrows. Znak _ zajistí, že adresář bude uchycený pro jiné zpracování dat, pokud není explicitně pojmenovaný v parametru location.
- V bezserverových fondech SQL je cesta
YearMonthDay_HourMinuteSecond_StatementID. ID příkazu můžete použít ke korelaci složky s dotazem, který ho vygeneroval. - Ve vyhrazených fondech SQL je vytvořená cesta založená na době odeslání zatížení ve formátu
YearMonthDay -HourMinuteSecond, například20180330-173205.
V této složce jsou zapsány dva typy souborů, _reason soubor a datový soubor.
Další informace naleznete v tématu CREATE EXTERNAL DATA SOURCE.
Soubory důvodů a datové soubory oba mají id dotazu přidružené k příkazu CTAS. Vzhledem k tomu, že data a důvod jsou v samostatných souborech, odpovídající soubory mají odpovídající příponu.
V bezserverových fondech SQL soubor error.json obsahuje pole JSON s zjištěnými chybami souvisejícími s odmítnutými řádky. Každý prvek představující chybu obsahuje následující atributy:
| Atribut | Popis |
|---|---|
| Chyba | Důvod zamítnutí řádku |
| Veslovat | Odmítnuté pořadové číslo řádku v souboru |
| Sloupec | Odmítnuté pořadové číslo sloupce |
| Hodnota | Odmítnutá hodnota sloupce Pokud je hodnota větší než 100 znaků, zobrazí se pouze prvních 100 znaků. |
| Soubor | Cesta k souboru, do kterého řádek patří. |
Dovolení
Vyžaduje tato uživatelská oprávnění:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Poznámka
Oprávnění CONTROL DATABASE jsou nutná k vytvoření pouze HLAVNÍHO KLÍČE, PŘIHLAŠOVACÍCH ÚDAJŮ S OBOREM DATABÁZE a EXTERNÍHO ZDROJE DAT.
Upozorňujeme, že přihlášení, které vytvoří externí zdroj dat, musí mít oprávnění ke čtení a zápisu do externího zdroje dat umístěného v Hadoopu nebo Azure Blob Storage.
Důležitý
Oprávnění ALTER ANY EXTERNAL DATA SOURCE uděluje každému objektu objektu externího zdroje dat možnost vytvářet a upravovat všechny objekty externího zdroje dat, a proto také umožňuje přístup ke všem přihlašovacím údajům v databázi s vymezeným oborem databáze. Toto oprávnění musí být považováno za vysoce privilegované, a proto musí být uděleno pouze důvěryhodným objektům zabezpečení v systému.
Zpracování chyb
Při provádění příkazu CREATE EXTERNAL TABLE se PolyBase pokusí připojit k externímu zdroji dat. Pokud se pokus o připojení nezdaří, příkaz selže a externí tabulka se nevytvořila. Selhání příkazu může trvat minutu nebo déle, protože PolyBase připojení opakuje, než dotaz nakonec selže.
Poznámky
Ve scénářích ad hoc dotazů, například SELECT FROM EXTERNAL TABLE, polyBase ukládá řádky načtené z externího zdroje dat do dočasné tabulky. Po dokončení dotazu PolyBase odebere a odstraní dočasnou tabulku. V tabulkách SQL se neukládají žádná trvalá data.
Naproti tomu ve scénáři importu, například SELECT INTO FROM EXTERNAL TABLE, PolyBase ukládá řádky načtené z externího zdroje dat jako trvalá data v tabulce SQL. Nová tabulka se vytvoří během provádění dotazu, když PolyBase načte externí data.
PolyBase může do Hadoopu nasdílet některé výpočty dotazů, aby se zlepšil výkon dotazů. Tato akce se nazývá predikát pushdown. Chcete-li jej povolit, zadejte možnost umístění Správce prostředků Hadoop v VYTVOŘIT EXTERNÍ ZDROJ DAT.
Můžete vytvořit mnoho externích tabulek, které odkazují na stejné nebo různé externí zdroje dat.
Věnujte pozornost zdrojovým datům pomocí kolace UTF-8. Pro všechna zdrojová data používající kolaci UTF-8 je nutné ručně zadat jiné kolace než UTF-8 každý sloupec UTF-8 v příkazu CREATE EXTERNAL TABLE. Důvodem je to, že podpora UTF-8 se nevztahuje na externí tabulky. Při pokusu o vytvoření externí tabulky s kolací UTF-8 se zobrazí chybová zpráva Unsupported collation. Pokud je kolace databáze externí tabulky kolace UTF-8, vytvoření externí tabulky selže, pokud nezadáte explicitní kolaci sloupců bez UTF-8, například [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,.
Bezserverové a vyhrazené fondy SQL ve službě Azure Synapse Analytics používají různé základy kódu pro virtualizaci dat. Bezserverové fondy SQL podporují nativní technologii virtualizace dat. Vyhrazené fondy SQL podporují nativní i virtualizaci dat PolyBase. Virtualizace dat PolyBase se používá při vytváření EXTERNÍHO ZDROJE DAT s TYPE=HADOOP.
Omezení a omezení
Vzhledem k tomu, že data pro externí tabulku nejsou pod přímým řízením správy Azure Synapse, je možné je kdykoli změnit nebo odebrat externím procesem. Výsledkem je, že výsledky dotazů vůči externí tabulce nemusí být deterministické. Stejný dotaz může při každém spuštění v externí tabulce vrátit různé výsledky. Podobně může dotaz selhat, pokud se externí data přesunou nebo odeberou.
Můžete vytvořit několik externích tabulek, které odkazují na různé externí zdroje dat.
V externích tabulkách jsou povoleny pouze tyto příkazy DDL (Data Definition Language):
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Konstrukty a operace nejsou podporovány:
- Výchozí omezení pro sloupce externí tabulky
- Operace jazyka DML (Data Manipulat Language) odstranění, vložení a aktualizace
- dynamické maskování dat ve sloupcích externí tabulky
Omezení dotazů
Doporučuje se nepřekračovat více než 30 tisíc souborů na složku. Pokud se odkazuje na příliš mnoho souborů, může dojít k výjimce prostředí Java Virtual Machine (JVM) mimo paměť nebo může dojít ke snížení výkonu.
Omezení šířky tabulky
PolyBase v Azure Data Warehouse má limit šířky řádků 1 MB na základě maximální velikosti jednoho platného řádku podle definice tabulky. Pokud je součet schématu sloupců větší než 1 MB, PolyBase nemůže dotazovat data.
Omezení datových typů
V externích tabulkách PolyBase nelze použít následující datové typy:
geographygeometryhierarchyidimagetextnTextxml- Libovolný typ definovaný uživatelem
Zamykání
Sdílený zámek objektu SCHEMARESOLUTION.
Příklady
A. Import dat z ADLS Gen2 do Azure Synapse Analytics
Příklady pro Gen ADLS Gen 1 najdete v tématu Vytvoření externího zdroje dat.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Import dat z Parquet do Azure Synapse Analytics
Následující příklad vytvoří externí tabulku. Potom vrátí první řádek:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Další kroky
Další informace o externích tabulkách a souvisejících konceptech najdete v následujících článcích:
- VYTVOŘENÍ EXTERNÍHO ZDROJE DAT
- VYTVOŘIT FORMÁT EXTERNÍHO SOUBORU
- CREATE EXTERNAL TABLE AS SELECT
- CREATE TABLE AS SELECT (Azure Synapse Analytics)
Azure Synapse
analýzy
* Analytics
Systém platformy (PDW) *
Přehled: Systém analytických platforem
Externí tabulka slouží k:
- Dotazování dat Hadoopu nebo Azure Blob Storage pomocí příkazů Transact-SQL
- Importujte a ukládejte data z Hadoopu nebo Azure Blob Storage do systému Analytics Platform System.
Viz také CREATE EXTERNAL DATA SOURCE a DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Název tabulky, který se má vytvořit, je jedna až třídílná. V případě externí tabulky ukládá systém Analytics Platform Pouze metadata tabulky spolu se základními statistikami o souboru nebo složce, na které odkazuje Hadoop nebo Azure Blob Storage. Ve službě Analytics Platform System se nepřesouvají ani neukládají žádná skutečná data.
Důležitý
Pokud ovladač externího zdroje dat podporuje název třídílné části, důrazně doporučujeme zadat název třídílné části.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE podporuje možnost konfigurovat název sloupce, datový typ, hodnotu nullability a kolaci. U externích tabulek nemůžete použít VÝCHOZÍ OMEZENÍ.
Definice sloupců, včetně datových typů a počtu sloupců, musí odpovídat datům v externích souborech. Pokud dojde k neshodě, řádky souboru budou při dotazování na skutečná data odmítnuty.
LOCATION = 'folder_or_filepath'
Určuje složku nebo cestu k souboru a název souboru pro skutečná data v Hadoopu nebo Azure Blob Storage. Umístění začíná z kořenové složky. Kořenová složka je umístění dat zadané v externím zdroji dat.
V nástroji Analytics Platform System vytvoří příkaz CREATE EXTERNAL TABLE AS SELECT cestu a složku, pokud neexistuje.
CREATE EXTERNAL TABLE cestu a složku nevytvoří.
Pokud zadáte umístění jako složku, dotaz PolyBase, který vybere z externí tabulky, načte soubory ze složky a všech jejích podsložek. Stejně jako Hadoop nevrací PolyBase skryté složky. Také nevrací soubory, pro které název souboru začíná podtržením (_) nebo tečkou (.).
V následujícím příkladu obrázku, pokud LOCATION='/webdata/', dotaz PolyBase vrátí řádky z mydata.txt a mydata2.txt. Nevrátí mydata3.txt, protože je v podsložce skryté složky. A nevrátí _hidden.txt, protože se jedná o skrytý soubor.
Pokud chcete změnit výchozí hodnotu a jen číst z kořenové složky, nastavte atribut <polybase.recursive.traversal> na false v konfiguračním souboru core-site.xml. Tento soubor se nachází v <SqlBinRoot>\PolyBase\Hadoop\Conf\ pod kořenem bin SQL Serveru. Například C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Určuje název externího zdroje dat, který obsahuje umístění externích dat. Toto umístění je Hadoop nebo Azure Blob Storage. Chcete-li vytvořit externí zdroj dat, použijte VYTVOŘIT EXTERNÍ ZDROJ DAT.
FILE_FORMAT = external_file_format_name
Určuje název objektu formátu externího souboru, který ukládá typ souboru a metodu komprese externích dat. Chcete-li vytvořit formát externího souboru, použijte CREATE EXTERNAL FILE FORMAT.
Možnosti odmítnutí
Tuto možnost lze použít pouze u externích zdrojů dat, kde TYPE = HADOOP.
Můžete zadat parametry zamítnutí, které určují, jak Bude PolyBase zpracovávat špinavé záznamy, které načte z externího zdroje dat. Datový záznam se považuje za nezašpiněný, pokud se jedná o skutečné datové typy nebo počet sloupců, které neodpovídají definicím sloupců externí tabulky.
Pokud nezadáte nebo změníte hodnoty zamítnutí, PolyBase použije výchozí hodnoty. Tyto informace o parametrech zamítnutí jsou uloženy jako další metadata při vytváření externí tabulky s příkazem CREATE EXTERNAL TABLE. Když budoucí příkaz SELECT nebo příkaz SELECT INTO SELECT vybere data z externí tabulky, PolyBase použije možnosti odmítnutí k určení počtu nebo procenta řádků, které lze odmítnout dříve, než skutečný dotaz selže. Dotaz vrátí (částečné) výsledky, dokud nedojde k překročení prahové hodnoty zamítnutí. Poté selže s příslušnou chybovou zprávou.
REJECT_TYPE = hodnota | procento
Vysvětluje, zda je možnost REJECT_VALUE určena jako hodnota literálu nebo procento.
hodnoty
REJECT_VALUE je hodnota literálu, nikoli procento. Dotaz PolyBase selže, pokud počet odmítnutých řádků překročí reject_value.
Pokud například REJECT_VALUE = 5 a REJECT_TYPE = hodnota, dotaz PolyBase SELECT selže po odmítnutí pěti řádků.
procento
REJECT_VALUE je procento, nikoli hodnota literálu. Dotaz PolyBase selže, když procento neúspěšných řádků překročí reject_value. Procento neúspěšných řádků se počítá v intervalech.
REJECT_VALUE = reject_value
Určuje hodnotu nebo procento řádků, které lze odmítnout před selháním dotazu.
Pro REJECT_TYPE = hodnota musí být reject_value celé číslo od 0 do 2 147 483 647.
Pro REJECT_TYPE = procento musí být reject_value plovoucí mezi 0 a 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Tento atribut se vyžaduje, když zadáte REJECT_TYPE = procento. Určuje počet řádků, které se mají pokusit načíst, než PolyBase přepočítá procento odmítnutých řádků.
Parametr reject_sample_value musí být celé číslo od 0 do 2 147 483 647.
Pokud například REJECT_SAMPLE_VALUE = 1000, PolyBase vypočítá procento neúspěšných řádků po pokusu o import 1 000 řádků z externího datového souboru. Pokud je procento neúspěšných řádků menší než reject_value, PolyBase se pokusí načíst dalších 1 000 řádků. Po pokusu o import všech dalších 1 000 řádků pokračuje v přepočtu procenta neúspěšných řádků.
Poznámka
Vzhledem k tomu, že PolyBase vypočítá procento neúspěšných řádků v intervalech, skutečné procento neúspěšných řádků může překročit reject_value.
Příklad:
Tento příklad ukazuje, jak tři možnosti ODMÍTNUTÍ vzájemně spolupracují. Pokud například REJECT_TYPE = procento, REJECT_VALUE = 30 a REJECT_SAMPLE_VALUE = 100, může dojít k následujícímu scénáři:
- PolyBase se pokusí načíst prvních 100 řádků; 25 neúspěšných a 75 úspěšných.
- Procento neúspěšných řádků se vypočítá jako 25%, což je menší než hodnota odmítnutí 30%. Výsledkem je, že PolyBase bude pokračovat v načítání dat z externího zdroje dat.
- PolyBase se pokusí načíst dalších 100 řádků; tentokrát proběhne úspěšně 25 řádků a nezdaří se 75 řádků.
- Procento neúspěšných řádků se přepočítá jako 50%. Procento neúspěšných řádků překročilo hodnotu 30% odmítnutí.
- Dotaz PolyBase selže s 50% odmítnutými řádky po pokusu o vrácení prvních 200 řádků. Všimněte si, že před zjištěním prahové hodnoty odmítnutí dotazu PolyBase byly vráceny odpovídající řádky.
Dovolení
Vyžaduje tato uživatelská oprávnění:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
Upozorňujeme, že přihlášení, které vytvoří externí zdroj dat, musí mít oprávnění ke čtení a zápisu do externího zdroje dat umístěného v Hadoopu nebo Azure Blob Storage.
Důležitý
Oprávnění ALTER ANY EXTERNAL DATA SOURCE uděluje každému objektu objektu externího zdroje dat možnost vytvářet a upravovat všechny objekty externího zdroje dat, a proto také umožňuje přístup ke všem přihlašovacím údajům v databázi s vymezeným oborem databáze. Toto oprávnění musí být považováno za vysoce privilegované, a proto musí být uděleno pouze důvěryhodným objektům zabezpečení v systému.
Zpracování chyb
Při provádění příkazu CREATE EXTERNAL TABLE se PolyBase pokusí připojit k externímu zdroji dat. Pokud se pokus o připojení nezdaří, příkaz selže a externí tabulka se nevytvořila. Selhání příkazu může trvat minutu nebo déle, protože PolyBase připojení opakuje, než dotaz nakonec selže.
Poznámky
Ve scénářích ad hoc dotazů, například SELECT FROM EXTERNAL TABLE, polyBase ukládá řádky načtené z externího zdroje dat do dočasné tabulky. Po dokončení dotazu PolyBase odebere a odstraní dočasnou tabulku. V tabulkách SQL se neukládají žádná trvalá data.
Naproti tomu ve scénáři importu, například SELECT INTO FROM EXTERNAL TABLE, PolyBase ukládá řádky načtené z externího zdroje dat jako trvalá data v tabulce SQL. Nová tabulka se vytvoří během provádění dotazu, když PolyBase načte externí data.
PolyBase může do Hadoopu nasdílet některé výpočty dotazů, aby se zlepšil výkon dotazů. Tato akce se nazývá predikát pushdown. Chcete-li jej povolit, zadejte možnost umístění Správce prostředků Hadoop v VYTVOŘIT EXTERNÍ ZDROJ DAT.
Můžete vytvořit mnoho externích tabulek, které odkazují na stejné nebo různé externí zdroje dat.
Omezení a omezení
Vzhledem k tomu, že data pro externí tabulku nejsou pod přímým řízením správy zařízení, je možné je kdykoli změnit nebo odebrat externím procesem. Výsledkem je, že výsledky dotazů vůči externí tabulce nemusí být deterministické. Stejný dotaz může při každém spuštění v externí tabulce vrátit různé výsledky. Podobně může dotaz selhat, pokud se externí data přesunou nebo odeberou.
Můžete vytvořit několik externích tabulek, které odkazují na různé externí zdroje dat. Pokud současně spouštíte dotazy na různé zdroje dat Hadoop, musí každý zdroj Hadoopu používat stejné nastavení konfigurace serveru hadoop. Nemůžete například současně spustit dotaz na cluster Cloudera Hadoop a cluster Hortonworks Hadoop, protože používají různá nastavení konfigurace. Informace o nastavení konfigurace a podporovaných kombinacích najdete v tématu Konfigurace připojení PolyBase.
V externích tabulkách jsou povoleny pouze tyto příkazy DDL (Data Definition Language):
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Konstrukty a operace nejsou podporovány:
- Výchozí omezení pro sloupce externí tabulky
- Operace jazyka DML (Data Manipulat Language) odstranění, vložení a aktualizace
- dynamické maskování dat ve sloupcích externí tabulky
Omezení dotazů
PolyBase může při spouštění 32 souběžných dotazů PolyBase využívat maximálně 33 tisíc souborů na složku. Toto maximální číslo zahrnuje soubory i podsložky v každé složce HDFS. Pokud je stupeň souběžnosti menší než 32, může uživatel spouštět dotazy PolyBase na složky v HDFS, které obsahují více než 33k souborů. Doporučujeme zachovat krátké cesty k externím souborům a používat maximálně 30 tisíc souborů na složku HDFS. Pokud se odkazuje na příliš mnoho souborů, může dojít k výjimce prostředí Java Virtual Machine (JVM) mimo paměť.
Omezení šířky tabulky
PolyBase v SQL Serveru 2016 má limit šířky řádku 32 kB na základě maximální velikosti jednoho platného řádku podle definice tabulky. Pokud je součet schématu sloupce větší než 32 kB, PolyBase nemůže dotazovat data.
V Azure Synapse Analytics se toto omezení zvýšilo na 1 MB.
Omezení datových typů
V externích tabulkách PolyBase nelze použít následující datové typy:
geographygeometryhierarchyidimagetextnTextxml- Libovolný typ definovaný uživatelem
Zamykání
Sdílený zámek objektu SCHEMARESOLUTION.
Bezpečnost
Datové soubory pro externí tabulku jsou uložené v Hadoopu nebo Azure Blob Storage. Tyto datové soubory se vytvářejí a spravují vlastními procesy. Zodpovídáte za správu zabezpečení externích dat.
Příklady
A. Spojení dat HDFS s daty systému analytických platforem
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Import dat řádků z HDFS do distribuované tabulky systému analytických platforem
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Import dat řádků z HDFS do replikované tabulky systému analytických platforem
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Další kroky
Další informace o externích tabulkách v Systému analytických platforem najdete v následujících článcích:
- VYTVOŘENÍ EXTERNÍHO ZDROJE DAT
- VYTVOŘIT FORMÁT EXTERNÍHO SOUBORU
- CREATE EXTERNAL TABLE AS SELECT
- CREATE TABLE AS SELECT (Azure Synapse Analytics)
* Azure SQL Managed Instance *
Azure Synapse
analýzy
Přehled: Azure SQL Managed Instance
Vytvoří tabulku externích dat ve službě Azure SQL Managed Instance. Úplné informace najdete v tématu Virtualizace dat pomocí služby Azure SQL Managed Instance.
Virtualizace dat ve službě Azure SQL Managed Instance poskytuje přístup k externím datům v různých formátech souborů ve službě Azure Data Lake Storage Gen2 nebo Azure Blob Storage a dotazování pomocí příkazů T-SQL, a to i kombinování dat s místně uloženými relačními daty pomocí spojení.
Viz také CREATE EXTERNAL DATA SOURCE a DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Název tabulky, který se má vytvořit, je jedna až třídílná. U externí tabulky platí, že pouze metadata tabulky spolu se základními statistikami o souboru nebo složce, na které se odkazuje ve službě Azure Data Lake nebo Azure Blob Storage. Při vytváření externích tabulek se nepřesouvají ani neukládají žádná skutečná data.
Důležitý
Pokud ovladač externího zdroje dat podporuje název třídílné části, důrazně doporučujeme zadat název třídílné části.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE podporuje možnost konfigurovat název sloupce, datový typ, hodnotu nullability a kolaci. U externích tabulek nemůžete použít VÝCHOZÍ OMEZENÍ.
Definice sloupců, včetně datových typů a počtu sloupců, musí odpovídat datům v externích souborech. Pokud dojde k neshodě, řádky souboru budou při dotazování na skutečná data odmítnuty.
LOCATION = 'folder_or_filepath'
Určuje složku nebo cestu k souboru a název souboru pro skutečná data ve službě Azure Data Lake nebo Azure Blob Storage. Umístění začíná z kořenové složky. Kořenová složka je umístění dat zadané v externím zdroji dat.
CREATE EXTERNAL TABLE cestu a složku nevytvoří.
Pokud zadáte umístění jako složku, dotaz ze spravované instance Azure SQL, která vybere z externí tabulky, načte soubory ze složky, ale ne ze všech jejích podsložek.
Spravovaná instance Azure SQL nemůže najít soubory v podsložkách nebo skrytých složkách. Také nevrací soubory, pro které název souboru začíná podtržením (_) nebo tečkou (.).
V následujícím příkladu obrázku, pokud LOCATION='/webdata/', dotaz vrátí řádky z mydata.txt. Nevrátí mydata2.txt, protože je v podsložce, nevrátí mydata3.txt, protože je ve skryté složce, a nevrací _hidden.txt, protože se jedná o skrytý soubor.
DATA_SOURCE = external_data_source_name
Určuje název externího zdroje dat, který obsahuje umístění externích dat. Toto umístění je v Azure Data Lake. Chcete-li vytvořit externí zdroj dat, použijte VYTVOŘIT EXTERNÍ ZDROJ DAT.
FILE_FORMAT = external_file_format_name
Určuje název objektu formátu externího souboru, který ukládá typ souboru a metodu komprese externích dat. Chcete-li vytvořit formát externího souboru, použijte CREATE EXTERNAL FILE FORMAT.
Dovolení
Vyžaduje tato uživatelská oprávnění:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Poznámka
Oprávnění CONTROL DATABASE jsou nutná k vytvoření pouze HLAVNÍHO KLÍČE, PŘIHLAŠOVACÍCH ÚDAJŮ S OBOREM DATABÁZE a EXTERNÍHO ZDROJE DAT.
Upozorňujeme, že přihlášení, které vytvoří externí zdroj dat, musí mít oprávnění ke čtení a zápisu do externího zdroje dat umístěného v Hadoopu nebo Azure Blob Storage.
Důležitý
Oprávnění ALTER ANY EXTERNAL DATA SOURCE uděluje každému objektu objektu externího zdroje dat možnost vytvářet a upravovat všechny objekty externího zdroje dat, a proto také umožňuje přístup ke všem přihlašovacím údajům v databázi s vymezeným oborem databáze. Toto oprávnění musí být považováno za vysoce privilegované, a proto musí být uděleno pouze důvěryhodným objektům zabezpečení v systému.
Poznámky
Ve scénářích ad hoc dotazů, například SELECT FROM EXTERNAL TABLE, jsou řádky načtené z externího zdroje dat uloženy v dočasné tabulce. Po dokončení dotazu se řádky odeberou a dočasná tabulka se odstraní. V tabulkách SQL se neukládají žádná trvalá data.
Naproti tomu ve scénáři importu, například SELECT INTO FROM EXTERNAL TABLE, jsou řádky načtené z externího zdroje dat uloženy jako trvalá data v tabulce SQL. Nová tabulka se vytvoří během provádění dotazu při načtení externích dat.
V současné době je virtualizace dat se službou Azure SQL Managed Instance určená jen pro čtení.
Můžete vytvořit mnoho externích tabulek, které odkazují na stejné nebo různé externí zdroje dat.
Omezení a omezení
Vzhledem k tomu, že data pro externí tabulku nejsou pod přímým řízením správy spravované instance Azure SQL, je možné je kdykoli změnit nebo odebrat externím procesem. Výsledkem je, že výsledky dotazů vůči externí tabulce nemusí být deterministické. Stejný dotaz může při každém spuštění v externí tabulce vrátit různé výsledky. Podobně může dotaz selhat, pokud se externí data přesunou nebo odeberou.
Můžete vytvořit několik externích tabulek, které odkazují na různé externí zdroje dat.
V externích tabulkách jsou povoleny pouze tyto příkazy DDL (Data Definition Language):
- CREATE TABLE and DROP TABLE
- CREATE STATISTICS and DROP STATISTICS
- CREATE VIEW and DROP VIEW
Konstrukty a operace nejsou podporovány:
- Výchozí omezení pro sloupce externí tabulky
- Operace jazyka DML (Data Manipulat Language) odstranění, vložení a aktualizace
Omezení šířky tabulky
Limit šířky řádku 1 MB je založený na maximální velikosti jednoho platného řádku podle definice tabulky. Pokud je součet schématu sloupce větší než 1 MB, dotazy virtualizace dat selžou.
Omezení datových typů
Následující datové typy nelze použít v externích tabulkách ve službě Azure SQL Managed Instance:
geographygeometryhierarchyidimagetextnTextxml- Libovolný typ definovaný uživatelem
Zamykání
Sdílený zámek objektu SCHEMARESOLUTION.
Příklady
A. Dotazování externích dat ze spravované instance Azure SQL pomocí externí tabulky
Další příklady najdete v tématu Vytvoření externího zdroje dat nebo se podívejte na Virtualizace dat pomocí služby Azure SQL Managed Instance.
Pokud neexistuje, vytvořte hlavní klíč databáze.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOVytvořte přihlašovací údaje s vymezeným oborem databáze pomocí tokenu SAS. Můžete také použít spravovanou identitu.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOVytvořte externí zdroj dat pomocí přihlašovacích údajů.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOVytvořte FORMÁT EXTERNÍHO SOUBORU a EXTERNÍ TABULKU, abyste se dotazovali na data, jako by šlo o místní tabulku.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Další kroky
Další informace o externích tabulkách a souvisejících konceptech najdete v následujících článcích:
- virtualizace dat s využitím služby Azure SQL Managed Instance
- VYTVOŘENÍ EXTERNÍHO ZDROJE DAT
- VYTVOŘIT FORMÁT EXTERNÍHO SOUBORU
- CREATE EXTERNAL TABLE AS SELECT