Scénáře použití úložiště dotazů
platí pro:![]() SQL Server 2016 (13.x) a novější verze
SQL Server 2016 (13.x) a novější verze ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics (pouze vyhrazený fond SQL)
Azure Synapse Analytics (pouze vyhrazený fond SQL)![]() databázi SQL v Microsoft Fabric
databázi SQL v Microsoft Fabric
Úložiště dotazů je možné použít v široké sadě scénářů při sledování a zajištění předvídatelného výkonu úloh. Tady je několik příkladů, které můžete zvážit:
Rozpoznání a oprava dotazů s regresí výběru plánu
Identifikace a ladění dotazů s nejvyšším využitím prostředků
Testování A/B
Udržování stability výkonu během upgradu na novější SQL Server
Identifikace a zlepšení ad hoc úloh
Další informace o konfiguraci a správě pomocí úložiště dotazů najdete v tématu Monitorování výkonu pomocí úložiště dotazů.
Informace o zjišťování informací umožňujících akci a ladění výkonu pomocí úložiště dotazů najdete v tématu Ladění výkonu pomocí úložiště dotazů.
Informace o provozu úložiště dotazů ve službě Azure SQL Database najdete v tématu Provoz úložiště dotazů ve službě Azure SQL Database.
Určení a oprava dotazů s regresí voleb plánu
Během pravidelného provádění dotazů se optimalizátor dotazů může rozhodnout zvolit jiný plán, protože se změnily důležité vstupy: kardinalita dat se změnila, indexy byly vytvořeny, změněny nebo vyřazeny, statistiky byly aktualizovány atd. Nový plán je obvykle lepší nebo přibližně stejný než plán použitý dříve. Existují však případy, kdy je nový plán výrazně horší – tato situace se označuje jako regrese změny volby plánu. Před zavedením úložiště dotazů bylo těžké tuto chybu identifikovat a napravit, protože SQL Server neposkytoval integrované úložiště dat, kde by uživatelé mohli sledovat plány provádění používané v průběhu času.
S úložištěm dotazů můžete rychle:
Identifikujte všechny dotazy, u kterých došlo ke snížení výkonu metrik, v období zájmu (poslední hodina, den, týden atd.). K urychlení analýzy použijte v SQL Server Management Studio regredované dotazy .
Mezi zhoršenými dotazy je snadné najít ty, které měly více plánů a zhoršily se kvůli špatné volbě plánu. Pomocí podokna Souhrn plánu v Regresní dotazy můžete vizualizovat všechny plány pro regresní dotazy a jejich výkon v průběhu času.
Použijte předchozí plán z historie, pokud se ukáže jako lepší. Pomocí tlačítka Vynutit plán v regresované dotazy vynutit vybraný plán pro dotaz.
 využití úložiště dotazů 1
využití úložiště dotazů 1
Podrobný popis scénáře najdete na blogu Query Store: Záznamník letových dat pro vaši databázi.
Identifikace a ladění dotazů s nejvyšším využitím prostředků
I když vaše úloha může generovat tisíce dotazů, obvykle jenom několik z nich ve skutečnosti využívá většinu systémových prostředků a proto vyžaduje vaši pozornost. Mezi dotazy s nejvyšším využitím prostředků obvykle najdete dotazy, které se zhoršily, nebo dotazy, které lze vylepšit dalším laděním.
Nejjednodušší způsob, jak začít zkoumat, je otevřít dotazy s nejvyšší spotřebou prostředků v Management Studiu. Uživatelské rozhraní je rozděleno do tří podoken: Histogram představující dotazy s nejvyšším využitím prostředků (vlevo), souhrn plánu pro vybraný dotaz (vpravo) a plán vizuálních dotazů pro vybraný plán (dole). Vyberte Konfigurovat, abyste mohli řídit, kolik dotazů chcete analyzovat, a časový interval zájmu. Kromě toho si můžete vybrat mezi různými dimenzemi spotřeby prostředků (doba trvání, procesor, paměť, V/V, počet spuštění) a směrný plán (průměr, minimum, maximum, celkový počet, směrodatná odchylka).

Prohlédněte si souhrn plánu napravo, abyste analyzovali historii provádění a dozvěděli se o různých plánech a jejich statistikách modulu runtime. V dolním podokně můžete prozkoumat různé plány nebo je vizuálně porovnat, vykreslit vedle sebe (použijte tlačítko Porovnat).
Když identifikujete dotaz s neoptimálním výkonem, akce závisí na povaze problému:
Pokud byl dotaz proveden s více plány a poslední plán je výrazně horší než předchozí plán, můžete pomocí mechanismu vynucení plánu zajistit, aby SQL Server používal optimální plán pro budoucí spuštění.
Zkontrolujte, jestli optimalizátor navrhuje chybějící indexy v plánu XML. Pokud ano, vytvořte chybějící index a pomocí úložiště dotazů vyhodnoťte výkon dotazů po vytvoření indexu.
Ujistěte se, že jsou statistiky up-to-date pro podkladové tabulky používané dotazem.
Ujistěte se, že jsou indexy používané dotazem defragmentovány.
Zvažte přepsání nákladného dotazu. Využijte například parametrizaci dotazů a snižte využití dynamického SQL. Implementujte optimální logiku při čtení dat (použijte filtrování dat na straně databáze, ne na straně aplikace).
Testování A/B
Pomocí úložiště dotazů můžete porovnat výkon úloh před a po změně aplikace.
Následující seznam obsahuje několik příkladů, ve kterých můžete pomocí úložiště dotazů vyhodnotit dopad změny prostředí nebo aplikace na výkon úloh:
Zavádíme novou verzi aplikace.
Přidání nového hardwaru na server
Vytváření chybějících indexů v tabulkách odkazovaných nákladovými dotazy
Použití zásad filtrování pro zabezpečení na úrovni řádků Další informace najdete v tématu Optimalizace zabezpečení na úrovni řádků pomocí úložiště dotazů.
Přidání dočasné verze systému do tabulek, které jsou často upraveny aplikacemi OLTP.
V některém z těchto scénářů platí následující pracovní postup:
Spusťte úlohu s úložištěm dotazů před plánovanou změnou a vygenerujte směrný plán výkonu.
Použijte změnu aplikace v řízeném okamžiku v čase.
Pokračujte v provozu úlohy dostatečně dlouho, aby se po změně vygenerovala image výkonu systému.
Porovnejte výsledky z #1 a č. 3.
Otevřete Overall Database Consumption, k určení dopadu na celou databázi.
Otevřete dotazy s nejvyšším využitím prostředků (nebo spusťte vlastní analýzu pomocí Transact-SQL) a analyzujte dopad změny na nejdůležitější dotazy.
Rozhodněte se, jestli chcete změnu zachovat nebo provést vrácení zpět v případě, že je nový výkon nepřijatelný.
Následující obrázek ukazuje analýzu úložiště dotazů (krok 4) v případě chybějícího vytvoření indexu. Otevřete podokno Souhrn dotazů, které nejvíce zatěžují zdroje / souhrn plánu, abyste získali toto zobrazení pro dotaz, který by měl být ovlivněn vytvořením indexu:
 analýza používání úložiště dotazů 3
analýza používání úložiště dotazů 3
Kromě toho můžete porovnat plány před a po vytvoření indexu jejich souběžným vykreslením. (Možnost Porovnat plány vybraného dotazu v samostatném okně, která je označena červeným čtverečkem na panelu nástrojů.)

Plán před vytvořením indexu (plan_id = 1, výše) neobsahuje nápovědu k indexu a můžete zkontrolovat, zda clusterovaný index scan byl nejdražším operátorem v dotazu (červený obdélník).
Plán po vytvoření chybějícího indexu (plan_id = 15, níže) má nyní vyhledávání pomocí neklastrovaného indexu, což snižuje celkové náklady na dotaz a zlepšuje jeho výkon (zelený obdélník).
Na základě analýzy byste index pravděpodobně zachovali, protože byl vylepšen výkon dotazů.
Udržování stability výkonu během upgradu na novější SQL Server
Před SQL Serverem 2014 (12.x) byli uživatelé vystaveni riziku regrese výkonu během upgradu na nejnovější verzi platformy. Důvodem byla skutečnost, že nejnovější verze Optimalizátoru dotazů se stala aktivní okamžitě po instalaci nových bitů.
Počínaje SQL Serverem 2014 (12.x) jsou všechny změny optimalizátoru dotazů spojeny s nejnovější úrovní kompatibility databáze , takže plány se nezmění přímo při upgradu, ale teprve když uživatel změní COMPATIBILITY_LEVEL na tu nejnovější. Tato funkce v kombinaci s úložištěm dotazů poskytuje skvělou úroveň kontroly nad výkonem dotazů v procesu upgradu. Doporučený pracovní postup upgradu se zobrazuje na následujícím obrázku:
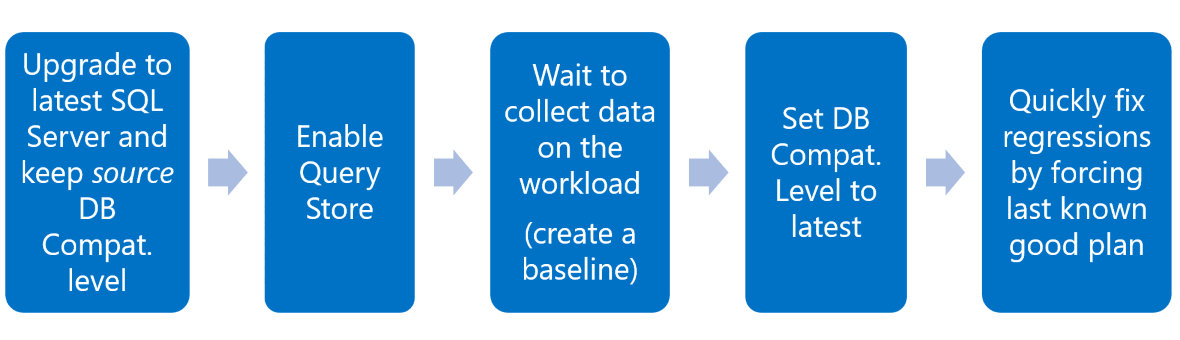 úložiště dotazů a využití 5
úložiště dotazů a využití 5
Upgradujte SQL Server beze změny úrovně kompatibility databáze. Nezpřístupňuje nejnovější změny optimalizátoru dotazů, ale stále poskytuje novější funkce SQL Serveru, včetně úložiště dotazů.
Povolte úložiště dotazů. Další informace najdete v tématu Udržovat úložiště dotazů upravené na vaše úlohy.
Povolte, aby Query Store zachytával dotazy a plány a stanovil výkonovou základní linii s úrovní kompatibility databáze zdrojové či předchozí. Zůstaňte v tomto kroku dostatečně dlouho, abyste zachytili všechny plány a získali stabilní výchozí hodnotu. To může být doba trvání běžného obchodního cyklu pro produkční úlohu.
Přechod na nejnovější úroveň kompatibility databáze: Získejte úlohy vystavené nejnovějšímu optimalizátoru dotazů, abyste mohli potenciálně vytvářet nové plány.
Úložiště dotazů používejte pro opravy analýzy a regrese: nová vylepšení optimalizátoru dotazů by měla vytvářet lepší plány. Úložiště dotazů poskytne snadný způsob, jak identifikovat regrese ve výběru plánu a opravit je pomocí mechanismu pro vynucení plánu. Počínaje SQL Serverem 2017 (14.x) při použití funkce automatická oprava plánu se tento krok stane automatickým.
a. V případech, kdy existují regrese, vynuťte dříve známý dobrý plán v úložišti dotazů.
b. Pokud existují plány dotazů, které se nepodaří vynutit, nebo pokud je výkon stále nedostatečný, zvažte vrácení úrovně kompatibility databáze na předchozí nastavení a pak kontaktujte zákaznickou podporu Microsoftu.
Spropitné
Pomocí úlohy Upgrade Database v SQL Server Management Studio upgradujte úroveň kompatibility databáze . Podrobnosti najdete v části Aktualizace databází s použitím Pomocníka pro ladění dotazů.
Identifikace a zlepšení ad hoc úloh
Některé úlohy nemají dominantní dotazy, které můžete vyladit, aby se zlepšil celkový výkon aplikace. Tyto úlohy jsou obvykle charakterizovány relativně velkým počtem různých dotazů, z nichž každý využívá část systémových prostředků. Jsou-li jedinečné, tyto dotazy se provádějí velmi zřídka (obvykle pouze jednou, tedy ad hoc), takže jejich spotřeba během jejich provádění není kritická. Na druhou stranu vzhledem k tomu, že aplikace neustále generuje čisté nové dotazy, velká část systémových prostředků se stráví kompilací dotazů, což není optimální. To není ideální situace pro úložiště dotazů vzhledem k tomu, že velký počet dotazů a plánů zahltí prostor, který jste si rezervovali, což znamená, že úložiště dotazů pravděpodobně skončí v režimu jen pro čtení velmi rychle. Pokud jste aktivovali zásady čištění na základě velikosti (důrazně doporučeno pro udržení úložiště dotazů vždy v provozu), proces na pozadí bude většinu času čistit struktury úložiště dotazů, což také spotřebovává značné systémové prostředky.
Zobrazení Dotazy s nejvyšším využitím prostředků vám poskytne první indikaci o ad hoc povaze vaší pracovní zátěže:

Pomocí metriky Počet spuštění analyzujte, jestli jsou vaše nejčastější dotazy ad hoc (to vyžaduje spuštění úložiště dotazů s QUERY_CAPTURE_MODE = ALL). Z výše uvedeného diagramu vidíte, že 90% dotazů s nejvyšším využitím prostředků se spustí pouze jednou.
Vy můžete případně spustit skript Transact-SQL, který zjistí celkový počet dotazových textů, dotazů a plánů v systému, abyste mohli určit, jak moc se liší, porovnáním query_hash a query_plan_hash.
--Do cardinality analysis when suspect on ad hoc workloads
SELECT COUNT(*) AS CountQueryTextRows FROM sys.query_store_query_text;
SELECT COUNT(*) AS CountQueryRows FROM sys.query_store_query;
SELECT COUNT(DISTINCT query_hash) AS CountDifferentQueryRows FROM sys.query_store_query;
SELECT COUNT(*) AS CountPlanRows FROM sys.query_store_plan;
SELECT COUNT(DISTINCT query_plan_hash) AS CountDifferentPlanRows FROM sys.query_store_plan;
To je jeden z potenciálních výsledků, které můžete získat v případě úloh s ad hoc dotazy:

Výsledek dotazu ukazuje, že i přes velký počet dotazů a plánů v Úložišti dotazů se jejich hodnoty query_hash a query_plan_hash ve skutečnosti neliší. Poměr mezi jedinečnými texty dotazů a jedinečnými hodnotami hash dotazů, které jsou mnohem větší než 1, je indikací, že úloha je vhodným kandidátem pro parametrizaci, protože jediným rozdílem mezi dotazy je literální konstanta (parametr) poskytovaná jako součást textu dotazu.
K této situaci obvykle dochází v případě, že vaše aplikace generuje dotazy (místo vyvolání uložených procedur nebo parametrizovaných dotazů) nebo pokud spoléhá na architektury mapování relačních objektů, které ve výchozím nastavení generují dotazy.
Pokud máte kontrolu nad kódem aplikace, můžete zvážit přepsání vrstvy přístupu k datům za účelem využití uložených procedur nebo parametrizovaných dotazů. Tato situace však může být také výrazně vylepšena bez změn aplikace vynucením parametrizace dotazu pro celou databázi (všechny dotazy) nebo pro jednotlivé šablony dotazů se stejnými query_hash.
Přístup s jednotlivými šablonami dotazů vyžaduje vytvoření průvodce plánem:
--Apply plan guide for the selected query template
DECLARE @stmt nvarchar(max);
DECLARE @params nvarchar(max);
EXEC sp_get_query_template
N'<your query text goes here>',
@stmt OUTPUT,
@params OUTPUT;
EXEC sp_create_plan_guide
N'TemplateGuide1',
@stmt,
N'TEMPLATE',
NULL,
@params,
N'OPTION (PARAMETERIZATION FORCED)';
Řešení s průvodci plánováním je přesnější, ale vyžaduje více práce.
Pokud jsou všechny dotazy (nebo většina z nich) kandidáty pro automatické parametrizace, zvažte konfiguraci PARAMETERIZATION = FORCED pro celou databázi. Další informace naleznete v tématu Pokyny pro použití vynucené parametrizace.
--Apply forced parameterization for entire database
ALTER DATABASE <database name> SET PARAMETERIZATION FORCED;
Po použití některého z těchto kroků dotazy s nejvyšší spotřebou prostředků vám ukážou jiný obrázek vaší pracovní zátěže.
 úložiště dotazů a využití 8
úložiště dotazů a využití 8
V některých případech může vaše aplikace generovat spoustu různých dotazů, které nejsou vhodnými kandidáty pro automatické parametrizace. V takovém případě uvidíte v systému velký počet dotazů, ale poměr mezi jedinečnými dotazy a jedinečnými query_hash je pravděpodobně blízko 1.
V takovém případě možná budete chtít povolit možnost Optimalizovat pro ad hoc úlohy serveru, aby se zabránilo plýtvání mezipamětí u dotazů, které se pravděpodobně znovu nespustí. Pokud chcete zabránit zachycení těchto dotazů v úložišti dotazů, nastavte QUERY_CAPTURE_MODE na AUTO.
EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE
GO
EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1'
GO
RECONFIGURE WITH OVERRIDE
GO
ALTER DATABASE [QueryStoreTest] SET QUERY_STORE CLEAR;
ALTER DATABASE [QueryStoreTest] SET QUERY_STORE = ON
(OPERATION_MODE = READ_WRITE, QUERY_CAPTURE_MODE = AUTO);