Columnstore indexes: Overview
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW) ![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
Columnstore indexes are the standard for storing and querying large data warehousing fact tables. This index uses column-based data storage and query processing to achieve gains up to 10 times the query performance in your data warehouse over traditional row-oriented storage. You can also achieve gains up to 10 times the data compression over the uncompressed data size. Beginning with SQL Server 2016 (13.x) SP1, columnstore indexes enable operational analytics: the ability to run performant real-time analytics on a transactional workload.
Learn about a related scenario:
- Columnstore indexes in data warehousing
- Get started with columnstore for real-time operational analytics
What is a columnstore index?
A columnstore index is a technology for storing, retrieving, and managing data by using a columnar data format, called a columnstore.
Key terms and concepts
The following key terms and concepts are associated with columnstore indexes.
Columnstore
A columnstore is data that's logically organized as a table with rows and columns, and physically stored in a column-wise data format.
Rowstore
A rowstore is data that's logically organized as a table with rows and columns, and physically stored in a row-wise data format. This format is the traditional way to store relational table data. In SQL Server, rowstore refers to a table where the underlying data storage format is a heap, a clustered index, or a memory-optimized table.
Note
In discussions about columnstore indexes, the terms rowstore and columnstore are used to emphasize the format for the data storage.
Rowgroup
A rowgroup is a group of rows that are compressed into columnstore format at the same time. A rowgroup usually contains the maximum number of rows per rowgroup, which is 1,048,576 rows.
For high performance and high compression rates, the columnstore index slices the table into rowgroups, and then compresses each rowgroup in a column-wise manner. The number of rows in the rowgroup must be large enough to improve compression rates, and small enough to benefit from in-memory operations.
A rowgroup from where all data has been deleted transitions from COMPRESSED into TOMBSTONE state, and is later removed by a background process named the tuple-mover. For more information about rowgroup statuses, see sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Tip
Having too many small rowgroups decreases the columnstore index quality. Until SQL Server 2017 (14.x), a reorganize operation is required to merge smaller COMPRESSED rowgroups, following an internal threshold policy that determines how to remove deleted rows and combine the compressed rowgroups.
Starting with SQL Server 2019 (15.x), a background merge task also works to merge COMPRESSED rowgroups from where a large number of rows has been deleted.
After merging smaller rowgroups, the index quality should be improved.
Note
Starting with SQL Server 2019 (15.x), Azure SQL Database, Azure SQL Managed Instance, and dedicated SQL pools in Azure Synapse Analytics, the tuple-mover is helped by a background merge task that automatically compresses smaller OPEN delta rowgroups that have existed for some time as determined by an internal threshold, or merges COMPRESSED rowgroups from where a large number of rows has been deleted. This improves the columnstore index quality over time.
Column segment
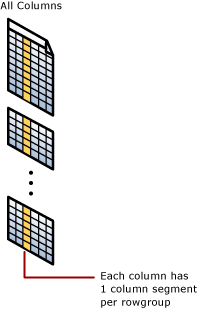
A column segment is a column of data from within the rowgroup.
- Each rowgroup contains one column segment for every column in the table.
- Each column segment is compressed together and stored on physical media.
- There's metadata with each segment to allow for fast elimination of segments without reading them.
Clustered columnstore index
A clustered columnstore index is the physical storage for the entire table.
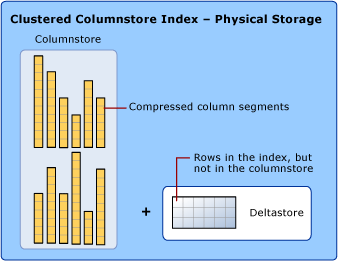
To reduce fragmentation of the column segments and improve performance, the columnstore index might store some data temporarily into a clustered index called a deltastore and a B-tree list of IDs for deleted rows. The deltastore operations are handled behind the scenes. To return the correct query results, the clustered columnstore index combines query results from both the columnstore and the deltastore.
Note
Documentation uses the term B-tree generally in reference to indexes. In rowstore indexes, the Database Engine implements a B+ tree. This does not apply to columnstore indexes or indexes on memory-optimized tables. For more information, see the SQL Server and Azure SQL index architecture and design guide.
Delta rowgroup
A delta rowgroup is a clustered B-tree index that's used only with columnstore indexes. It improves columnstore compression and performance by storing rows until the number of rows reaches a threshold (1,048,576 rows) and are then moved into the columnstore.
When a delta rowgroup reaches the maximum number of rows, it transitions from an OPEN to CLOSED state. A background process named the tuple-mover checks for closed row groups. If the process finds a closed rowgroup, it compresses the delta rowgroup and stores it into the columnstore as a COMPRESSED rowgroup.
When a delta rowgroup has been compressed, the existing delta rowgroup transitions into TOMBSTONE state to be removed later by the tuple-mover when there's no reference to it.
For more information about rowgroup statuses, see sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Note
Starting with SQL Server 2019 (15.x), the tuple-mover is helped by a background merge task that automatically compresses smaller OPEN delta rowgroups that have existed for some time as determined by an internal threshold, or merges COMPRESSED rowgroups from where a large number of rows has been deleted. This improves the columnstore index quality over time.
Deltastore
A columnstore index can have more than one delta rowgroup. All of the delta rowgroups are collectively called the deltastore.
During a large bulk load, most of the rows go directly to the columnstore without passing through the deltastore. Some rows at the end of the bulk load might be too few in number to meet the minimum size of a rowgroup, which is 102,400 rows. As a result, the final rows go to the deltastore instead of the columnstore. For small bulk loads with less than 102,400 rows, all of the rows go directly to the deltastore.
Nonclustered columnstore index
A nonclustered columnstore index and a clustered columnstore index function the same. The difference is that a nonclustered index is a secondary index that's created on a rowstore table, but a clustered columnstore index is the primary storage for the entire table.
The nonclustered index contains a copy of part or all of the rows and columns in the underlying table. The index is defined as one or more columns of the table and has an optional condition that filters the rows.
A nonclustered columnstore index enables real-time operational analytics where the OLTP workload uses the underlying clustered index while analytics run concurrently on the columnstore index. For more information, see Get started with columnstore for real-time operational analytics.
Batch mode execution
Batch mode execution is a query processing method that's used to process multiple rows together. Batch mode execution is closely integrated with, and optimized around, the columnstore storage format. Batch mode execution is sometimes known as vector-based or vectorized execution. Queries on columnstore indexes use batch mode execution, which improves query performance typically by two to four times. For more information, see the Query processing architecture guide.
Why should I use a columnstore index?
A columnstore index can provide a very high level of data compression, typically by 10 times, to significantly reduce your data warehouse storage cost. For analytics, a columnstore index offers an order of magnitude better performance than a B-tree index. Columnstore indexes are the preferred data storage format for data warehousing and analytics workloads. Starting with SQL Server 2016 (13.x), you can use columnstore indexes for real-time analytics on your operational workload.
Reasons why columnstore indexes are so fast:
Columns store values from the same domain and commonly have similar values, which result in high compression rates. I/O bottlenecks in your system are minimized or eliminated, and memory footprint is reduced significantly.
High compression rates improve query performance by using a smaller in-memory footprint. In turn, query performance can improve because SQL Server can perform more query and data operations in memory.
Batch execution improves query performance, typically by two to four times, by processing multiple rows together.
Queries often select only a few columns from a table, which reduces total I/O from the physical media.
When should I use a columnstore index?
Recommended use cases:
Use a clustered columnstore index to store fact tables and large dimension tables for data warehousing workloads. This method improves query performance and data compression by up to 10 times. For more information, see Columnstore indexes for data warehousing.
Use a nonclustered columnstore index to perform analysis in real time on an OLTP workload. For more information, see Get started with columnstore for real-time operational analytics.
For more usage scenarios for columnstore indexes, see Choose the best columnstore index for your needs.
How do I choose between a rowstore index and a columnstore index?
Rowstore indexes perform best on queries that seek into the data, when searching for a particular value, or for queries on a small range of values. Use rowstore indexes with transactional workloads because they tend to require mostly table seeks instead of table scans.
Columnstore indexes give high performance gains for analytic queries that scan large amounts of data, especially on large tables. Use columnstore indexes on data warehousing and analytics workloads, especially on fact tables, because they tend to require full table scans rather than table seeks.
Ordered clustered columnstore indexes improve performance for queries based on ordered column predicates. Ordered columnstore indexes can improve row-group elimination, which can deliver performance improvements by skipping row groups altogether. For more information, see Performance tuning with ordered clustered columnstore indexes. For ordered columnstore index availability, see Ordered column index availability.
Can I combine rowstore and columnstore on the same table?
Yes. Beginning with SQL Server 2016 (13.x), you can create an updatable nonclustered columnstore index on a rowstore table. The columnstore index stores a copy of the selected columns, so you need extra space for this data, but the selected data is compressed on average 10 times. You can run analytics on the columnstore index and transactions on the rowstore index at the same time. The columnstore is updated when data changes in the rowstore table, so both indexes work against the same data.
Beginning with SQL Server 2016 (13.x), you can have one or more nonclustered rowstore indexes on a columnstore index and perform efficient table seeks on the underlying columnstore. Other options become available too. For example, you can enforce a primary key constraint by using a UNIQUE constraint on the rowstore table. Because a nonunique value fails to insert into the rowstore table, SQL Server can't insert the value into the columnstore.
Ordered columnstore indexes
By enabling efficient segment elimination, ordered clustered columnstore indexes (CCI) provide much faster performance by skipping large amounts of ordered data that don't match the query predicate. Loading data into an ordered CCI table can take longer than a non-ordered CCI table because of the data sorting operation, however queries can run faster afterwards with ordered CCI.
- For more information on performance tuning data warehousing workloads in the SQL Database Engine with ordered clustered columnstore indexes, see Performance tuning with ordered clustered columnstore indexes.
- For more information on when to use which type of columnstore index, see Choose the best columnstore index for your needs.
Ordered columnstore index availability
First introduced with ![]() SQL Server 2022 (16.x), ordered columnstore indexes are available in the following platforms.
SQL Server 2022 (16.x), ordered columnstore indexes are available in the following platforms.
| Platform | Ordered clustered columnstore indexes | Ordered nonclustered columnstore indexes |
|---|---|---|
| Azure SQL Database | Yes | Yes |
| SQL database in Microsoft Fabric | Yes* | Yes |
| SQL Server 2022 (16.x) | Yes | No |
| Azure SQL Managed Instance | Yes | Yes |
| Dedicated SQL pool in Azure Synapse Analytics | Yes | No |
* In Fabric SQL database, tables with clustered columnstore indexes are not mirrored to Fabric OneLake.
Metadata
All of the columns in a columnstore index are stored in the metadata as included columns. The columnstore index doesn't have key columns.
Related tasks
All relational tables, unless you specify them as a clustered columnstore index, use rowstore as the underlying data format. CREATE TABLE creates a rowstore table unless you specify the WITH CLUSTERED COLUMNSTORE INDEX option.
When you create a table with the CREATE TABLE statement, you can create the table as a columnstore by specifying the WITH CLUSTERED COLUMNSTORE INDEX option. If you already have a rowstore table and want to convert it to a columnstore, you can use the CREATE COLUMNSTORE INDEX statement.
| Task | Reference articles | Notes |
|---|---|---|
| Create a table as a columnstore. | CREATE TABLE (Transact-SQL) | Beginning with SQL Server 2016 (13.x), you can create the table as a clustered columnstore index. You don't have to first create a rowstore table and then convert it to columnstore. |
| Create a memory-optimized table with a columnstore index. | CREATE TABLE (Transact-SQL) | Beginning with SQL Server 2016 (13.x), you can create a memory-optimized table with a columnstore index. The columnstore index can also be added after the table is created by using the ALTER TABLE ADD INDEX syntax. |
| Convert a rowstore table to a columnstore. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Convert an existing heap or B-tree to a columnstore. Examples show how to handle existing indexes and also the name of the index when performing this conversion. |
| Convert a columnstore table to a rowstore. | CREATE CLUSTERED INDEX (Transact-SQL) or Convert a columnstore table back to a rowstore heap | Usually this conversion isn't necessary, but there can be times when you need to convert. Examples show how to convert a columnstore to a heap or clustered index. |
| Create a columnstore index on a rowstore table. | CREATE COLUMNSTORE INDEX (Transact-SQL) | A rowstore table can have one columnstore index. Beginning with SQL Server 2016 (13.x), the columnstore index can have a filtered condition. Examples show the basic syntax. |
| Create performant indexes for operational analytics. | Get started with columnstore for real-time operational analytics | Describes how to create complementary columnstore and B-tree indexes, so that OLTP queries use B-tree indexes and analytics queries use columnstore indexes. |
| Create performant columnstore indexes for data warehousing. | Columnstore indexes for data warehousing | Describes how to use B-tree indexes on columnstore tables to create performant data warehousing queries. |
| Use a B-tree index to enforce a primary key constraint on a columnstore index. | Columnstore indexes for data warehousing | Shows how to combine B-tree and columnstore indexes to enforce primary key constraints on the columnstore index. |
| Drop a columnstore index. | DROP INDEX (Transact-SQL) | Dropping a columnstore index uses the standard DROP INDEX syntax that B-tree indexes use. Dropping a clustered columnstore index converts the columnstore table to a heap. |
| Delete a row from a columnstore index. | DELETE (Transact-SQL) | Use DELETE (Transact-SQL) to delete a row. columnstore row: SQL Server marks the row as logically deleted, but doesn't reclaim the physical storage for the row until the index is rebuilt. deltastore row: SQL Server logically and physically deletes the row. |
| Update a row in the columnstore index. | UPDATE (Transact-SQL) | Use UPDATE (Transact-SQL) to update a row. columnstore row: SQL Server marks the row as logically deleted and then inserts the updated row into the deltastore. deltastore row: SQL Server updates the row in the deltastore. |
| Load data into a columnstore index. | Columnstore indexes data loading | |
| Force all rows in the deltastore to go into the columnstore. | ALTER INDEX (Transact-SQL) ... REBUILDOptimize index maintenance to improve query performance and reduce resource consumption |
ALTER INDEX with the REBUILD option forces all rows to go into the columnstore. |
| Defragment a columnstore index. | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE defragments columnstore indexes online. |
| Merge tables with columnstore indexes. | MERGE (Transact-SQL) |
Related content
- What's new in columnstore indexes
- Columnstore indexes - Data loading guidance
- Columnstore indexes - Query performance
- Get started with Columnstore for real-time operational analytics
- Columnstore indexes in data warehousing
- Columnstore indexes defragmentation
- SQL Server and Azure SQL index architecture and design guide
- Columnstore index architecture
- CREATE COLUMNSTORE INDEX (Transact-SQL)