Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
platí pro:![]() SQL Server 2017 (14.x) a novější
SQL Server 2017 (14.x) a novější
Tento článek vysvětluje postup vytvoření skupiny dostupnosti AlwaysOn s jednou replikou na serveru s Windows a druhou replikou na serveru s Linuxem.
Důležitý
Skupiny dostupnosti SQL Serveru pro různé platformy, které zahrnují heterogenní repliky s kompletní podporou vysoké dostupnosti a zotavení po havárii, je k dispozici s DH2i DxEnterprise. Další informace naleznete v tématu skupiny dostupnosti SYSTÉMU SQL Server se smíšenými operačními systémy.
V následujícím videu najdete informace o skupinách dostupnosti napříč platformami s DH2i.
Tato konfigurace je multiplatformní, protože repliky jsou v různých operačních systémech. Tuto konfiguraci použijte pro migraci z jedné platformy na druhou nebo zotavení po havárii (DR). Tato konfigurace nepodporuje vysokou dostupnost.

Než budete pokračovat, měli byste být obeznámeni s instalací a konfigurací pro instance SQL Serveru ve Windows a Linuxu.
Scénář
V tomto scénáři jsou dva servery v různých operačních systémech. Windows Server 2022 s názvem WinSQLInstance hostuje primární repliku. Linuxový server s názvem LinuxSQLInstance hostí sekundární repliku.
Konfigurujte AG
Postup vytvoření AG je stejný jako postup vytvoření AG pro úlohy škálování čtení. Typ clustru skupiny dostupnosti je NONE, protože neexistuje žádný správce clusteru.
Pro skripty v tomto článku šikmé závorky < a > identifikují hodnoty, které musíte nahradit pro vaše prostředí. Samotné úhlové závorky se pro skripty nevyžadují.
Nainstalujte SQL Server 2022 (16.x) na Windows Server 2022, povolte skupiny dostupnosti Always On pomocí SQL Server Configuration Manager a nastavte ověřování ve smíšeném režimu.
Spropitné
Pokud toto řešení ověřujete v Azure, umístěte oba servery do stejné skupiny dostupnosti, abyste zajistili, že jsou v datovém centru oddělené.
Povolte skupiny dostupnosti
Pokyny najdete v tématu Povolení nebo zakázání funkce vysoké dostupnosti Always On.
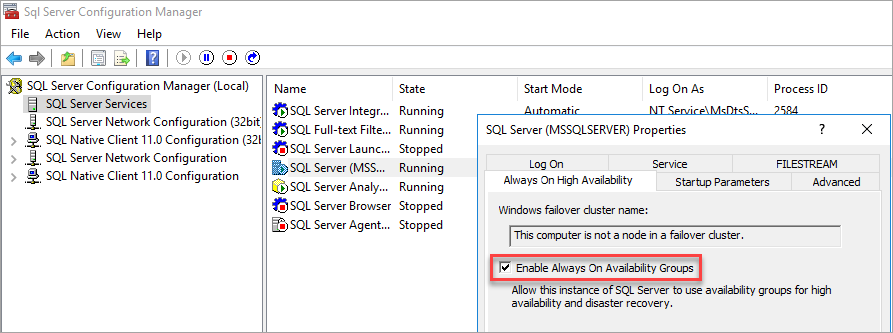
SQL Server Configuration Manager konstatuje, že počítač není uzel v clusteru s podporou převzetí služeb při selhání.
Po povolení skupin dostupnosti restartujte SQL Server.
Nastavení ověřování ve smíšeném režimu
Pokyny najdete v tématu Změna režimu ověřování serveru.
Nainstalujte SQL Server 2022 (16.x) v Linuxu. Pokyny najdete v tématu Pokyny k instalaci SQL Serveru v systému Linux. Povolte
hadrpomocí mssql-conf.Pokud chcete povolit
hadrprostřednictvím mssql-conf z příkazového řádku, spusťte následující příkaz:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Po povolení
hadrrestartujte instanci SQL Serveru:sudo systemctl restart mssql-server.serviceNakonfigurujte soubor
hostsna obou serverech nebo zaregistrujte názvy serverů v DNS.Otevřete porty brány firewall pro protokol TCP 1433 a 5022 v systémech Windows i Linux.
Na primární replice vytvořte přihlašovací jméno a heslo databáze.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOOpatrnost
Vaše heslo by mělo postupovat podle výchozích zásad hesel SQL Serveru . Ve výchozím nastavení musí heslo obsahovat alespoň osm znaků a musí obsahovat znaky ze tří z následujících čtyř sad: velká písmena, malá písmena, číslice se základem 10 a symboly. Hesla můžou mít délku až 128 znaků. Používejte hesla, která jsou co nejdéle a složitá.
Na primární replice vytvořte hlavní klíč a certifikát a pak certifikát zálohujte pomocí privátního klíče.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOOpatrnost
Vaše heslo by mělo postupovat podle výchozích zásad hesel SQL Serveru . Ve výchozím nastavení musí heslo obsahovat alespoň osm znaků a musí obsahovat znaky ze tří z následujících čtyř sad: velká písmena, malá písmena, číslice se základem 10 a symboly. Hesla můžou mít délku až 128 znaků. Používejte hesla, která jsou co nejdéle a složitá.
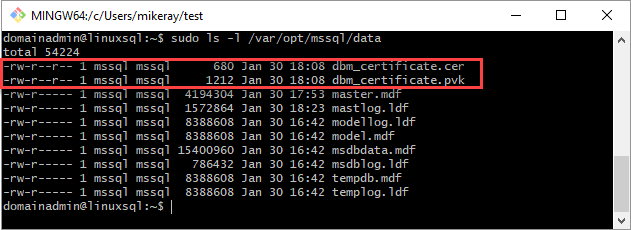
Zkopírujte certifikát a privátní klíč na server s Linuxem (sekundární replika) v
/var/opt/mssql/data. Soubory můžete zkopírovat na server s Linuxem pomocípscp.Nastavte skupinu a vlastnictví privátního klíče a certifikátu na
mssql:mssql.Následující skript nastaví skupinu a vlastnictví souborů.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerV následujícím diagramu jsou vlastnictví a skupina správně nastavené pro certifikát a klíč.
Na sekundární replice vytvořte přihlašovací jméno a heslo databáze a vytvořte hlavní klíč.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOOpatrnost
Vaše heslo by mělo postupovat podle výchozích zásad hesel SQL Serveru . Ve výchozím nastavení musí heslo obsahovat alespoň osm znaků a musí obsahovat znaky ze tří z následujících čtyř sad: velká písmena, malá písmena, číslice se základem 10 a symboly. Hesla můžou mít délku až 128 znaků. Používejte hesla, která jsou co nejdéle a složitá.
Na sekundární replice obnovte certifikát, který jste zkopírovali do
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GOV předchozím příkladu nahraďte
<private-key-password>stejným heslem, které jste použili při vytváření certifikátu na primární replice.Na primární replice vytvořte koncový bod.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GODůležitý
Brána firewall musí být otevřená pro naslouchací TCP port. V předchozím skriptu je port 5022. Použijte libovolný dostupný port TCP.
Na sekundární replice vytvořte koncový bod. Opakováním předchozího skriptu na sekundární replice vytvořte koncový bod.
Na primární replice vytvořte skupinu dostupnosti s
CLUSTER_TYPE = NONE. Ukázkový skript používáSEEDING_MODE = AUTOMATICk vytvoření AG.Poznámka
Pokud instance SQL Serveru ve Windows používá různé cesty pro datové a protokolové soubory, automatické zasetí se k instanci SQL Serveru na Linuxu nezdaří, protože tyto cesty na sekundární replice neexistují. Aby bylo možné použít následující skript pro víceplatformní skupiny dostupnosti (AG), musí databáze mít na serveru Windows stejnou cestu k datovým a protokolovým souborům. Případně můžete skript aktualizovat tak, aby nastavil
SEEDING_MODE = MANUAL, a pak databázi zálohovat a obnovit pomocíNORECOVERY, aby se databáze osadila.Toto chování platí pro image z Azure Marketplace.
Další informace o automatickém osévání naleznete v tématu Automatické osévání - Rozložení disku.
Před spuštěním skriptu aktualizujte hodnoty pro vaše AGs.
Nahraďte
<WinSQLInstance>názvem serveru instance SQL Serveru primární repliky.Nahraďte
<LinuxSQLInstance>názvem serveru instance systému SQL Server sekundární repliky.
Pokud chcete vytvořit AG, aktualizujte hodnoty a spusťte skript na primární replice.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GODalší informace najdete v tématu vytvoření skupiny dostupnosti.
Na sekundární replice se připojte se k AG.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOVytvořte databázi pro AG. V příkladu se používá databáze s názvem
TestDB. Pokud používáte automatické nasazení, nastavte stejnou cestu pro data i soubory protokolu.Před spuštěním skriptu aktualizujte hodnoty databáze.
Nahraďte
TestDBnázvem databáze.Nahraďte
<F:\Path>cestou k vaší databázi a souborům protokolu. Pro soubory databáze a protokolů použijte stejnou cestu.
Můžete také použít výchozí cesty.
Pokud chcete vytvořit databázi, spusťte skript.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY(NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOProveďte úplnou zálohu databáze.
Pokud nepoužíváte automatické nasazení, obnovte databázi na sekundárním serveru replika (Linux). Migrace databáze SQL Serveru z Windows do Linuxu pomocí zálohování a obnovení. Obnovte databázi
WITH NORECOVERYna sekundární replice.Přidejte databázi do skupiny dostupnosti. Aktualizujte ukázkový skript. Nahraďte
TestDBnázvem databáze. Na primární replice spusťte dotaz T-SQL a přidejte databázi do skupiny dostupnosti.ALTER AG [ag1] ADD DATABASE TestDB; GOOvěřte, že se databáze naplňuje na sekundární replice.

Převzetí služeb při selhání primární repliky
Každá skupina dostupnosti má pouze jednu primární repliku. Primární replika umožňuje čtení a zápisy. Pokud chcete změnit, která replika je primární, můžete provést přepnutí. V typické skupině dostupnosti správce clusteru automatizuje proces přepnutí při selhání. Ve skupině dostupnosti s typem clusteru NONE je proces převzetí služeb při selhání ruční.
Existují dva způsoby převzetí služeb při selhání primární repliky ve skupině dostupnosti s typem clusteru NONE:
- Ruční přepnutí při selhání bez ztráty dat
- Vynucené ruční přepnutí při selhání se ztrátou dat
Ruční převzetí služeb při selhání bez ztráty dat
Tuto metodu použijte, pokud je primární replika dostupná, ale potřebujete dočasně nebo trvale změnit, která instance je hostitelem primární repliky. Abyste se vyhnuli potenciální ztrátě dat, ujistěte se, že cílová sekundární replika je před provedením ručního převzetí služeb při selhání plně aktualizovaná.
Ruční převzetí provozu při selhání bez ztráty dat:
Přeměňte aktuální primární repliku na sekundární repliku pro cíl
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Pokud chcete zjistit, že aktivní transakce jsou potvrzeny do primární repliky a alespoň jedné synchronní sekundární repliky, spusťte následující dotaz:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;Sekundární replika je synchronizována, když je
synchronization_state_descSYNCHRONIZED.Aktualizujte
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITna 1.Následující skript nastaví
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITna 1 ve skupině dostupnosti s názvemag1. Před spuštěním následujícího skriptu nahraďteag1názvem vaší skupiny dostupnosti:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Toto nastavení zajišťuje, že je každá aktivní transakce potvrzena v primární replice a alespoň jedné synchronní sekundární replice.
Poznámka
Toto nastavení není specifické pro převzetí služeb při selhání a mělo by se nastavit na základě požadavků prostředí.
Nastavte primární repliku a sekundární repliky, které se nepodílejí na převzetí služeb při selhání, do režimu offline, aby se připravily na změnu role.
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEPřevést cílovou sekundární repliku na primární.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Aktualizujte roli starých primárních a dalších sekundárních serverů na
SECONDARY, spusťte následující příkaz v instanci SYSTÉMU SQL Server, která je hostitelem staré primární repliky:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Poznámka
Pokud chcete odstranit skupinu dostupnosti, použijte DROP AVAILABILITY GROUP. Pro skupinu dostupnosti vytvořenou s typem clusteru NONE nebo EXTERNAL spusťte příkaz na všech replikách, které jsou součástí skupiny dostupnosti.
Pokračujte v přesunu dat, spusťte následující příkaz pro každou databázi ve skupině dostupnosti v instanci SQL Serveru, která je hostitelem primární repliky:
ALTER DATABASE [db1] SET HADR RESUMEZnovu vytvořte každý posluchač, který jste vytvořili pro účely škálování pro čtení a který nespravuje správce clusteru. Pokud původní naslouchací proces odkazuje na původní primární server, odstraňte ho a znovu vytvořte tak, aby odkazoval na nový primární server.
Nucené ruční přepnutí při selhání se ztrátou dat
Pokud primární replika není dostupná a nejde ji okamžitě obnovit, je nutné vynutit přepnutí na sekundární repliku se ztrátou dat. Pokud se ale původní replika po selhání obnoví, převezme primární roli. Pokud se chcete vyhnout tomu, aby každá replika byla v jiném stavu, odeberte původní primární repliku ze skupiny dostupnosti po vynuceném selhání s ohrožením ztráty dat. Jakmile se původní primární server vrátí zpět do online režimu, úplně odeberte skupinu dostupnosti z něj.
Pokud chcete vynutit ruční selhání se ztrátou dat z primární repliky N1 na sekundární repliku N2, postupujte takto:
Na sekundární replice (N2) zahajte vynucené převzetí služeb při selhání:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;Na nové primární replice (N2) odeberte původní primární repliku (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Ověřte, že veškerý provoz aplikace směřuje na posluchač a/nebo novou primární repliku.
Pokud je původní primární server (N1) online, okamžitě přepněte skupinu dostupnosti AGRScale do režimu offline na původní primární (N1):
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEPokud existují data nebo nesynchronizované změny, zachovejte tato data prostřednictvím záloh nebo jiných možností replikace dat, které vyhovují vašim obchodním potřebám.
Potom odeberte skupinu dostupnosti z původní primární skupiny (N1):
DROP AVAILABILITY GROUP [AGRScale];Odstraňte databázi skupiny dostupnosti na původní primární repliku (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Volitelné) V případě potřeby teď můžete přidat N1 zpět jako novou sekundární repliku do skupiny dostupnosti AGRScale.
Tento článek si prostudoval postup vytvoření víceplatformové skupiny dostupnosti pro podporu migrace nebo úloh škálování pro čtení. Dá se použít k ručnímu zotavení po havárii. Také vysvětluje, jak provést převzetí služeb při selhání skupiny dostupnosti (AG). Platformově nezávislá AG používá typ clusteru NONE a nepodporuje vysokou dostupnost.