Configure SQL Server Always On availability group on Windows and Linux (cross-platform)
Applies to: ![]() SQL Server 2017 (14.x) and later
SQL Server 2017 (14.x) and later
This article explains the steps to create an Always On availability group (AG) with one replica on a Windows server and the other replica on a Linux server.
Important
SQL Server cross-platform availability groups, which include heterogeneous replicas with complete high-availability and disaster recovery support, is available with DH2i DxEnterprise. For more information, see SQL Server Availability Groups with Mixed Operating Systems.
View the following video to find out about cross-platform availability groups with DH2i.
This configuration is cross-platform because the replicas are on different operating systems. Use this configuration for migration from one platform to the other or disaster recovery (DR). This configuration doesn't support high availability.

Before proceeding, you should be familiar with installation and configuration for SQL Server instances on Windows and Linux.
Scenario
In this scenario, two servers are on different operating systems. A Windows Server 2022 named WinSQLInstance hosts the primary replica. A Linux server named LinuxSQLInstance host the secondary replica.
Configure the AG
The steps to create the AG are the same as the steps to create an AG for read-scale workloads. The AG cluster type is NONE, because there's no cluster manager.
For the scripts in this article, angle brackets < and > identify values that you must replace for your environment. The angle brackets themselves aren't required for the scripts.
Install SQL Server 2022 (16.x) on Windows Server 2022, enable Always On Availability Groups from SQL Server Configuration Manager, and set mixed mode authentication.
Tip
If you're validating this solution in Azure, place both servers in the same availability set to ensure they are separated in the data center.
Enable Availability Groups
For instructions, see Enable or disable Always On availability group feature.
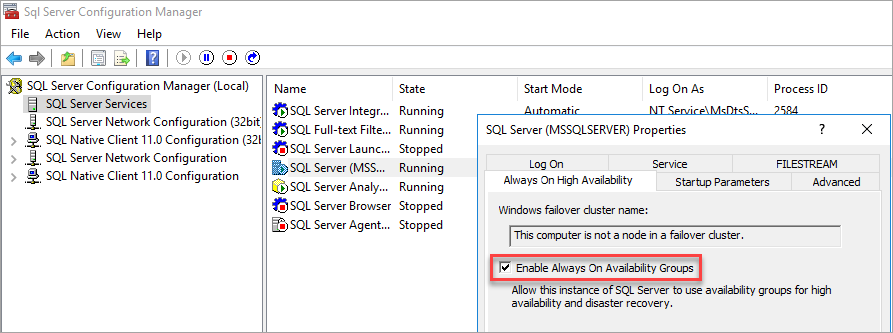
SQL Server Configuration Manager notes that the computer isn't a node in a failover cluster.
After you enable Availability Groups, restart SQL Server.
Set mixed mode authentication
For instructions, see Change server authentication mode.
Install SQL Server 2022 (16.x) on Linux. For instructions, see Installation guidance for SQL Server on Linux. Enable
hadrwith mssql-conf.To enable
hadrvia mssql-conf from a shell prompt, issue the following command:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1After you enable
hadr, restart the SQL Server instance:sudo systemctl restart mssql-server.serviceConfigure the
hostsfile on both servers, or register the server names with DNS.Open up firewall ports for TCP 1433 and 5022 on both Windows and Linux.
On the primary replica, create a database login and password.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOCaution
Your password should follow the SQL Server default password policy. By default, the password must be at least eight characters long and contain characters from three of the following four sets: uppercase letters, lowercase letters, base-10 digits, and symbols. Passwords can be up to 128 characters long. Use passwords that are as long and complex as possible.
On the primary replica, create a master key and certificate, then back up the certificate with a private key.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOCaution
Your password should follow the SQL Server default password policy. By default, the password must be at least eight characters long and contain characters from three of the following four sets: uppercase letters, lowercase letters, base-10 digits, and symbols. Passwords can be up to 128 characters long. Use passwords that are as long and complex as possible.
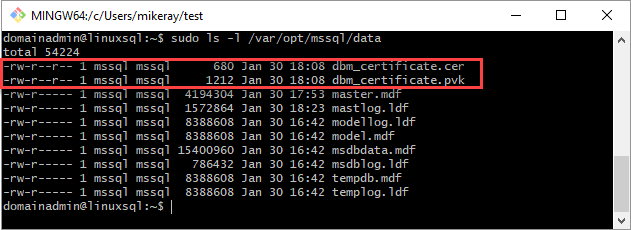
Copy the certificate and private key to the Linux server (secondary replica) at
/var/opt/mssql/data. You can usepscpto copy the files to the Linux server.Set the group and ownership of the private key and the certificate to
mssql:mssql.The following script sets the group and ownership of the files.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerIn the following diagram, ownership and group are set correctly for the certificate and key.
On the secondary replica, create a database login and password and create a master key.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOCaution
Your password should follow the SQL Server default password policy. By default, the password must be at least eight characters long and contain characters from three of the following four sets: uppercase letters, lowercase letters, base-10 digits, and symbols. Passwords can be up to 128 characters long. Use passwords that are as long and complex as possible.
On the secondary replica, restore the certificate you copied to
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GOIn the previous example, replace
<private-key-password>with the same password you used when creating the certificate on the primary replica.On the primary replica, create an endpoint.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOImportant
The firewall must be open for the listener TCP port. In the preceding script, the port is 5022. Use any available TCP port.
On the secondary replica, create the endpoint. Repeat the preceding script on the secondary replica to create the endpoint.
On the primary replica, create the AG with
CLUSTER_TYPE = NONE. The example script usesSEEDING_MODE = AUTOMATICto create the AG.Note
When the Windows instance of SQL Server uses different paths for data and log files, automatic seeding fails to the Linux instance of SQL Server, because these paths don't exist on the secondary replica. To use the following script for a cross-platform AG, the database requires the same path for the data and log files on the Windows server. Alternatively you can update the script to set
SEEDING_MODE = MANUALand then back up and restore the database withNORECOVERYto seed the database.This behavior applies to Azure Marketplace images.
For more information about automatic seeding, see Automatic Seeding - Disk Layout.
Before you run the script, update the values for your AGs.
Replace
<WinSQLInstance>with the server name of the primary replica SQL Server instance.Replace
<LinuxSQLInstance>with the server name of the secondary replica SQL Server instance.
To create the AG, update the values and run the script on the primary replica.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GOFor more information, see CREATE AVAILABILITY GROUP.
On the secondary replica, join the AG.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOCreate a database for the AG. The example steps use a database named
TestDB. If you're using automatic seeding, set the same path for both the data and the log files.Before you run the script, update the values for your database.
Replace
TestDBwith the name of your database.Replace
<F:\Path>with the path for your database and log files. Use the same path for the database and log files.
You can also use the default paths.
To create your database, run the script.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY(NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOTake a full backup of the database.
If you aren't using automatic seeding, restore the database on the secondary replica (Linux) server. Migrate a SQL Server database from Windows to Linux using backup and restore. Restore the database
WITH NORECOVERYon the secondary replica.Add the database to the AG. Update the example script. Replace
TestDBwith the name of your database. On the primary replica, run the T-SQL query to add the database to the AG.ALTER AG [ag1] ADD DATABASE TestDB; GOVerify that the database is getting populated on the secondary replica.

Fail over the primary replica
Each availability group has only one primary replica. The primary replica allows reads and writes. To change which replica is primary, you can fail over. In a typical availability group, the cluster manager automates the failover process. In an availability group with cluster type NONE, the failover process is manual.
There are two ways to fail over the primary replica in an availability group with cluster type NONE:
- Manual failover without data loss
- Forced manual failover with data loss
Manual failover without data loss
Use this method when the primary replica is available, but you need to temporarily or permanently change which instance hosts the primary replica. To avoid potential data loss, before you issue the manual failover, ensure that the target secondary replica is up to date.
To manually fail over without data loss:
Make the current primary and target secondary replica
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);To identify that active transactions are committed to the primary replica and at least one synchronous secondary replica, run the following query:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;The secondary replica is synchronized when
synchronization_state_descisSYNCHRONIZED.Update
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITto 1.The following script sets
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITto 1 on an availability group namedag1. Before you run the following script, replaceag1with the name of your availability group:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);This setting ensures that every active transaction is committed to the primary replica and at least one synchronous secondary replica.
Note
This setting is not specific to failover and should be set based on the requirements of the environment.
Set the primary replica and the secondary replica(s) not participating in the failover offline to prepare for the role change:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEPromote the target secondary replica to primary.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Update the role of the old primary and other secondaries to
SECONDARY, run the following command on the SQL Server instance that hosts the old primary replica:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Note
To delete an availability group, use DROP AVAILABILITY GROUP. For an availability group that's created with cluster type NONE or EXTERNAL, execute the command on all replicas that are part of the availability group.
Resume data movement, run the following command for every database in the availability group on the SQL Server instance that hosts the primary replica:
ALTER DATABASE [db1] SET HADR RESUMERe-create any listener you created for read-scale purposes and that isn't managed by a cluster manager. If the original listener points to the old primary, drop it and re-create it to point to the new primary.
Forced manual failover with data loss
If the primary replica is not available and can't immediately be recovered, then you need to force a failover to the secondary replica with data loss. However, if the original primary replica recovers after failover, it will assume the primary role. To avoid having each replica be in a different state, remove the original primary from the availability group after a forced failover with data loss. Once the original primary comes back online, remove the availability group from it entirely.
To force a manual failover with data loss from primary replica N1 to secondary replica N2, follow these steps:
On the secondary replica (N2), initiate the forced failover:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;On the new primary replica (N2), remove the original primary (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Validate that all application traffic is pointed to the listener and/or the new primary replica.
If the original primary (N1) comes online, immediately take availability group AGRScale offline on the original primary (N1):
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEIf there is data or unsynchronized changes, preserve this data via backups or other data replicating options that suit your business needs.
Next, remove the availability group from the original primary (N1):
DROP AVAILABILITY GROUP [AGRScale];Drop the availability group database on original primary replica (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Optional) If desired, you can now add N1 back as a new secondary replica to the availability group AGRScale.
This article reviewed the steps to create a cross-platform AG to support migration or read-scale workloads. It can be used for manual disaster recovery. It also explained how to fail over the AG. A cross-platform AG uses cluster type NONE and doesn't support high availability.