Co je modul plug-in?
Moduly plug-in jsou klíčovou součástí sémantického jádra. Pokud jste už v Microsoftu 365 používali moduly plug-in z rozšíření ChatGPT nebo Copilot, už je znáte. Moduly plug-in umožňují zapouzdření stávajících rozhraní API do kolekce, kterou může používat AI. Díky tomu můžete umělé inteligenci provádět akce, které by jinak nemohla provést.
Sémantické jádro na pozadí využívá funkce volání, což je nativní funkce většiny nejnovějších LLM, která umožňuje LLM, provádět plánování a volat vaše rozhraní API. Při volání funkcí můžou LLM požadovat (tj. volat) konkrétní funkci. Sémantické jádro pak zařadí požadavek do příslušné funkce v základu kódu a vrátí výsledky zpět do LLM, aby LLM mohl vygenerovat konečnou odpověď.
Ne všechny sady AI SDK mají podobný koncept modulů plug-in (většina má jenom funkce nebo nástroje). V podnikových scénářích jsou ale moduly plug-in cenné, protože zapouzdřují sadu funkcí, která odráží, jak už podnikoví vývojáři vyvíjejí služby a rozhraní API. Pluginy také dobře spolupracují s injekcí závislostí. V konstruktoru modulu plug-in můžete vkládat služby, které jsou nezbytné k provedení práce modulu plug-in (např. připojení k databázi, klienti HTTP atd.). To je obtížné provést s jinými sadami SDK, které nemají moduly plug-in.
Anatomie modulu plug-in
Na vysoké úrovni je modul plug-in skupinou funkcí, které je možné zpřístupnit aplikacím a službám AI. Funkce v rámci modulů plug-in pak můžou být orchestrovány aplikací AI, aby bylo možné provádět požadavky uživatelů. V rámci sémantického jádra můžete tyto funkce vyvolat automaticky pomocí volání funkce.
Poznámka
V jiných platformách se funkce často označují jako "nástroje" nebo "akce". V sémantickém jádru používáme termín "funkce", protože jsou obvykle definovány jako nativní funkce v základu kódu.
Pouhé poskytování funkcí však nestačí k vytvoření pluginu. Pokud chcete zapnout automatickou orchestraci pomocí volání funkcí, moduly plug-in také musí poskytovat podrobnosti, které sémanticky popisují, jak se chovají. Vše od vstupu, výstupu a vedlejších efektů funkce je potřeba popsat způsobem, kterému AI rozumí, jinak AI funkci nebude správně volat.
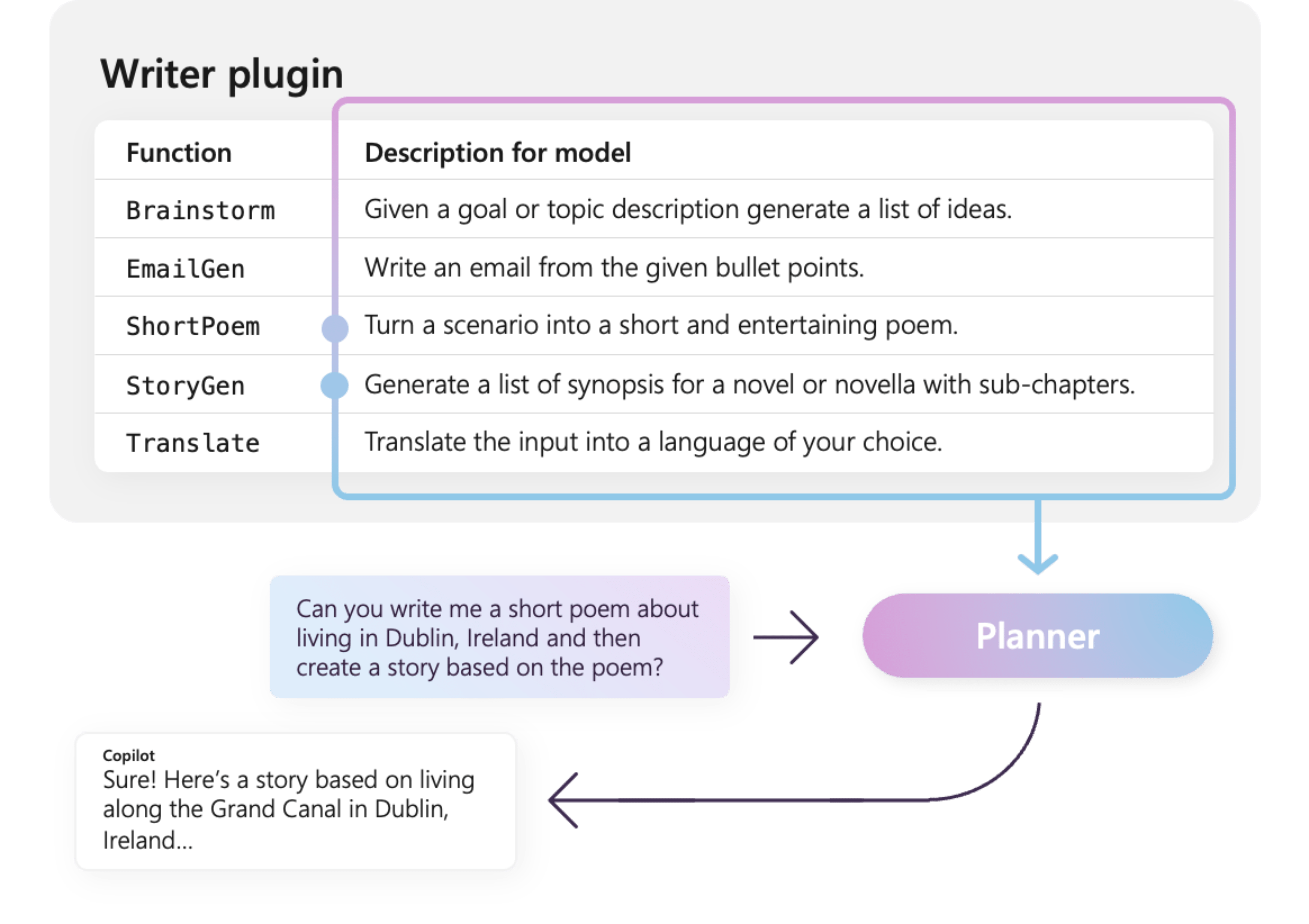
Například ukázkový modul plug-in WriterPlugin vpravo obsahuje funkce se sémantickými popisy, které popisují, co jednotlivé funkce dělají. LLM pak může pomocí těchto popisů vybrat nejlepší funkce k zavolání, aby splnila žádost uživatele.
Na obrázku vpravo by LLM pravděpodobně použil funkce ShortPoem a StoryGen, aby splnil požadavek uživatele díky poskytnutým sémantickým popisům.
Import různých typů modulů plug-in
Existují dva primární způsoby importu modulů plug-in do sémantického jádra: použití nativního kódu nebo použití specifikace OpenAPI. Bývalý vám umožňuje vytvářet zásuvné moduly ve vašem stávajícím kódu, které mohou využívat již existující závislosti a služby. Ten vám umožní importovat moduly plug-in ze specifikace OpenAPI, které se dají sdílet napříč různými programovacími jazyky a platformami.
Níže uvádíme jednoduchý příklad importu a použití nativního modulu plug-in. Další informace o importu těchto různých typů modulů plug-in najdete v následujících článcích:
Spropitné
Na začátku doporučujeme používat pluginy nativní kódové. S tím, jak vaše aplikace zralá a pracujete napříč multiplatformovými týmy, můžete zvážit použití specifikací OpenAPI ke sdílení modulů plug-in napříč různými programovacími jazyky a platformami.
Různé typy funkcí modulu plug-in
V rámci modulu plug-in budete mít obvykle dva různé typy funkcí, ty, které načítají data pro načítání rozšířené generace (RAG) a ty, které automatizují úlohy. Zatímco každý typ je funkčně stejný, obvykle se používají odlišně v aplikacích, které používají sémantické jádro.
Například u funkcí načítání můžete chtít použít strategie ke zlepšení výkonu (např. ukládání do mezipaměti a použití levnějších přechodných modelů pro sumarizaci). Zatímco u funkcí automatizace úkolů budete pravděpodobně chtít implementovat procesy schvalování mezi lidmi, abyste zajistili správné dokončení úkolů.
Další informace o různých typech funkcí pluginů najdete v následujících článcích:
Začínáme s moduly plug-in
Použití modulů plug-in v rámci sémantického jádra je vždy třístupňový proces:
- Definování modulu plug-in
- Přidání modulu plug-in do jádra
- A pak buď vyvolat funkce modulu plug-in v příkazovém řádku s voláním funkce
Níže poskytneme základní příklad použití modulu plug-in v rámci sémantického jádra. Podrobnější informace o vytváření a používání modulů plug-in najdete na výše uvedených odkazech.
1) Definování modulu plug-in
Nejjednodušší způsob, jak vytvořit modul plug-in, je definováním třídy a přidáním poznámek k jeho metodám pomocí atributu KernelFunction. Toto sémantickému jádru sděluje, že jde o funkci, kterou může volat umělá inteligence, nebo na kterou může odkazovat výzva.
Moduly plug-in můžete importovat také ze specifikace OpenAPI.
Níže vytvoříme modul plug-in, který může načíst stav světel a změnit jeho stav.
Spropitné
Vzhledem k tomu, že většina LLM je vytrénovaná pomocí Pythonu pro volání funkcí, doporučuje se pro názvy funkcí a názvy vlastností používat tzv. snake case, a to i v případě, že používáte C# nebo Java SDK.
using System.ComponentModel;
using Microsoft.SemanticKernel;
public class LightsPlugin
{
// Mock data for the lights
private readonly List<LightModel> lights = new()
{
new LightModel { Id = 1, Name = "Table Lamp", IsOn = false, Brightness = 100, Hex = "FF0000" },
new LightModel { Id = 2, Name = "Porch light", IsOn = false, Brightness = 50, Hex = "00FF00" },
new LightModel { Id = 3, Name = "Chandelier", IsOn = true, Brightness = 75, Hex = "0000FF" }
};
[KernelFunction("get_lights")]
[Description("Gets a list of lights and their current state")]
public async Task<List<LightModel>> GetLightsAsync()
{
return lights
}
[KernelFunction("get_state")]
[Description("Gets the state of a particular light")]
public async Task<LightModel?> GetStateAsync([Description("The ID of the light")] int id)
{
// Get the state of the light with the specified ID
return lights.FirstOrDefault(light => light.Id == id);
}
[KernelFunction("change_state")]
[Description("Changes the state of the light")]
public async Task<LightModel?> ChangeStateAsync(int id, LightModel LightModel)
{
var light = lights.FirstOrDefault(light => light.Id == id);
if (light == null)
{
return null;
}
// Update the light with the new state
light.IsOn = LightModel.IsOn;
light.Brightness = LightModel.Brightness;
light.Hex = LightModel.Hex;
return light;
}
}
public class LightModel
{
[JsonPropertyName("id")]
public int Id { get; set; }
[JsonPropertyName("name")]
public string Name { get; set; }
[JsonPropertyName("is_on")]
public bool? IsOn { get; set; }
[JsonPropertyName("brightness")]
public byte? Brightness { get; set; }
[JsonPropertyName("hex")]
public string? Hex { get; set; }
}
from typing import TypedDict, Annotated
class LightModel(TypedDict):
id: int
name: str
is_on: bool | None
brightness: int | None
hex: str | None
class LightsPlugin:
lights: list[LightModel] = [
{"id": 1, "name": "Table Lamp", "is_on": False, "brightness": 100, "hex": "FF0000"},
{"id": 2, "name": "Porch light", "is_on": False, "brightness": 50, "hex": "00FF00"},
{"id": 3, "name": "Chandelier", "is_on": True, "brightness": 75, "hex": "0000FF"},
]
@kernel_function
async def get_lights(self) -> List[LightModel]:
"""Gets a list of lights and their current state."""
return self.lights
@kernel_function
async def get_state(
self,
id: Annotated[int, "The ID of the light"]
) -> Optional[LightModel]:
"""Gets the state of a particular light."""
for light in self.lights:
if light["id"] == id:
return light
return None
@kernel_function
async def change_state(
self,
id: Annotated[int, "The ID of the light"],
new_state: LightModel
) -> Optional[LightModel]:
"""Changes the state of the light."""
for light in self.lights:
if light["id"] == id:
light["is_on"] = new_state.get("is_on", light["is_on"])
light["brightness"] = new_state.get("brightness", light["brightness"])
light["hex"] = new_state.get("hex", light["hex"])
return light
return None
public class LightsPlugin {
// Mock data for the lights
private final Map<Integer, LightModel> lights = new HashMap<>();
public LightsPlugin() {
lights.put(1, new LightModel(1, "Table Lamp", false));
lights.put(2, new LightModel(2, "Porch light", false));
lights.put(3, new LightModel(3, "Chandelier", true));
}
@DefineKernelFunction(name = "get_lights", description = "Gets a list of lights and their current state")
public List<LightModel> getLights() {
System.out.println("Getting lights");
return new ArrayList<>(lights.values());
}
@DefineKernelFunction(name = "change_state", description = "Changes the state of the light")
public LightModel changeState(
@KernelFunctionParameter(name = "id", description = "The ID of the light to change") int id,
@KernelFunctionParameter(name = "isOn", description = "The new state of the light") boolean isOn) {
System.out.println("Changing light " + id + " " + isOn);
if (!lights.containsKey(id)) {
throw new IllegalArgumentException("Light not found");
}
lights.get(id).setIsOn(isOn);
return lights.get(id);
}
}
Všimněte si, že poskytujeme popisy funkce a parametrů. To je důležité pro AI, abyste pochopili, co funkce dělá a jak ji používat.
Spropitné
Nebojte se poskytnout podrobné popisy vašich funkcí, pokud má AI potíže s jejich voláním. Několik snímků příkladů, doporučení pro použití (a ne použití) funkce a pokyny k tomu, kde získat požadované parametry, můžou být užitečné.
2) Přidání modulu plug-in do jádra
Jakmile modul plug-in definujete, můžete ho přidat do jádra tak, že vytvoříte novou instanci modulu plug-in a přidáte ho do kolekce modulů plug-in jádra.
Tento příklad ukazuje nejjednodušší způsob přidání třídy jako modulu plug-in pomocí metody AddFromType. Informace o způsobech přidávání pluginů najdete v článku přidávání nativních pluginů.
var builder = new KernelBuilder();
builder.Plugins.AddFromType<LightsPlugin>("Lights")
Kernel kernel = builder.Build();
kernel = Kernel()
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
// Import the LightsPlugin
KernelPlugin lightPlugin = KernelPluginFactory.createFromObject(new LightsPlugin(),
"LightsPlugin");
// Create a kernel with Azure OpenAI chat completion and plugin
Kernel kernel = Kernel.builder()
.withAIService(ChatCompletionService.class, chatCompletionService)
.withPlugin(lightPlugin)
.build();
3) Vyvolání funkcí modulu plug-in
Nakonec můžete mít AI vyvolat funkce pluginu pomocí volání funkcí. Níže je příklad, který ukazuje, jak pomocí umělé inteligence volat funkci get_lights z pluginu Lights před voláním funkce change_state, aby se zapnulo světlo.
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Create a kernel with Azure OpenAI chat completion
var builder = Kernel.CreateBuilder().AddAzureOpenAIChatCompletion(modelId, endpoint, apiKey);
// Build the kernel
Kernel kernel = builder.Build();
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
// Add a plugin (the LightsPlugin class is defined below)
kernel.Plugins.AddFromType<LightsPlugin>("Lights");
// Enable planning
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// Create a history store the conversation
var history = new ChatHistory();
history.AddUserMessage("Please turn on the lamp");
// Get the response from the AI
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
// Print the results
Console.WriteLine("Assistant > " + result);
// Add the message from the agent to the chat history
history.AddAssistantMessage(result);
import asyncio
from semantic_kernel import Kernel
from semantic_kernel.functions import kernel_function
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.chat_completion_client_base import ChatCompletionClientBase
from semantic_kernel.contents.chat_history import ChatHistory
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.connectors.ai.open_ai.prompt_execution_settings.azure_chat_prompt_execution_settings import (
AzureChatPromptExecutionSettings,
)
async def main():
# Initialize the kernel
kernel = Kernel()
# Add Azure OpenAI chat completion
chat_completion = AzureChatCompletion(
deployment_name="your_models_deployment_name",
api_key="your_api_key",
base_url="your_base_url",
)
kernel.add_service(chat_completion)
# Add a plugin (the LightsPlugin class is defined below)
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
# Enable planning
execution_settings = AzureChatPromptExecutionSettings()
execution_settings.function_choice_behavior = FunctionChoiceBehavior.Auto()
# Create a history of the conversation
history = ChatHistory()
history.add_message("Please turn on the lamp")
# Get the response from the AI
result = await chat_completion.get_chat_message_content(
chat_history=history,
settings=execution_settings,
kernel=kernel,
)
# Print the results
print("Assistant > " + str(result))
# Add the message from the agent to the chat history
history.add_message(result)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())
// Enable planning
InvocationContext invocationContext = new InvocationContext.Builder()
.withReturnMode(InvocationReturnMode.LAST_MESSAGE_ONLY)
.withToolCallBehavior(ToolCallBehavior.allowAllKernelFunctions(true))
.build();
// Create a history to store the conversation
ChatHistory history = new ChatHistory();
history.addUserMessage("Turn on light 2");
List<ChatMessageContent<?>> results = chatCompletionService
.getChatMessageContentsAsync(history, kernel, invocationContext)
.block();
System.out.println("Assistant > " + results.get(0));
Ve výše uvedeném kódu byste měli získat odpověď, která vypadá takto:
| Role | Zpráva |
|---|---|
| 🔵 uživatel | Zapněte lampu. |
| 🔴 Assistant (volání funkce) | Lights.get_lights() |
| 🟢 nástroj | [{ "id": 1, "name": "Table Lamp", "isOn": false, "brightness": 100, "hex": "FF0000" }, { "id": 2, "name": "Porch light", "isOn": false, "brightness": 50, "hex": "00FF00" }, { "id": 3, "name": "Chandelier", "isOn": true, "brightness": 75, "hex": "0000FF" }] |
| 🔴 Assistant (volání funkce) | Lights.change_state(1; { "isOn": true }) |
| 🟢 nástroj | { "id": 1, "name": "Table Lamp", "isOn": true, "brightness": 100, "hex": "FF0000" } |
| 🔴 asistent | Lampa je teď zapnutá. |
Spropitné
I když můžete vyvolat funkci plug-inu přímo, nedoporučuje se to, protože umělá inteligence (AI) by měla rozhodovat, které funkce se mají volat. Pokud potřebujete explicitní kontrolu nad tím, které funkce se volají, zvažte použití standardních metod v základu kódu místo modulů plug-in.
Obecná doporučení pro vytváření modulů plug-in
Vzhledem k tomu, že každý scénář má jedinečné požadavky, využívá různý návrh pluginů a může zahrnovat několik LLM, je obtížné poskytnout univerzálního průvodce návrhem pluginů. Níže jsou ale uvedená obecná doporučení a pokyny, které zajistí, že pluginy jsou přívětivé pro AI a aby je LLM mohly snadno a efektivně využívat.
Importujte pouze potřebné pluginy
Importujte pouze moduly plug-in, které obsahují funkce potřebné pro váš konkrétní scénář. Tento přístup nejen sníží počet spotřebovaných vstupních tokenů, ale také minimalizuje výskyt chybných volání funkcí do funkcí, které se ve scénáři nepoužívají. Celkově by tato strategie měla zvýšit přesnost volání funkcí a snížit počet falešně pozitivních výsledků.
Kromě toho OpenAI doporučuje, abyste v jednom volání rozhraní API nepoužíli více než 20 nástrojů; v ideálním případě ne více než 10 nástrojů. Jak uvádí OpenAI: "V jednom volání rozhraní API doporučujeme používat maximálně 20 nástrojů. Vývojáři obvykle vidí snížení schopnosti modelu vybrat správný nástroj, jakmile mají definované nástroje 10–20."* Další informace najdete v dokumentaci v Průvodce voláním funkcí OpenAI.
Přizpůsobit pluginy pro AI
Pokud chcete vylepšit schopnost LLM pochopit a využívat moduly plug-in, doporučujeme postupovat podle těchto pokynů:
Použít popisné a stručné názvy funkcí: Ujistěte se, že názvy funkcí jasně vyjadřují jejich účel, aby modelu pomohly pochopit, kdy vybrat jednotlivé funkce. Pokud je název funkce nejednoznačný, zvažte jeho přejmenování, aby byl srozumitelný. Nepoužívejte zkratky nebo akronymy ke zkracování názvů funkcí. Využijte
DescriptionAttributek poskytnutí dalšího kontextu a pokynů pouze v případě potřeby, což minimalizuje spotřebu tokenů.Minimalizovat parametry funkce: Omezit počet parametrů funkce a používat primitivní typy, kdykoli je to možné. Tento přístup snižuje spotřebu tokenů a zjednodušuje podpis funkce, což usnadňuje efektivní shodu parametrů funkce LLM.
Pojmenujte parametry funkce jasně: Přiřaďte parametrům funkce popisné názvy, aby byl jasný jejich účel. Nepoužívejte zkratky ke zkrácení názvů parametrů, protože to pomůže LLM lépe uvažovat o parametrech a poskytnout přesné hodnoty. Stejně jako u názvů funkcí používejte
DescriptionAttributepouze v případě, že je potřeba minimalizovat spotřebu tokenů.
Nalezení správné rovnováhy mezi počtem funkcí a jejich odpovědností
Na jedné straně je vhodné mít funkce s jednou zodpovědností, které umožňují udržovat funkce jednoduché a opakovaně použitelné napříč několika scénáři. Na druhé straně každé volání funkce nese režijní náklady z hlediska latence odezvy sítě a počtu spotřebovaných vstupních a výstupních tokenů: vstupní tokeny se používají k odesílání definice funkce a výsledku vyvolání do LLM, zatímco výstupní tokeny se spotřebovávají při příjmu volání funkce z modelu.
Alternativně je možné implementovat jednu funkci s více zodpovědnostmi, aby se snížil počet spotřebovaných tokenů a snížila režijní náklady na síť, i když se jedná o náklady na snížení opakované použitelnosti v jiných scénářích.
Konsolidace mnoha zodpovědností do jedné funkce ale může zvýšit počet a složitost parametrů funkce a jeho návratový typ. Tato složitost může vést k situacím, kdy model může mít problém správně sladit parametry funkce, což může vést k chybějícím parametrům nebo hodnotám nesprávného typu. Proto je nezbytné zajistit správnou rovnováhu mezi počtem funkcí, aby se snížila režie sítě a počet zodpovědností, které každá funkce má, a zajistit, aby model mohl přesně odpovídat parametrům funkce.
Transformovat sémantické funkce jádra
Využijte techniky transformace pro funkce sémantického jádra, jak je popsáno v blogovém příspěvku Transforming Sémantic Kernel Functions příspěvku na:
změnit chování funkce: Existují scénáře, kdy výchozí chování funkce nemusí odpovídat požadovanému výsledku a není možné upravit implementaci původní funkce. V takových případech můžete vytvořit novou funkci, která zabalí původní funkci a odpovídajícím způsobem upraví její chování.
Zadejte kontextové informace: Funkce mohou vyžadovat parametry, které LLM nemůže nebo neměl odvodit. Pokud například funkce potřebuje jednat jménem aktuálního uživatele nebo vyžaduje ověřovací informace, je tento kontext obvykle dostupný pro hostitelskou aplikaci, ale ne pro LLM. V takových případech můžete upravit funkci tak, aby volala původní funkci a zároveň poskytovala potřebné kontextové informace z hostitelské aplikace spolu s argumenty dodanými LLM.
Změnit seznam parametrů, typy a názvy: Pokud má původní funkce složitý podpis, který LLM nedokáže interpretovat, můžete funkci transformovat na jeden s jednodušším podpisem, který LLM snadněji pochopí. To může zahrnovat změnu názvů parametrů, typů, počtu parametrů a zploštění nebo rozplétání složitých parametrů, mimo jiné úpravy.
Využití místního stavu
Při navrhování modulů plug-in, které pracují s relativně velkými nebo důvěrnými datovými sadami, jako jsou dokumenty, články nebo e-maily obsahující citlivé informace, zvažte použití místního stavu k ukládání původních dat nebo průběžných výsledků, které nemusí být odesílány do LLM. Funkce pro takové scénáře můžou přijímat a vracet ID stavu, což vám umožní vyhledávat data a přistupovat k datům místně místo předání skutečných dat do LLM, pouze aby je získaly zpět jako argument pro další vyvolání funkce.
Díky místnímu ukládání dat můžete zachovat soukromé a zabezpečené informace a zároveň se vyhnout zbytečné spotřebě tokenů během volání funkce. Tento přístup nejen zlepšuje ochranu osobních údajů v datech, ale také zlepšuje celkovou efektivitu při zpracování velkých nebo citlivých datových sad.
Zadání schématu návratového typu funkce do modelu AI
Použijte jednu z technik popsaných v části Poskytování schématu návratového typu funkce do oddílu LLM pro předání schématu návratového typu funkce modelu AI.
Pomocí dobře definovaného schématu návratového typu dokáže model AI přesně identifikovat zamýšlené vlastnosti a eliminovat potenciální nepřesnosti, které mohou nastat, když model vytváří předpoklady na základě neúplných nebo nejednoznačných informací v případě, že schéma chybí. To v důsledku toho zvyšuje přesnost volání funkcí, což vede k spolehlivějším a přesnějším výsledkům.