Pokročilejší scénáře telemetrie
Poznámka:
Tento článek použije řídicí panel Aspire pro ilustraci. Pokud raději používáte jiné nástroje, projděte si dokumentaci k nástroji, který používáte v pokynech k nastavení.
Automatické volání funkcí
Automatické volání funkcí je funkce sémantického jádra, která umožňuje, aby jádro automaticky provádělo funkce, když model reaguje voláním funkce, a poskytuje výsledky zpět do modelu. Tato funkce je užitečná ve scénářích, kdy dotaz vyžaduje více iterací volání funkcí, aby získal konečnou odpověď v přirozeném jazyce. Další podrobnosti najdete v těchto ukázkách GitHubu.
Poznámka:
Volání funkcí není podporováno všemi modely.
Tip
Uslyšíte termín "nástroje" a "volání nástrojů" někdy zaměnitelně s "funkcemi" a "volání funkce".
Požadavky
- Nasazení dokončení chatu Azure OpenAI, které podporuje volání funkcí.
- Docker
- Nejnovější sada .NET SDK pro váš operační systém.
- Nasazení dokončení chatu Azure OpenAI, které podporuje volání funkcí.
- Docker
- Na počítači je nainstalovaný Python 3.10, 3.11 nebo 3.12 .
Poznámka:
Sémantická pozorovatelnost jádra zatím není pro Javu k dispozici.
Nastavení
Vytvoření nové konzolové aplikace
Spuštěním následujícího příkazu v terminálu vytvořte novou konzolovou aplikaci v jazyce C#:
dotnet new console -n TelemetryAutoFunctionCallingQuickstart
Po dokončení příkazu přejděte do nově vytvořeného adresáře projektu.
Instalace požadovaných balíčků
Sémantické jádro
dotnet add package Microsoft.SemanticKernelExportér konzoly OpenTelemetry
dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol
Vytvoření jednoduché aplikace pomocí sémantického jádra
V adresáři projektu otevřete Program.cs soubor v oblíbeném editoru. Vytvoříme jednoduchou aplikaci, která používá sémantické jádro k odeslání výzvy do modelu dokončování chatu. Nahraďte stávající obsah následujícím kódem a vyplňte požadované hodnoty pro deploymentName, endpointa apiKey:
using System.ComponentModel;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using OpenTelemetry;
using OpenTelemetry.Logs;
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
namespace TelemetryAutoFunctionCallingQuickstart
{
class BookingPlugin
{
[KernelFunction("FindAvailableRooms")]
[Description("Finds available conference rooms for today.")]
public async Task<List<string>> FindAvailableRoomsAsync()
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return ["Room 101", "Room 201", "Room 301"];
}
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return $"Room {room} booked.";
}
}
class Program
{
static async Task Main(string[] args)
{
// Endpoint to the Aspire Dashboard
var endpoint = "http://localhost:4317";
var resourceBuilder = ResourceBuilder
.CreateDefault()
.AddService("TelemetryAspireDashboardQuickstart");
// Enable model diagnostics with sensitive data.
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnosticsSensitive", true);
using var traceProvider = Sdk.CreateTracerProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddSource("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var meterProvider = Sdk.CreateMeterProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddMeter("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var loggerFactory = LoggerFactory.Create(builder =>
{
// Add OpenTelemetry as a logging provider
builder.AddOpenTelemetry(options =>
{
options.SetResourceBuilder(resourceBuilder);
options.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint));
// Format log messages. This is default to false.
options.IncludeFormattedMessage = true;
options.IncludeScopes = true;
});
builder.SetMinimumLevel(LogLevel.Information);
});
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddSingleton(loggerFactory);
builder.AddAzureOpenAIChatCompletion(
deploymentName: "your-deployment-name",
endpoint: "your-azure-openai-endpoint",
apiKey: "your-azure-openai-api-key"
);
builder.Plugins.AddFromType<BookingPlugin>();
Kernel kernel = builder.Build();
var answer = await kernel.InvokePromptAsync(
"Reserve a conference room for me today.",
new KernelArguments(
new OpenAIPromptExecutionSettings {
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
}
)
);
Console.WriteLine(answer);
}
}
}
V kódu výše definujeme nejprve napodobený modul plug-in pro rezervaci konferenční místnosti se dvěma funkcemi: FindAvailableRoomsAsync a BookRoomAsync. Pak vytvoříme jednoduchou konzolovou aplikaci, která zaregistruje modul plug-in do jádra, a požádáme ho, aby v případě potřeby automaticky volal funkce.
Vytvoření nového virtuálního prostředí Pythonu
python -m venv telemetry-auto-function-calling-quickstart
Aktivujte virtuální prostředí.
telemetry-auto-function-calling-quickstart\Scripts\activate
Instalace požadovaných balíčků
pip install semantic-kernel opentelemetry-exporter-otlp-proto-grpc
Vytvoření jednoduchého skriptu Pythonu s sémantickým jádrem
Vytvořte nový skript Pythonu a otevřete ho v oblíbeném editoru.
New-Item -Path telemetry_auto_function_calling_quickstart.py -ItemType file
Vytvoříme jednoduchý skript Pythonu, který používá sémantické jádro k odeslání výzvy do modelu dokončování chatu. Nahraďte stávající obsah následujícím kódem a vyplňte požadované hodnoty pro deployment_name, endpointa api_key:
import asyncio
import logging
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.metrics import set_meter_provider
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.metrics.view import DropAggregation, View
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.semconv.resource import ResourceAttributes
from opentelemetry.trace import set_tracer_provider
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.prompt_execution_settings import PromptExecutionSettings
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.functions.kernel_function_decorator import kernel_function
class BookingPlugin:
@kernel_function(
name="find_available_rooms",
description="Find available conference rooms for today.",
)
def find_available_rooms(self,) -> list[str]:
return ["Room 101", "Room 201", "Room 301"]
@kernel_function(
name="book_room",
description="Book a conference room.",
)
def book_room(self, room: str) -> str:
return f"Room {room} booked."
# Endpoint to the Aspire Dashboard
endpoint = "http://localhost:4317"
# Create a resource to represent the service/sample
resource = Resource.create({ResourceAttributes.SERVICE_NAME: "telemetry-aspire-dashboard-quickstart"})
def set_up_logging():
exporter = OTLPLogExporter(endpoint=endpoint)
# Create and set a global logger provider for the application.
logger_provider = LoggerProvider(resource=resource)
# Log processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
logger_provider.add_log_record_processor(BatchLogRecordProcessor(exporter))
# Sets the global default logger provider
set_logger_provider(logger_provider)
# Create a logging handler to write logging records, in OTLP format, to the exporter.
handler = LoggingHandler()
# Add filters to the handler to only process records from semantic_kernel.
handler.addFilter(logging.Filter("semantic_kernel"))
# Attach the handler to the root logger. `getLogger()` with no arguments returns the root logger.
# Events from all child loggers will be processed by this handler.
logger = logging.getLogger()
logger.addHandler(handler)
logger.setLevel(logging.INFO)
def set_up_tracing():
exporter = OTLPSpanExporter(endpoint=endpoint)
# Initialize a trace provider for the application. This is a factory for creating tracers.
tracer_provider = TracerProvider(resource=resource)
# Span processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
tracer_provider.add_span_processor(BatchSpanProcessor(exporter))
# Sets the global default tracer provider
set_tracer_provider(tracer_provider)
def set_up_metrics():
exporter = OTLPMetricExporter(endpoint=endpoint)
# Initialize a metric provider for the application. This is a factory for creating meters.
meter_provider = MeterProvider(
metric_readers=[PeriodicExportingMetricReader(exporter, export_interval_millis=5000)],
resource=resource,
views=[
# Dropping all instrument names except for those starting with "semantic_kernel"
View(instrument_name="*", aggregation=DropAggregation()),
View(instrument_name="semantic_kernel*"),
],
)
# Sets the global default meter provider
set_meter_provider(meter_provider)
# This must be done before any other telemetry calls
set_up_logging()
set_up_tracing()
set_up_metrics()
async def main():
# Create a kernel and add a service
kernel = Kernel()
kernel.add_service(AzureChatCompletion(
api_key="your-azure-openai-api-key",
endpoint="your-azure-openai-endpoint",
deployment_name="your-deployment-name"
))
kernel.add_plugin(BookingPlugin(), "BookingPlugin")
answer = await kernel.invoke_prompt(
"Reserve a conference room for me today.",
arguments=KernelArguments(
settings=PromptExecutionSettings(
function_choice_behavior=FunctionChoiceBehavior.Auto(),
),
),
)
print(answer)
if __name__ == "__main__":
asyncio.run(main())
V kódu výše definujeme nejprve napodobený modul plug-in pro rezervaci konferenční místnosti se dvěma funkcemi: find_available_rooms a book_room. Pak vytvoříme jednoduchý skript Pythonu, který zaregistruje modul plug-in do jádra, a požádáme ho, aby v případě potřeby automaticky volal funkce.
Proměnné prostředí
Další informace o nastavení požadovaných proměnných prostředí pro povolení generování rozsahů pro konektory AI najdete v tomto článku .
Poznámka:
Sémantická pozorovatelnost jádra zatím není pro Javu k dispozici.
Spuštění řídicího panelu Aspire
Podle zde uvedených pokynů spusťte řídicí panel. Po spuštění řídicího panelu otevřete prohlížeč a přejděte na http://localhost:18888 řídicí panel.
Spustit
Spusťte konzolovou aplikaci pomocí následujícího příkazu:
dotnet run
Spusťte skript Pythonu pomocí následujícího příkazu:
python telemetry_auto_function_calling_quickstart.py
Poznámka:
Sémantická pozorovatelnost jádra zatím není pro Javu k dispozici.
Zobrazený výstup by měl vypadat přibližně takto:
Room 101 has been successfully booked for you today.
Kontrola telemetrických dat
Po spuštění aplikace přejděte na řídicí panel a zkontrolujte telemetrická data.
Najděte trasování aplikace na kartě Trasování . V trasování byste měli mít pět rozsahů:
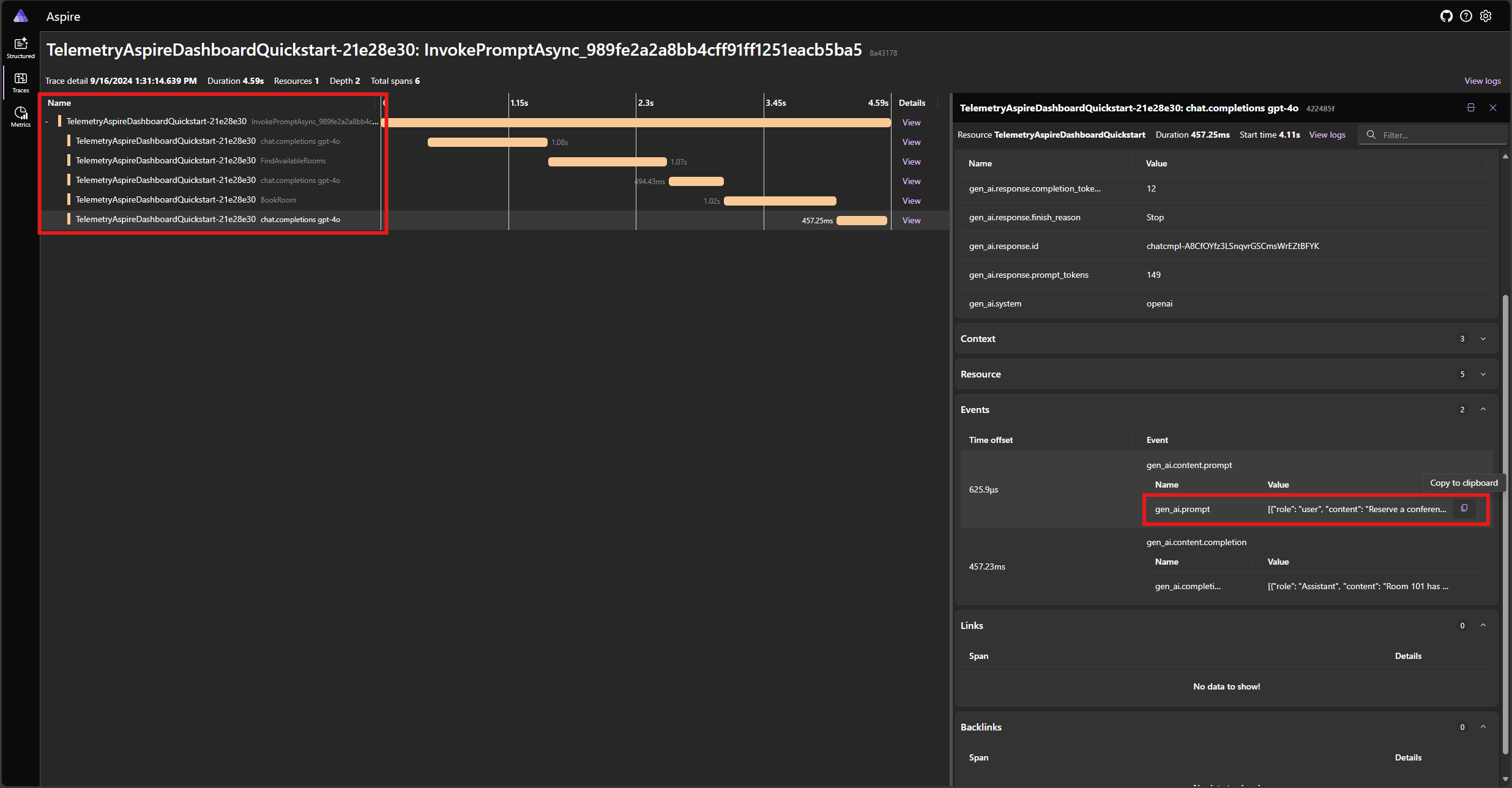
Tyto 5 rozsahů představují interní operace jádra s povoleným automatickým voláním funkce. Nejprve vyvolá model, který požaduje volání funkce. Pak jádro automaticky spustí funkci FindAvailableRoomsAsync a vrátí výsledek do modelu. Model pak požádá o další volání funkce, aby provedl rezervaci, a jádro funkci automaticky spustí BookRoomAsync a vrátí výsledek modelu. Nakonec model vrátí odpověď přirozeného jazyka uživateli.
A pokud kliknete na poslední rozsah a hledáte výzvu v gen_ai.content.prompt události, měli byste vidět něco podobného jako v následujícím příkladu:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_NtKi0OgOllJj1StLkOmJU8cP",
"function": { "arguments": {}, "name": "FindAvailableRooms" },
"type": "function"
}
]
},
{
"role": "tool",
"content": "[\u0022Room 101\u0022,\u0022Room 201\u0022,\u0022Room 301\u0022]"
},
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_mjQfnZXLbqp4Wb3F2xySds7q",
"function": { "arguments": { "room": "Room 101" }, "name": "BookRoom" },
"type": "function"
}
]
},
{ "role": "tool", "content": "Room Room 101 booked." }
]
Toto je historie chatu, která se sestaví jako model a jádro vzájemně spolupracují. To se odešle do modelu v poslední iteraci, aby se získala odpověď v přirozeném jazyce.
Najděte trasování aplikace na kartě Trasování . V trasování seskupené pod AutoFunctionInvocationLoop rozsahem byste měli mít pět rozsahů:
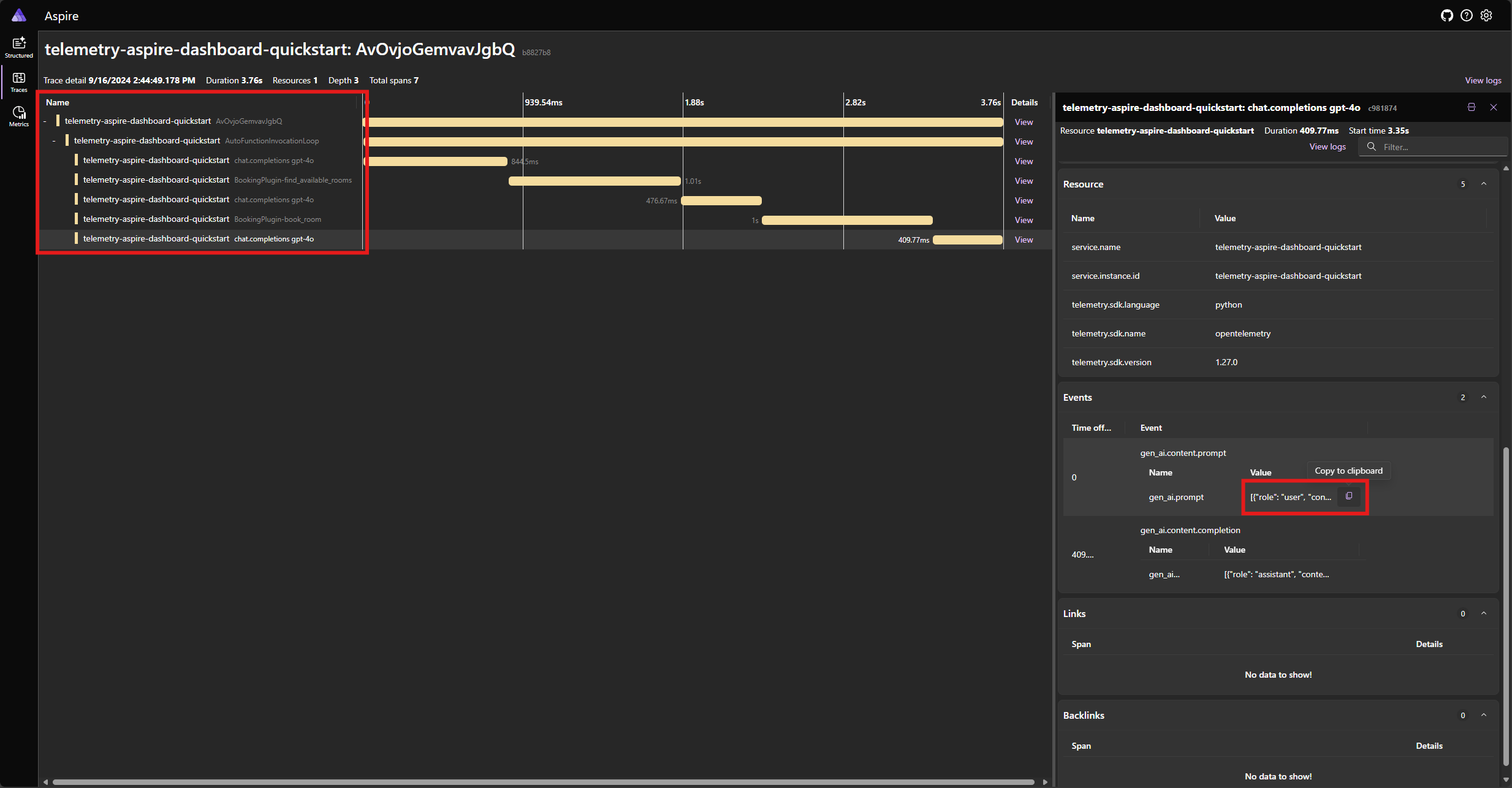
Tyto 5 rozsahů představují interní operace jádra s povoleným automatickým voláním funkce. Nejprve vyvolá model, který požaduje volání funkce. Pak jádro automaticky spustí funkci find_available_rooms a vrátí výsledek do modelu. Model pak požádá o další volání funkce, aby provedl rezervaci, a jádro funkci automaticky spustí book_room a vrátí výsledek modelu. Nakonec model vrátí odpověď přirozeného jazyka uživateli.
A pokud kliknete na poslední rozsah a hledáte výzvu v gen_ai.content.prompt události, měli byste vidět něco podobného jako v následujícím příkladu:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_ypqO5v6uTRlYH9sPTjvkGec8",
"type": "function",
"function": {
"name": "BookingPlugin-find_available_rooms",
"arguments": "{}"
}
}
]
},
{
"role": "tool",
"content": "['Room 101', 'Room 201', 'Room 301']",
"tool_call_id": "call_ypqO5v6uTRlYH9sPTjvkGec8"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_XDZGeTfNiWRpYKoHoH9TZRoX",
"type": "function",
"function": {
"name": "BookingPlugin-book_room",
"arguments": "{\"room\":\"Room 101\"}"
}
}
]
},
{
"role": "tool",
"content": "Room Room 101 booked.",
"tool_call_id": "call_XDZGeTfNiWRpYKoHoH9TZRoX"
}
]
Toto je historie chatu, která se sestaví jako model a jádro vzájemně spolupracují. To se odešle do modelu v poslední iteraci, aby se získala odpověď v přirozeném jazyce.
Poznámka:
Sémantická pozorovatelnost jádra zatím není pro Javu k dispozici.
Zpracování chyb
Pokud během provádění funkce dojde k chybě, jádro chybu automaticky zachytí a vrátí do modelu chybovou zprávu. Model pak může pomocí této chybové zprávy poskytnout uživateli odpověď v přirozeném jazyce.
BookRoomAsync Upravte funkci v kódu jazyka C#, aby simuluje chybu:
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
throw new Exception("Room is not available.");
}
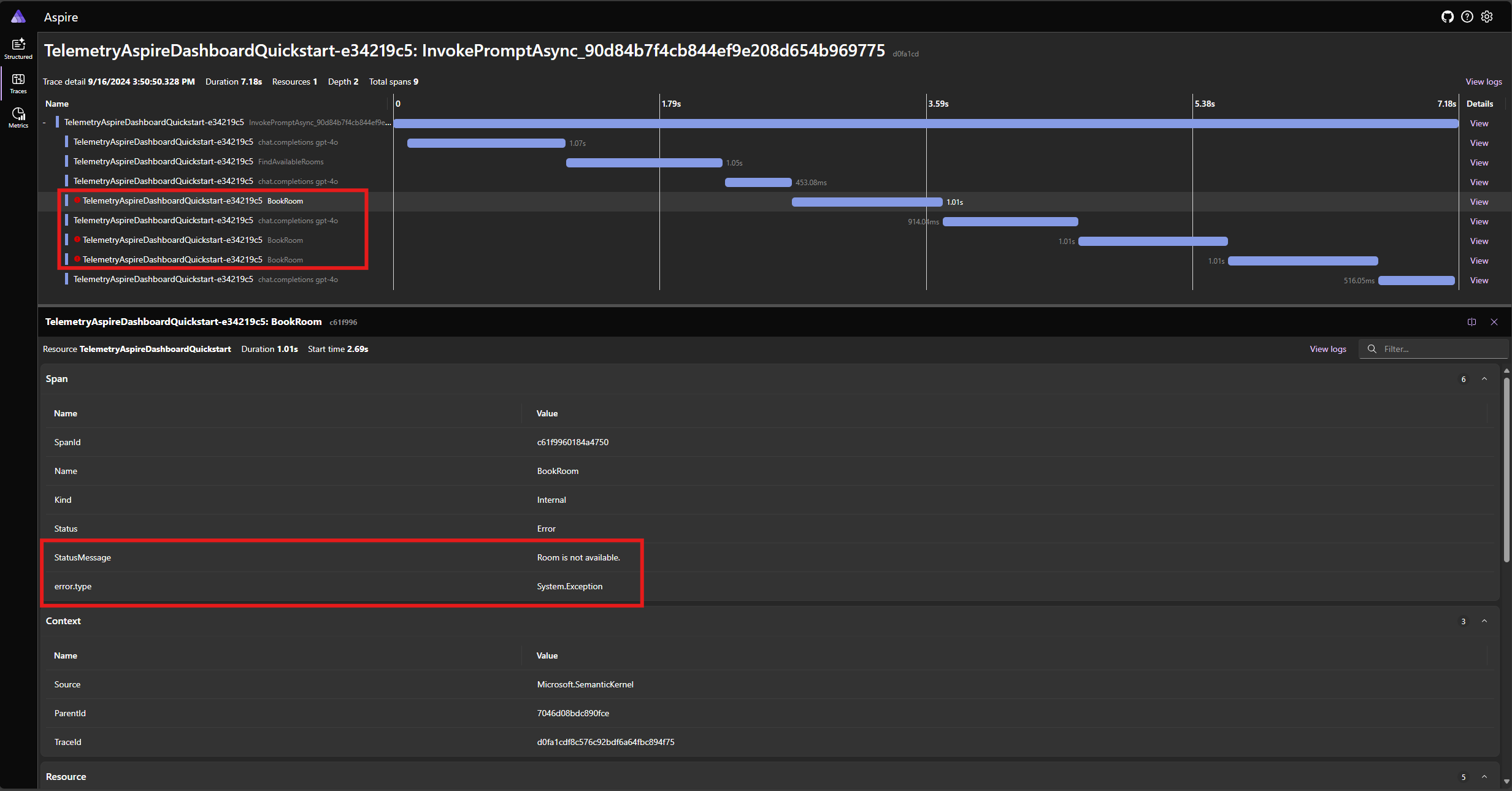
Spusťte aplikaci znovu a sledujte trasování na řídicím panelu. Měli byste vidět rozsah představující volání funkce jádra s chybou:
Poznámka:
Je velmi pravděpodobné, že odpovědi modelu na chybu se můžou při každém spuštění aplikace lišit, protože model je stochastický. Může se zobrazit, že model rezervuje všechny tři místnosti najednou, nebo si rezervujete jednu při prvním rezervaci dalších dvou místností atd.
Upravte funkci v kódu Pythonu book_room tak, aby simuluje chybu:
@kernel_function(
name="book_room",
description="Book a conference room.",
)
async def book_room(self, room: str) -> str:
# Simulate a remote call to a booking system
await asyncio.sleep(1)
raise Exception("Room is not available.")
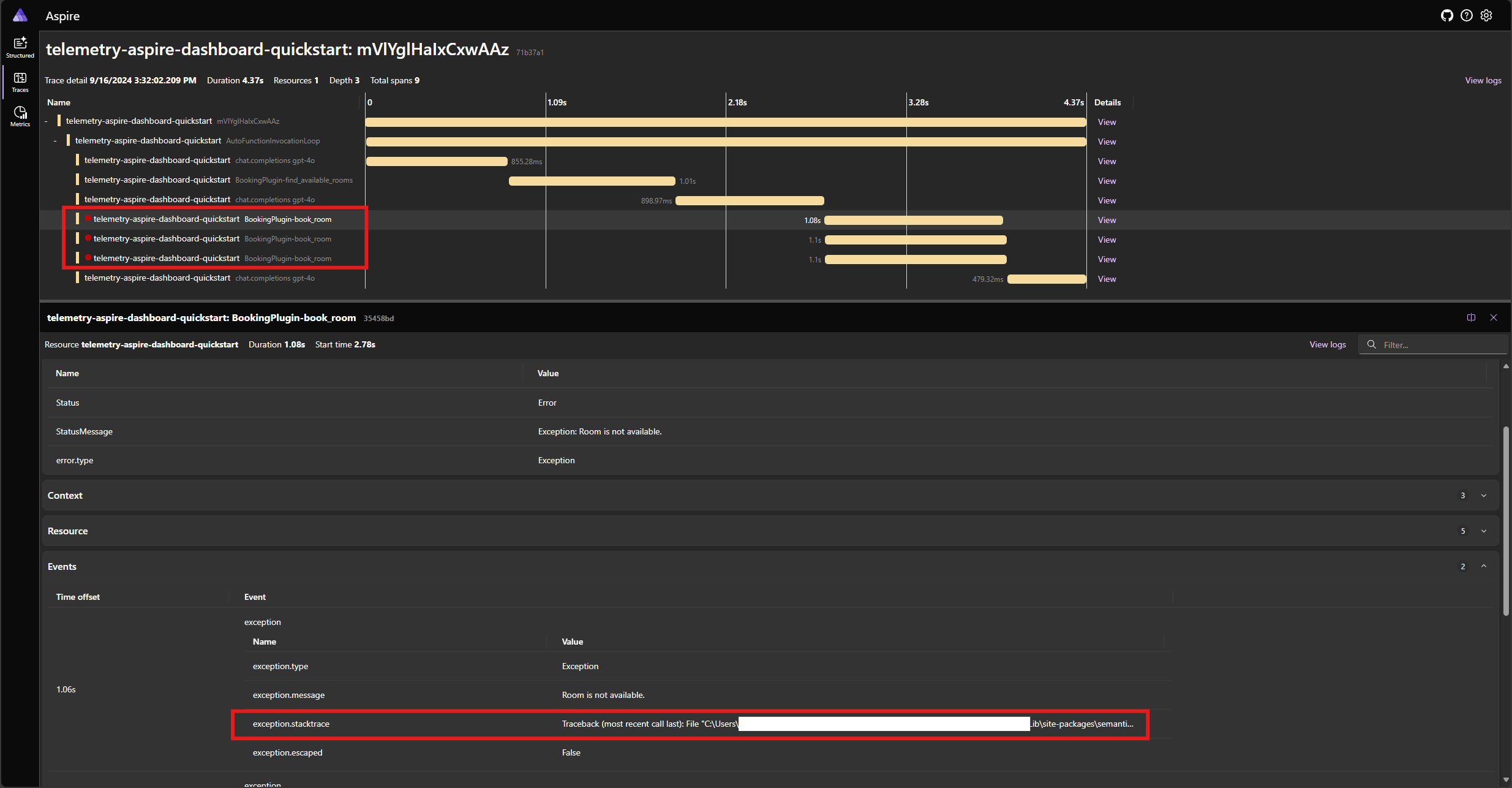
Spusťte aplikaci znovu a sledujte trasování na řídicím panelu. Měli byste vidět rozsah představující volání funkce jádra s chybou a trasování zásobníku:
Poznámka:
Je velmi pravděpodobné, že odpovědi modelu na chybu se můžou při každém spuštění aplikace lišit, protože model je stochastický. Může se zobrazit, že model rezervuje všechny tři místnosti najednou, nebo si rezervujete jednu při prvním rezervaci dalších dvou místností atd.
Poznámka:
Sémantická pozorovatelnost jádra zatím není pro Javu k dispozici.
Další kroky a další čtení
V produkčním prostředí můžou vaše služby získat velký počet požadavků. Sémantické jádro vygeneruje velké množství telemetrických dat. některé z nich nemusí být pro váš případ použití užitečné a zavedou zbytečné náklady na ukládání dat. Pomocí funkce vzorkování můžete snížit objem shromážděných telemetrických dat.
Pozorovatelnost v sémantickém jádru se neustále vylepšuje. Nejnovější aktualizace a nové funkce najdete v úložišti GitHub.