Odesílání a správa úloh v clusteru Apache Spark™ ve službě HDInsight v AKS
Důležitý
Azure HDInsight v AKS byl vyřazen 31. ledna 2025. Zjistěte více v tomto oznámení.
Abyste se vyhnuli náhlému ukončení úloh, musíte migrovat úlohy do Microsoft Fabric nebo ekvivalentního produktu Azure.
Důležitý
Tato funkce je aktuálně ve verzi Preview. Doplňkové podmínky použití pro Preview verzi Microsoft Azure zahrnují další právní podmínky, které se vztahují na funkce Azure, jež jsou v beta, v Preview nebo ještě nebyly obecně dostupné. Informace o této specifické ukázce najdete na Azure HDInsight ve službě AKS. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás pro další aktualizace na komunitě Azure HDInsight.
Po vytvoření clusteru může uživatel k odesílání a správě úloh používat různá rozhraní.
- s využitím Jupyteru
- pomocí Zeppelinu
- pomocí SSH (spark-submit)
Použití Jupyteru
Požadavky
Cluster Apache Spark™ ve službě HDInsight v AKS. Další informace najdete v tématu Vytvoření clusteru Apache Spark.
Jupyter Notebook je interaktivní prostředí poznámkového bloku, které podporuje různé programovací jazyky.
Vytvoření poznámkového bloku Jupyter
Přejděte na stránku clusteru Apache Spark™ a otevřete kartu Přehled. Klikněte na Jupyter, požádá vás o ověření a otevření webové stránky Jupyter.

Na webové stránce Jupyter vyberte Nový > PySpark a vytvořte poznámkový blok.
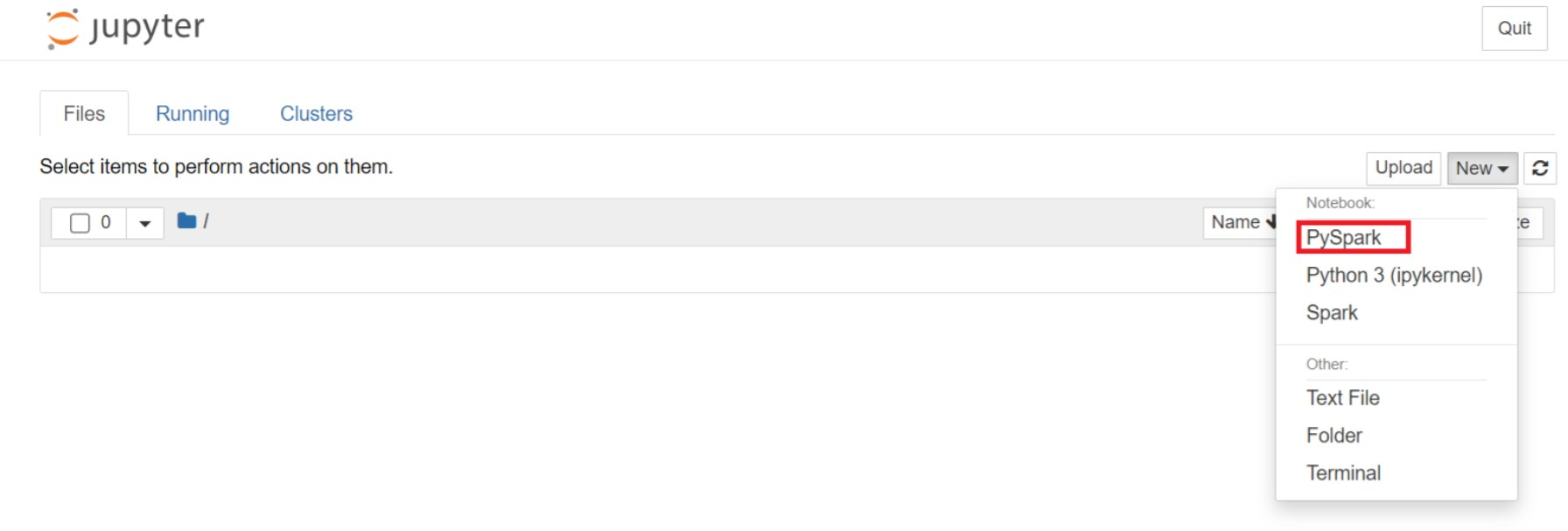
Byl vytvořen a otevřen nový poznámkový blok s názvem
Untitled(Untitled.ipynb).Poznámka
Když k vytvoření poznámkového bloku použijete jádro PySpark nebo Python 3, relace Sparku se automaticky vytvoří při spuštění první buňky kódu. Relaci nemusíte explicitně vytvářet.
Do prázdné buňky poznámkového bloku Jupyter Notebook vložte následující kód a stisknutím kombinace kláves SHIFT+ENTER kód spusťte. Podívejte se zde na další ovládací prvky v Jupyteru.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Vykreslení grafu s osou X a Y s platem a věkem
Do prázdné buňky v Jupyter Notebook vložte následující kód a stisknutím kláves SHIFT + ENTER kód spusťte.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()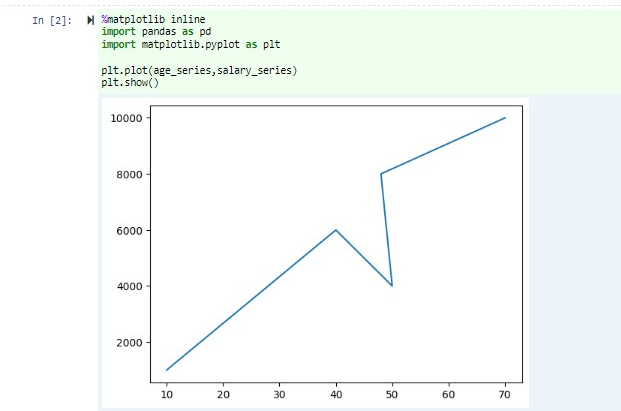




Uložení poznámkového bloku
V řádku nabídek poznámkového bloku přejděte na Soubor > Uložit a kontrolní bod.
Vypněte poznámkový blok a uvolněte prostředky clusteru: z řádku nabídek poznámkového bloku přejděte na Soubor > Zavřít a přerušit. Můžete také spustit libovolný poznámkový blok ve složce s příklady.


Použití poznámkových bloků Apache Zeppelin
Clustery Apache Spark ve službě HDInsight v AKS zahrnují poznámkové bloky Apache Zeppelin . Pomocí poznámkových bloků můžete spouštět úlohy Apache Sparku. V tomto článku se dozvíte, jak používat poznámkový blok Zeppelin ve službě HDInsight v clusteru AKS.
Požadavky
Cluster Apache Spark ve službě HDInsight na AKS. Pokyny najdete v tématu Vytvoření clusteru Apache Spark.
Spuštění poznámkového bloku Apache Zeppelin
Otevřete stránku Přehled clusteru Apache Spark a z nástrojových panelů vyberte poznámkový blok Zeppelin. Zobrazí výzvu k ověření a otevření stránky Zeppelin.
Vytvořte nový poznámkový blok. V podokně záhlaví přejděte do poznámkového bloku > Vytvořit novou poznámku. Ujistěte se, že záhlaví poznámkového bloku zobrazuje stav připojení. Označuje zelenou tečku v pravém horním rohu.
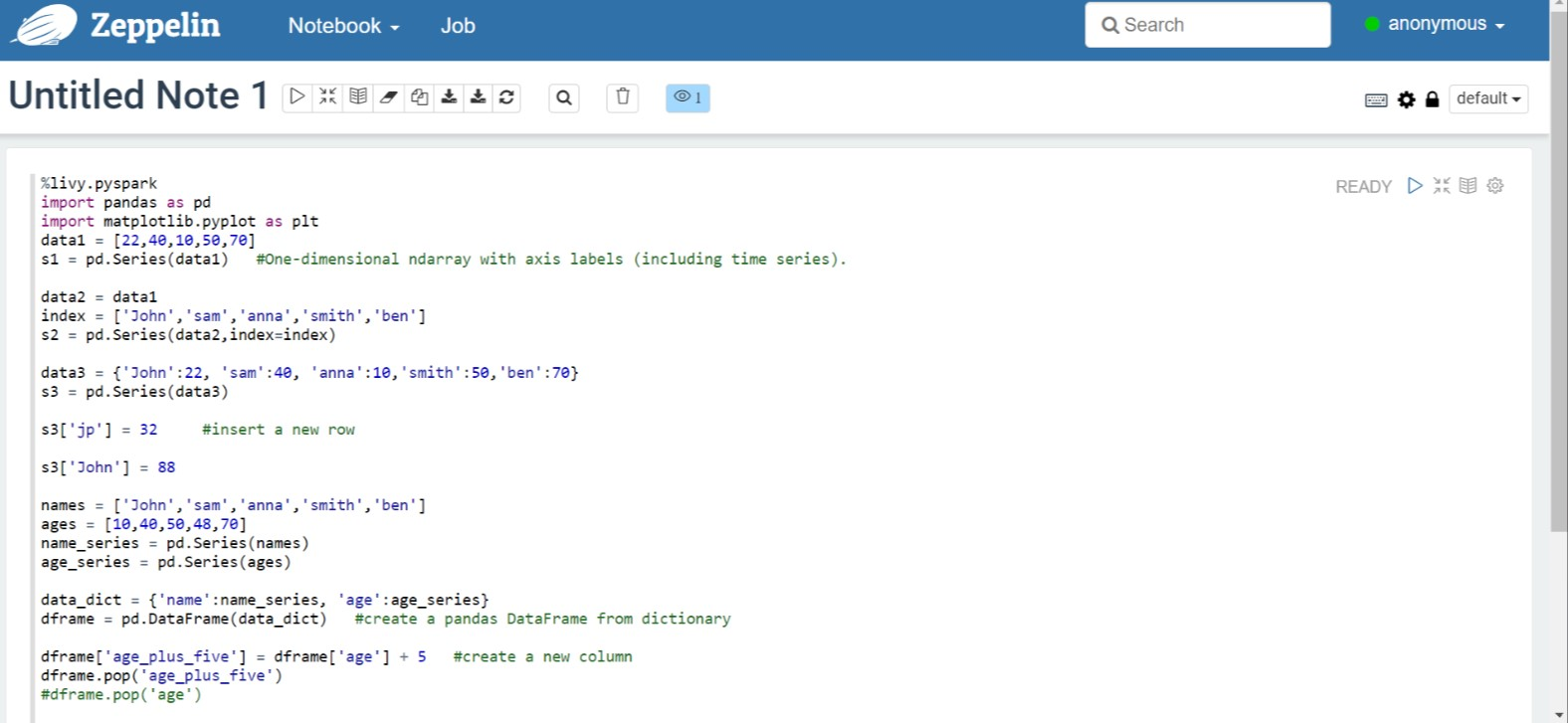
V poznámkovém bloku Zeppelin spusťte následující kód:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Vyberte tlačítko Přehrát odstavce a spusťte fragment kódu. Stav v pravém rohu odstavce by měl postupovat od PŘIPRAVENÝ, ČEKÁ SE, PROBÍHÁ, DOKONČEN. Výstup se zobrazí v dolní části stejného odstavce. Snímek obrazovky vypadá jako na následujícím obrázku:
Výstup:





Používání odesílání úloh ve Sparku
Pomocí následujícího příkazu #vim samplefile.py vytvořte soubor.
Tento příkaz otevře soubor vim.
Do souboru vim vložte následující kód.
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Uložte soubor pomocí následující metody.
- Stiskněte klávesu Escape.
- Zadejte příkaz
:wq
Spuštěním následujícího příkazu spusťte úlohu.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Monitorování dotazů v clusteru Apache Spark ve službě HDInsight v AKS
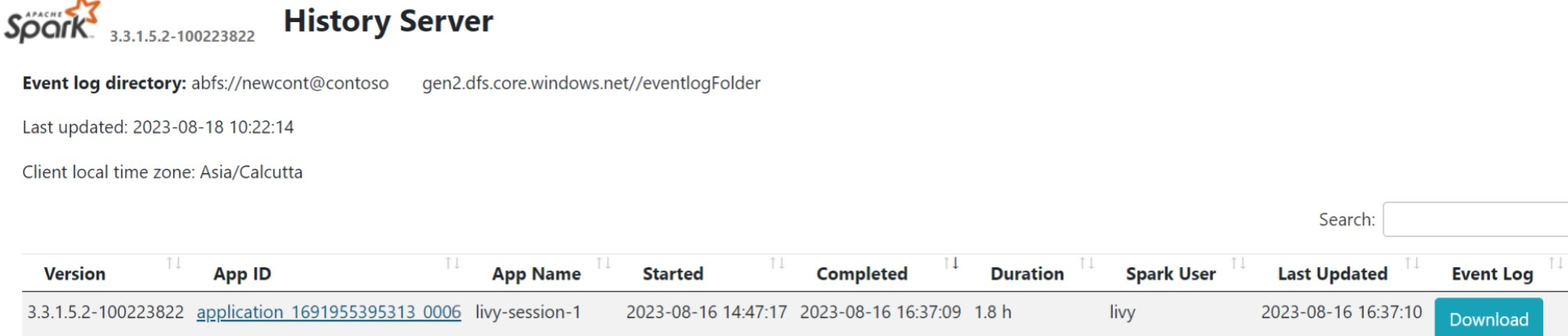
Uživatelské rozhraní historie Sparku
Na kartě Přehled klikněte na uživatelské rozhraní serveru historie Sparku.

Vyberte nedávné spuštění z uživatelského rozhraní pomocí stejného ID aplikace.
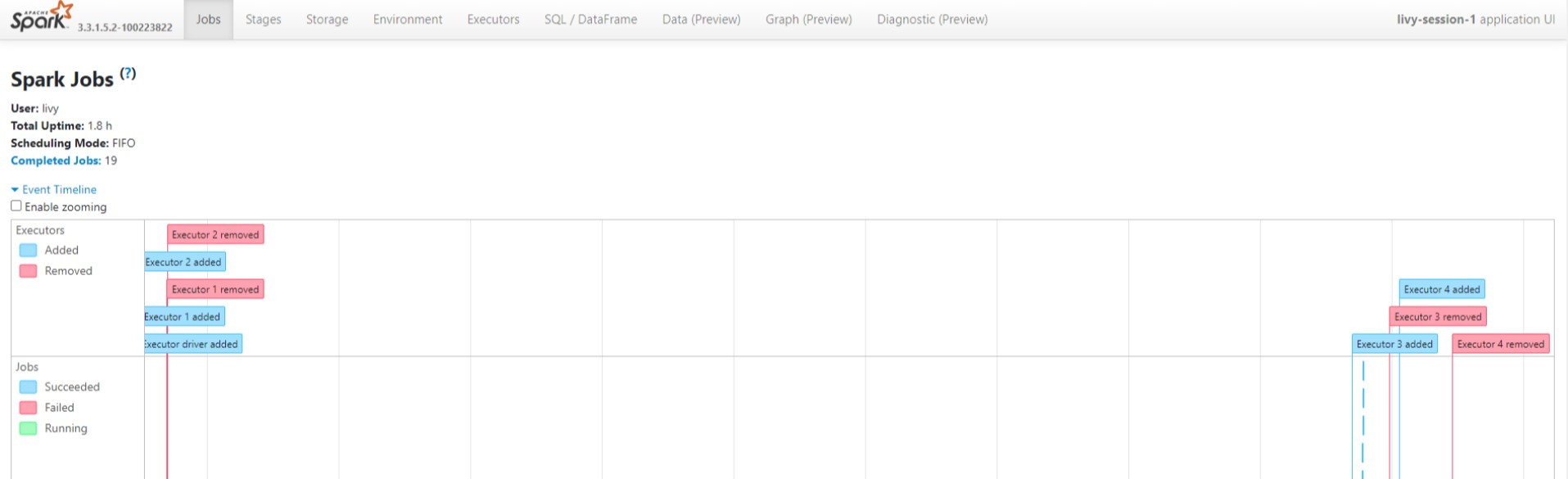
Prohlédněte si cykly a fáze úlohy v acyklickém směrovém grafu v uživatelském rozhraní historie Sparku.



uživatelské rozhraní relace Livy
Pokud chcete otevřít uživatelské rozhraní relace Livy, zadejte do prohlížeče následující příkaz
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui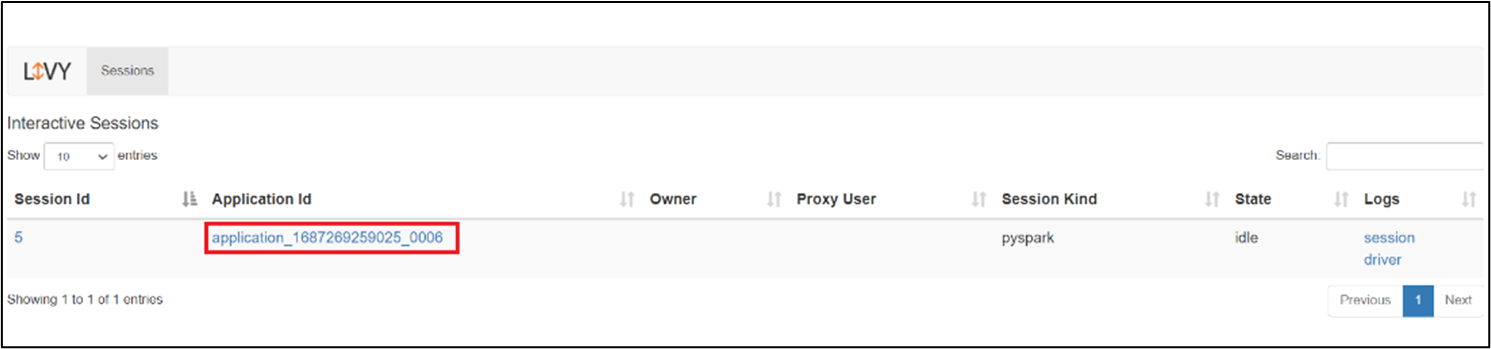
Kliknutím na možnost ovladače v části Protokoly zobrazte protokoly ovladačů.

Yarn uživatelské rozhraní
Na kartě Přehled klikněte na Yarn a otevřete uživatelské rozhraní Yarn.
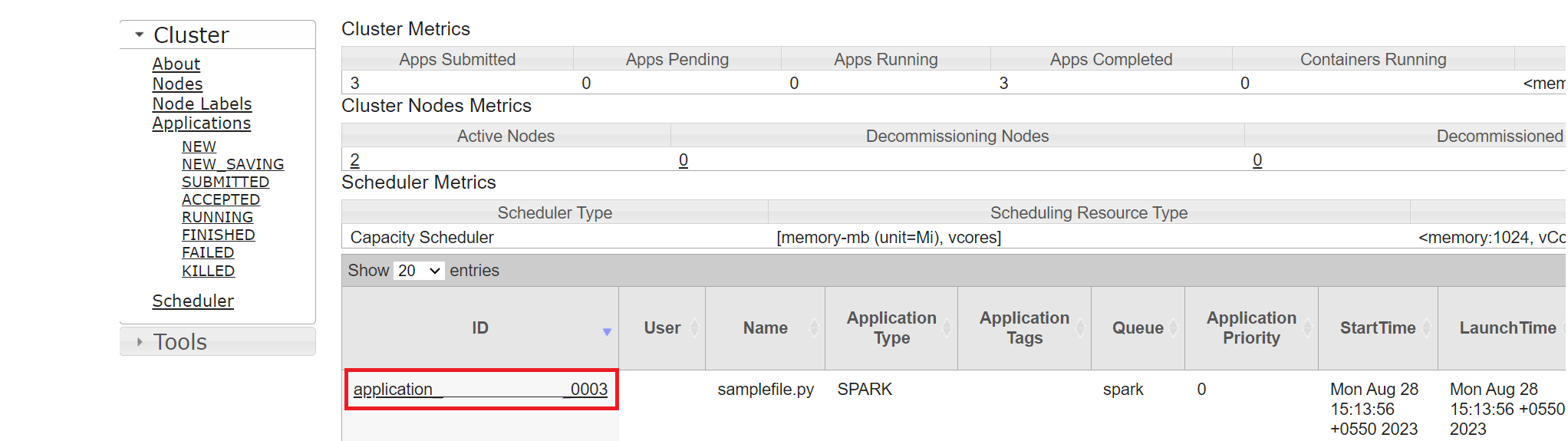
Úlohu, kterou jste nedávno spustili, můžete sledovat podle stejného ID aplikace.
Kliknutím na ID aplikace v Yarn zobrazíte podrobné protokoly úlohy.


Odkaz
- Názvy open-source projektů Apache, Apache Spark, Spark a přidružených open-source projektů jsou ochranné známky nadace Apache Software Foundation (ASF).